全面解讀Python垃圾回收機制
本文轉載自微信公眾號「小菜學編程」,作者fasionchan。轉載本文請聯系小菜學編程公眾號。
Python 內部采用 引用計數法 ,為每個對象維護引用次數,并據此回收不再需要的垃圾對象。由于引用計數法存在重大缺陷,循環引用時有內存泄露風險,因此 Python 還采用 標記清除法 來回收存在循環引用的垃圾對象。此外,為了提高垃圾回收( GC )效率,Python 還引入了 分代回收機制 。
對象跟蹤
將程序內部對象跟蹤起來,是實現垃圾回收的第一步。那么,是不是程序創建的所有對象都需要跟蹤呢?
一個對象是否需要跟蹤,取決于它會不會形成循環引用。按照引用特征,Python 對象可以分為兩類:
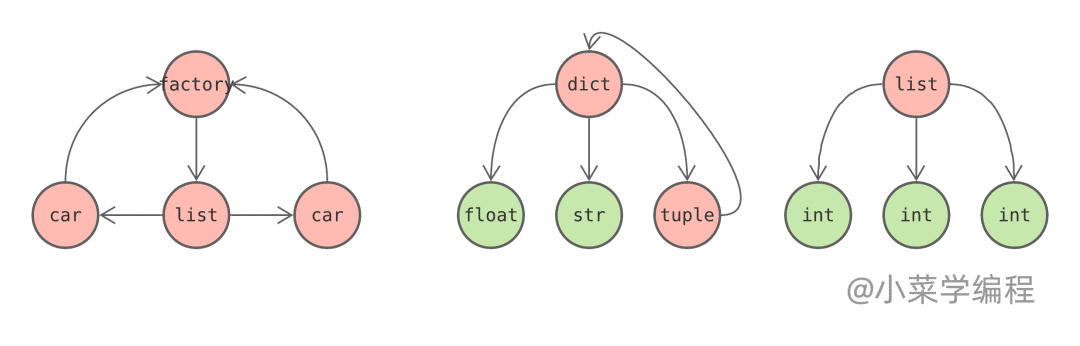
- 內向型對象 ,例如 int 、float 、 str 等,這類對象不會引用其他對象,因此無法形成循環引用,無須跟蹤;
- 外向型對象 ,例如 tuple 、 list 、 dict 等容器對象,以及函數、類實例等復雜對象,這類對象一般都會引用其他對象,存在形成循環引用的風險,因此是垃圾回收算法關注的重點;
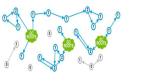
這是一個典型的例子,橘紅色外向型對象存在循環引用的可能性,需要跟蹤;而綠色內向型對象在引用關系圖中只能作為葉子節點存在,無法形成任何環狀,因此無需跟蹤:
