vivo Pulsar 萬億級消息處理實踐(2)-從0到1建設 Pulsar 指標監控鏈路

本文是基于Pulsar 2.9.2/kop-2.9.2展開的。
一、背景
作為一種新型消息中間件,Pulsar在架構設計及功能特性等方面要優于Kafka,所以我們引入Pulsar作為我們新一代的消息中間件。在對Pulsar進行調研的時候(比如:性能測試、故障測試等),針對Pulsar提供一套可觀測系統是必不可少的。Pulsar的指標是面向云原生的,并且官方提供了Prometheus作為Pulsar指標的采集、存儲和查詢的方案,但是使用Prometheus采集指標面臨以下幾個問題:
- Prometheus自帶的時序數據庫不是分布式的,它受單機資源的限制;
- Prometheus 在存儲時序數據時消耗大量的內存,并且Prometheus在實現高效查詢和聚合計算的時候會消耗大量的CPU。
除了以上列出的可觀測系統問題,Pulsar還有一些指標本身的問題,這些問題包括:
- Pulsar的訂閱積壓指標單位是entry而不是條數,這會嚴重影響從Kafka遷移過來的用戶的使用體驗及日常運維工作;
- Pulsar沒有bundle指標,因為Pulsar自動均衡的最小單位是bundle,所以bundle指標是調試Pulsar自動均衡參數時重要的觀測依據;
- kop指標上報異常等問題。
針對以上列出的幾個問題,我們在下面分別展開敘述。
二、Pulsar監控告警系統架構
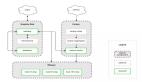
在上一章節我們列出了使用Prometheus作為觀測系統的局限,由于Pulsar的指標是面向云原生的,采用Prometheus采集Pulsar指標是最好的選擇,但對于指標的存儲和查詢我們使用第三方存儲來減輕Prometheus的壓力,整個監控告警系統架構如下圖所示:

在整個可觀測系統中,各組件的職能如下:
- Pulsar、bookkeeper等組件提供暴露指標的接口
- Prometheus訪問Pulsar指標接口采集指標
- adaptor提供了服務發現、Prometheus格式指標的反序列化和序列化以及指標轉發遠端存儲的能力,這里的遠端存儲可以是Pulsar或Kafka
- Druid消費指標topic并提供數據分析的能力
- vivo內部的檢測告警平臺提供了動態配置檢測告警的能力
基于以上監控系統的設計邏輯,我們在具體實現的過程中遇到了幾個比較關鍵的問題:
1、adaptor需要接收Pulsar所有線上服務的指標并兼容Prometheus格式數據,所以在調研Prometheus采集Pulsar指標時,我們基于Prometheus的官方文檔開發了adaptor,在adaptor里實現了服務加入集群的發現機制以及動態配置prometheus采集新新加入服務的指標:
- Prometheus動態加載配置:Prometheus配置-官方文檔
- Prometheus自定義服務發現機制:Prometheus自定義服務發現-官方文檔
在可以動態配置Prometheus采集所有線上正在運行的服務指標之后,由于Prometheus的指標是基于protobuf協議進行傳輸的,并且Prometheus是基于go編寫的,所以為了適配Java版本的adaptor,我們基于Prometheus和go提供的指標格式定義文件(remote.proto、types.proto和gogo.proto)生成了Java版本的指標接收代碼,并將protobuf格式的指標反序列化后寫入消息中間件。
2、Grafana社區提供的Druid插件不能很好的展示Counter類型的指標,但是bookkeeper上報的指標中又有很多是Counter類型的指標,vivo的Druid團隊對該插件做了一些改造,新增了計算速率的聚合函數。
druid插件的安裝可以參考官方文檔(詳情)
3、由于Prometheus比較依賴內存和CPU,而我們的機器資源組又是有限的,在使用遠端存儲的基礎上,我們針對該問題優化了一些Prometheus參數,這些參數包括:
- --storage.tsdb.retentinotallow=30m:該參數配置了數據的保留時間為30分鐘,在這個時間之后,舊的數據將會被刪除。
- --storage.tsdb.min-block-duratinotallow=5m:該參數配置了生成塊(block)的最小時間間隔為5分鐘。塊是一組時序數據的集合,它們通常被一起壓縮和存儲在磁盤上,該參數間接控制Prometheus對內存的占用。
- --storage.tsdb.max-block-duratinotallow=5m:該參數配置了生成塊(block)的最大時間間隔為5分鐘。如果一個塊的時間跨度超過這個參數所設的時間跨度,則這個塊將被分成多個子塊。
- --enable-feature=memory-snapshot-on-shutdown:該參數配置了在Prometheus關閉時,自動將當前內存中的數據快照寫入到磁盤中,Prometheus在下次啟動時讀取該快照從而可以更快的完成啟動。
三、Pulsar 指標優化
Pulsar的指標可以成功觀測之后,我們在日常的調優和運維過程中發現了一些Pulsar指標本身存在的問題,這些問題包括準確性、用戶體驗、以及性能調優等方面,我們針對這些問題做了一些優化和改造,使得Pulsar更加通用、易維護。
3.1 Pulsar消費積壓指標
原生的Pulsar訂閱積壓指標單位是entry,從Kafka遷移到Pulsar的用戶希望Pulsar能夠和Kafka一樣,提供以消息條數為單位的積壓指標,這樣可以方便用戶判斷具體的延遲大小并盡量不改變用戶使用消息中間件的習慣。
在確保配置brokerEntryMetadataInterceptors=org.apache.pulsar.common.intercept.AppendIndexMetadataInterceptor情況下,Pulsar broker端在往bookkeeper端寫入entry前,通過攔截器往entry的頭部添加索引元數據,該索引在同一分區內單調遞增,entry頭部元數據示例如下:
biz-log-partition-1 -l 24622961 -e 6
Batch Message ID: 24622961:6:0
Publish time: 1676917007607
Event time: 0
Broker entry metadata index: 157398560244
Properties:
"X-Pulsar-batch-size 2431"
"X-Pulsar-num-batch-message 50"以分區為指標統計的最小單位,基于last add confirmed entry和last consumed entry計算兩個entry中的索引差值,即是訂閱在每個分區的數據積壓。下面是cursor基于訂閱位置計算訂閱積壓的示意圖,其中last add confirmed entry在攔截器中有記錄最新索引,對于last consumed entry,cursor需要從bookkeeper中讀取,這個操作可能會涉及到bookkeeper讀盤,所以在收集延遲指標的時候可能會增加采集的耗時。