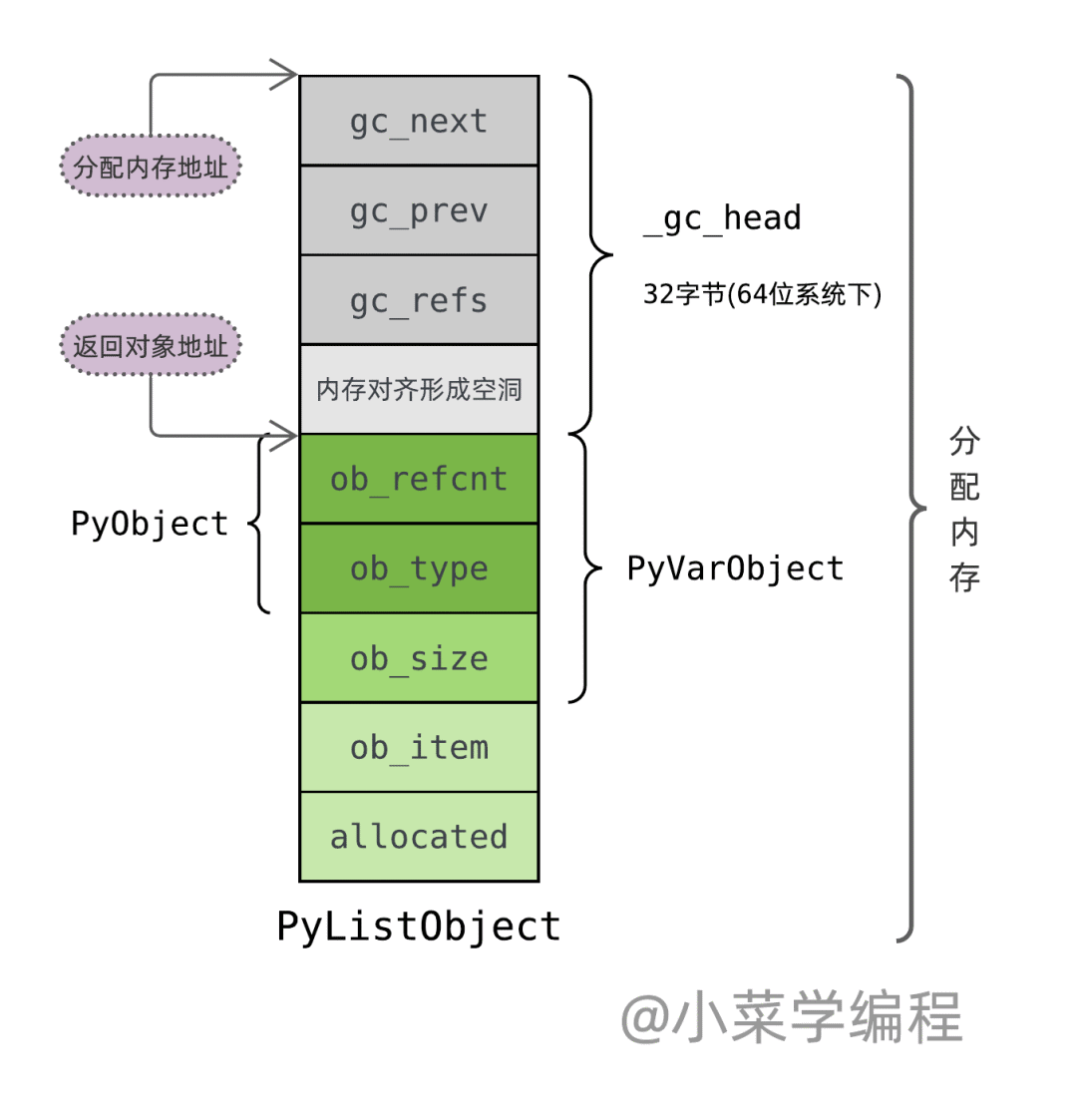
Python 為外向型對象分配內存時,調用位于 Modules/gcmodule.c 源文件的 _PyObject_GC_Alloc 函數。該函數在對象頭部之前預留了一些內存空間,以便垃圾回收模塊用 鏈表 將它們跟蹤起來。預留的內存空間是一個 _gc_head 結構體,它定義于 Include/objimpl.h 頭文件:
- typedef union _gc_head {
- struct {
- union _gc_head *gc_next;
- union _gc_head *gc_prev;
- Py_ssize_t gc_refs;
- } gc;
- long double dummy; /* force worst-case alignment */
- // malloc returns memory block aligned for any built-in types and
- // long double is the largest standard C type.
- // On amd64 linux, long double requires 16 byte alignment.
- // See bpo-27987 for more discussion.
- } PyGC_Head;
- gc_next ,鏈表后向指針,指向后一個被跟蹤的對象;
- gc_prev ,鏈表前向指針,指向前一個被跟蹤的對象;
- gc_refs ,對象引用計數副本,在標記清除算法中使用;
- dummy ,內存對齊用,以 64 位系統為例,確保 _gc_head 結構體大小是 16 字節的整數倍,結構體地址以 16 字節為單位對齊;
以 list 對象為例,_PyObject_GC_Alloc 函數在 PyListObject 結構體基礎上加上 _gc_head 結構體來申請內存,但只返回 PyListObject 的地址作為對象地址,而不是整塊內存的首地址:
就這樣,借助 gc_next 和 gc_prev 指針,Python 將需要跟蹤的對象一個接一個組織成 雙向鏈表 :
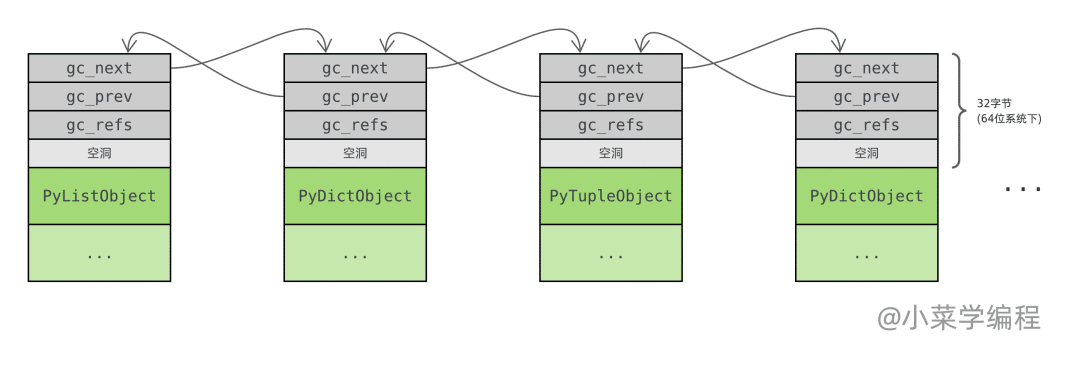
這個鏈表也被稱為 可收集 ( collectable )對象鏈表,Python 將從這個鏈表中收集并回收垃圾對象。
分代回收機制
Python 程序啟動后,內部可能會創建大量對象。如果每次執行標記清除法時,都需要遍歷所有對象,多半會影響程序性能。為此,Python 引入分代回收機制——將對象分為若干“代”( generation ),每次只處理某個代中的對象,因此 GC 卡頓時間更短。
那么,按什么標準劃分對象呢?是否隨機將一個對象劃分到某個代即可呢?答案是否定的。實際上,對象分代里頭也是有不少學問的,好的劃分標準可顯著提升垃圾回收的效率。