效果
上圖是新訂閱積壓指標和原生積壓指標的對比,新增的訂閱積壓指標單位是條,原生訂閱積壓指標單位是entry。在客戶端指定單條發送100w條消息時,訂閱積壓都有明顯的升高,當客戶端指定批次發送100w條消息的時候,新的訂閱積壓指標會有明顯的升高,而原生訂閱積壓指標相對升高幅度不大,所以新的訂閱積壓指標更具體的體現了訂閱積壓的情況。

3.2 Pulsar bundle指標
Pulsar相比于Kafka增加了自動負載均衡的能力,在Pulsar里topic分區是綁定在bundle上的,而負載均衡的最小單位是bundle,所以我們在調優負載均衡策略和參數的時候比較依賴bunlde的流量分布指標,并且該指標也可以作為我們切分bundle的參考依據。我們在開發bundle指標的時候做了下面兩件事情:
統計當前Pulsar集群非游離狀態bundle的負載情況對于處于游離狀態的bundle(即沒有被分配到任何broker上的bundle),我們指定Pulsar leader在上報自身bundle指標的同時,上報這些處于游離狀態的bundle指標,并打上是否游離的標簽。
效果

上圖就是bundle的負載指標,除了出入流量分布的情況,我們還提供了生產者/消費者到bundle的連接數量,以便運維同學從更多角度來調優負載均衡策略和參數。
3.3 kop消費延遲指標無法上報
在我們實際運維過程中,重啟kop的Coordinator節點后會偶發消費延遲指標下降或者掉0的問題,從druid查看上報的數據,我們發現在重啟broker之后消費組就沒有繼續上報kop消費延遲指標。
(1)原因分析
由于kop的消費延遲指標是由Kafka lag exporter采集的,所以我們重點分析了Kafka lag exporter采集消費延遲指標的邏輯,下圖是Kafka-lag-exporter采集消費延遲指標的示意圖:

其中,kafka-lag-exporter計算消費延遲指標的邏輯會依賴kop的describeConsumerGroups接口,但是當GroupCoordinator節點重啟后,該接口返回的member信息中assignment數據缺失,kafka-lag-exporter會將assignment為空的member給過濾掉,所以最終不會上報對應member下的分區指標,代碼調試如下圖所示:


為什么kop/Kafka describeConsumerGroups接口返回member的assignment是空的?因為consumer在啟動消費時會通過groupManager.storeGroup寫入__consumer_offset,在coordinator關閉時會轉移到另一個broker,但另一個broker并沒有把assignment字段反序列化出來(序列化為groupMetadataValue,反序列化為readGroupMessageValue),如下圖:

(2)解決方案
在GroupMetadataConstants#readGroup-MessageValue()方法對coordinator反序列化消費組元數據信息時,將assignment字段讀出來并設置(序列化為groupMetadataValue,反序列化為readGroupMessageValue),如下圖:

四、總結
在Pulsar監控系統構建的過程中,我們解決了與用戶體驗、運維效率、Pulsar可用性等方面相關的問題,加快了Pulsar在vivo的落地進度。雖然我們在構建Pulsar可觀測系統過程中解決了一部分問題,但是監控鏈路仍然存在單點瓶頸等問題,所以Pulsar在vivo的發展未來還會有很多挑戰。