考察對象的生命周期,可以發現一個顯著特征:一個對象存活的時間越長,它下一刻被釋放的概率就越低。我們應該也有這樣的親身體會:經常在程序中創建一些臨時對象,用完即刻釋放;而定義為全局變量的對象則極少釋放。
因此,根據對象存活時間,對它們進行劃分就是一個不錯的選擇。對象存活時間越長,它們被釋放的概率越低,可以適當降低回收頻率;相反,對象存活時間越短,它們被釋放的概率越高,可以適當提高回收頻率。
| 對象存活時間 | 釋放概率 | 回收頻率 |
|---|---|---|
| 長 | 低 | 低 |
| 短 | 高 | 高 |
Python 內部根據對象存活時間,將對象分為 3 代(見 Include/internal/mem.h ):
- #define NUM_GENERATIONS 3
每個代都由一個 gc_generation 結構體來維護,它同樣定義于 Include/internal/mem.h 頭文件:
- struct gc_generation {
- PyGC_Head head;
- int threshold; /* collection threshold */
- int count; /* count of allocations or collections of younger
- generations */
- };
- head ,可收集對象鏈表頭部,代中的對象通過該鏈表維護;
- threshold ,僅當 count 超過本閥值時,Python 垃圾回收操作才會掃描本代對象;
- count ,計數器,不同代統計項目不一樣;
Python 虛擬機運行時狀態由 Include/internal/pystate.h 中的 pyruntimestate 結構體表示,它內部有一個 _gc_runtime_state ( Include/internal/mem.h )結構體,保存 GC 狀態信息,包括 3 個對象代。這 3 個代,在 GC 模塊( Modules/gcmodule.c ) _PyGC_Initialize 函數中初始化:
- struct gc_generation generations[NUM_GENERATIONS] = {
- /* PyGC_Head, threshold, count */
- {{{_GEN_HEAD(0), _GEN_HEAD(0), 0}}, 700, 0},
- {{{_GEN_HEAD(1), _GEN_HEAD(1), 0}}, 10, 0},
- {{{_GEN_HEAD(2), _GEN_HEAD(2), 0}}, 10, 0},
- };
為方便討論,我們將這 3 個代分別稱為:初生代、中生代 以及 老生代。當這 3 個代初始化完畢后,對應的 gc_generation 數組大概是這樣的:
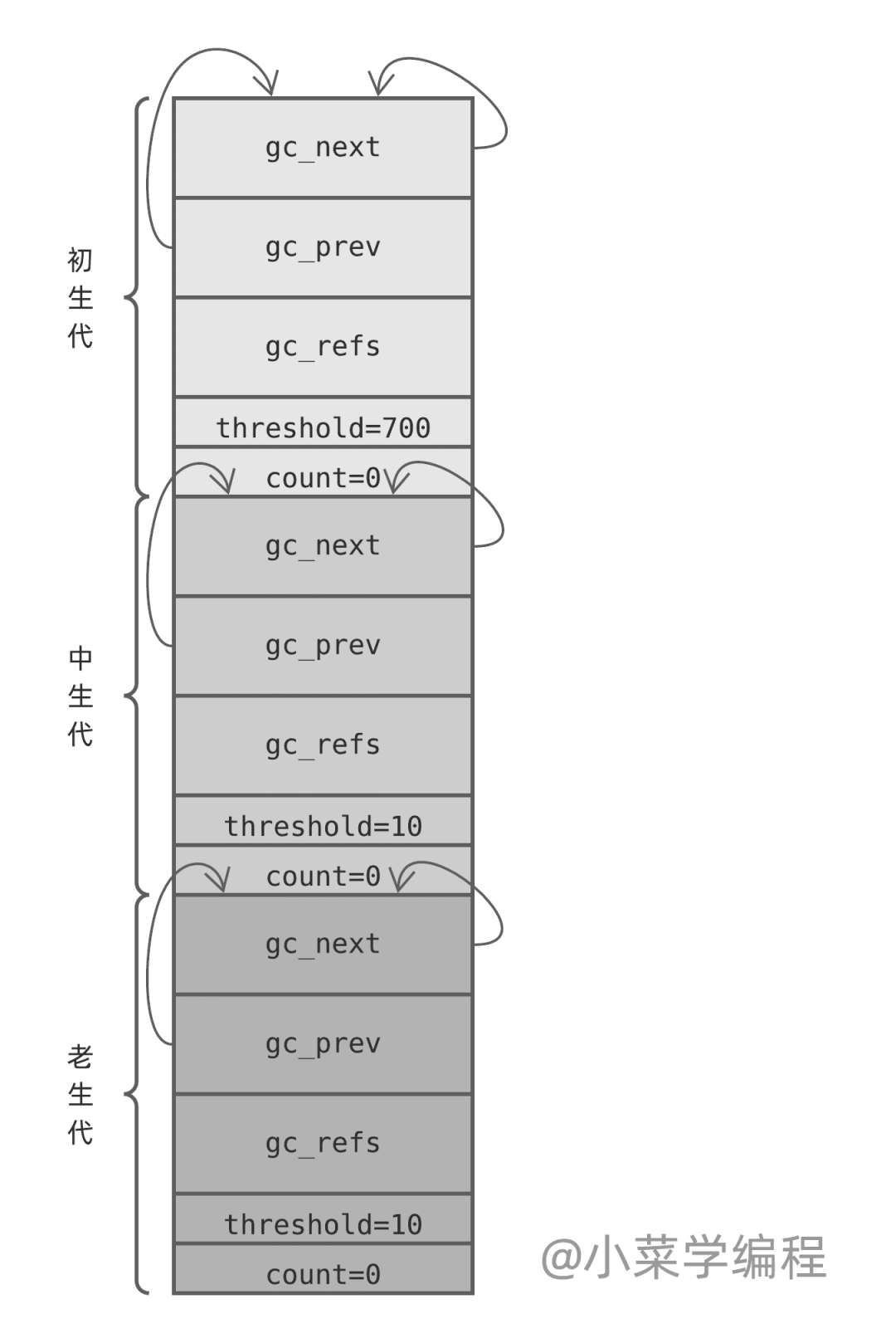
每個 gc_generation 結構體鏈表頭節點都指向自己,換句話說每個可收集對象鏈表一開始都是空的;計數器字段 count 都被初始化為 0 ;而閥值字段 threshold 則有各自的策略。這些策略如何理解呢?
Python 調用 _PyObject_GC_Alloc 為需要跟蹤的對象分配內存時,該函數將初生代 count 計數器加一,隨后對象將接入初生代對象鏈表;當 Python 調用 PyObject_GC_Del 釋放垃圾對象內存時,該函數將初生代 count 計數器減一;_PyObject_GC_Alloc 自增 count 后如果超過閥值( 700 ),將調用 collect_generations 執行一次垃圾回收( GC )。
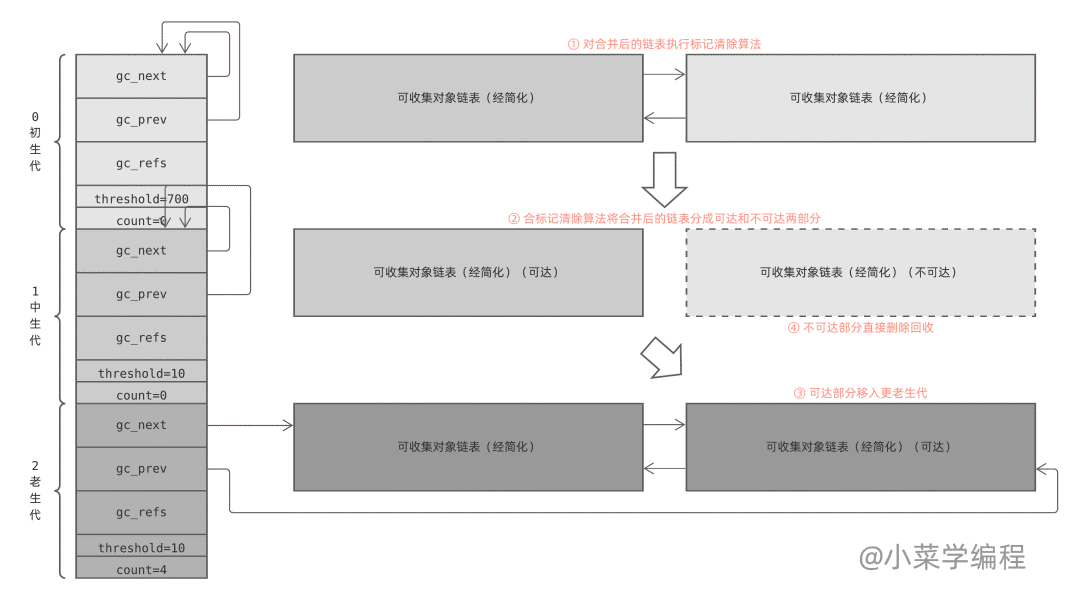
collect_generations 函數從老生代開始,逐個遍歷每個生代,找出需要執行回收操作( count>threshold )的最老生代。隨后調用 collect_with_callback 函數開始回收該生代,而該函數最終調用 collect 函數。
collect 函數處理某個生代時,先將比它年輕的生代計數器 count 重置為 0 ;然后將它們的對象鏈表移除,與自己的拼接在一起后執行 GC 算法(本文后半部分介紹);最后,將下一個生代計數器加一。
- 系統每新增 701 個需要 GC 的對象,Python 就執行一次 GC 操作;
- 每次 GC 操作需要處理的生代可能是不同的,由 count 和 threshold 共同決定;
- 某個生代需要執行 GC ( count>hreshold ),在它前面的所有年輕生代也同時執行 GC ;
- 對多個代執行 GC ,Python 將它們的對象鏈表拼接在一起,一次性處理;
- GC 執行完畢后,count 清零,而后一個生代 count 加一;
下面是一個簡單的例子:初生代觸發 GC 操作,Python 執行 collect_generations 函數。它找出了達到閥值的最老生代是中生代,因此調用 collection_with_callback(1) ,1 是中生代在數組中的下標。
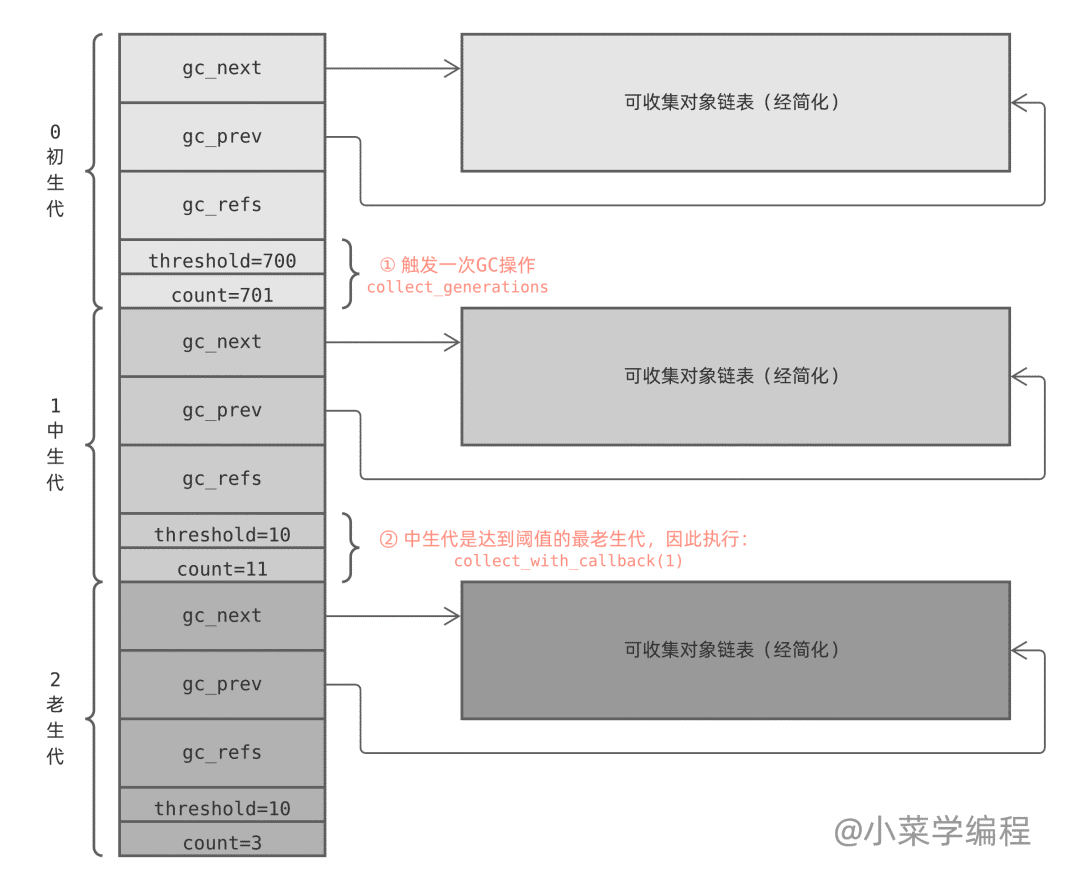
collection_with_callback(1) 最終執調用 collect(1) ,它先將后一個生代計數器加一;然后將本生代以及前面所有年輕生代計數器重置為零;最后調用 gc_list_merge 將這幾個可回收對象鏈表合并在一起:
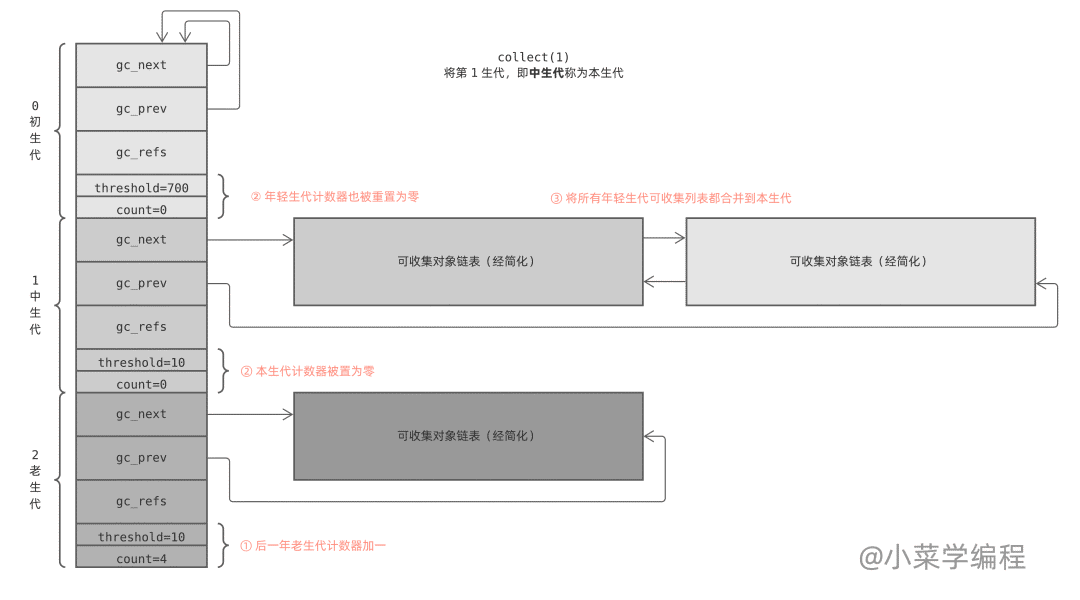
最后,collect 函數執行標記清除算法,對合并后的鏈表進行垃圾回收,具體細節在本文后半部分展開介紹。
這就是分代回收機制的全部秘密,它看似復雜,但只需略加總結就可以得到幾條直白的策略:
- 每新增 701 個需要 GC 的對象,觸發一次新生代 GC ;
- 每執行 11 次新生代 GC ,觸發一次中生代 GC ;
- 每執行 11 次中生代 GC ,觸發一次老生代 GC (老生代 GC 還受其他策略影響,頻率更低);
- 執行某個生代 GC 前,年輕生代對象鏈表也移入該代,一起 GC ;
- 一個對象創建后,隨著時間推移將被逐步移入老生代,回收頻率逐漸降低;
由于篇幅關系,分代回收部分代碼無法逐行解釋,請對照圖示閱讀相關重點函數,應該不難理解。
現在,我們對 Python 垃圾回收機制有了框架上的把握,但對檢測垃圾對象的方法還知之甚少。垃圾對象識別是垃圾回收工作的重中之重,Python 是如何解決這一關鍵問題的呢?