從0到1剖析并編碼實現短鏈系統
短鏈很常見,在互聯網營銷場景以及移動端信息傳播等場景下起著重要的作用。同時,也是經常被來拿考察選手系統設計水平的一個場景。
對于服務端研發,關于前端訪問時的長短轉換,其實只要知道有30X重定向基本也就可以了。
相較于重定向,我更關注的,是短鏈生成方式選型、存儲選型、系統性能應對等方面的方案和設計。
Part one 短鏈系統分析
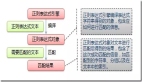
短鏈系統的最根本能力:是可以根據長鏈計算得到短鏈,以方便外部訪問:
- 判斷對應短鏈已存在,則直接返回
- 判斷對應短鏈不存在,則生成短鏈,并存儲 長鏈->短鏈 的映射關系
也可以根據短鏈映射到長鏈,尋找真實服務地址提供服務:
- 根據短鏈->長鏈 查詢存儲,獲取對應的長鏈
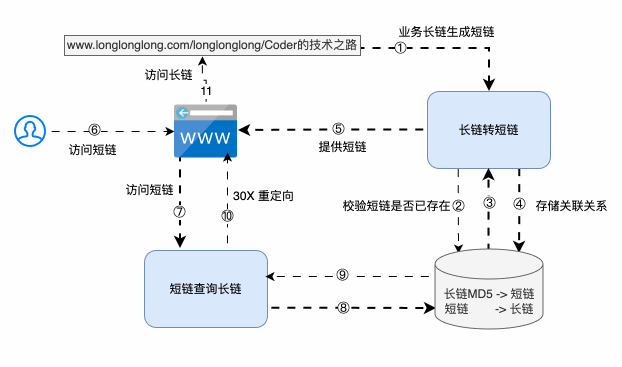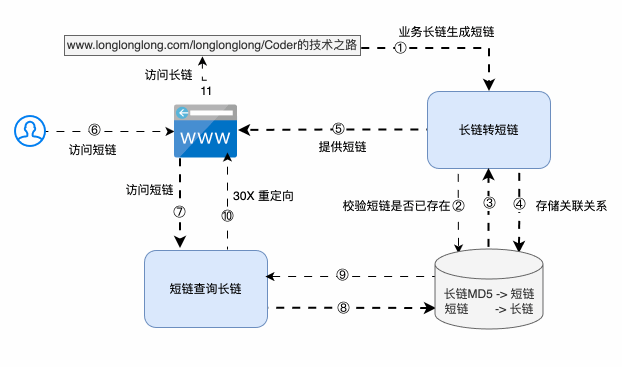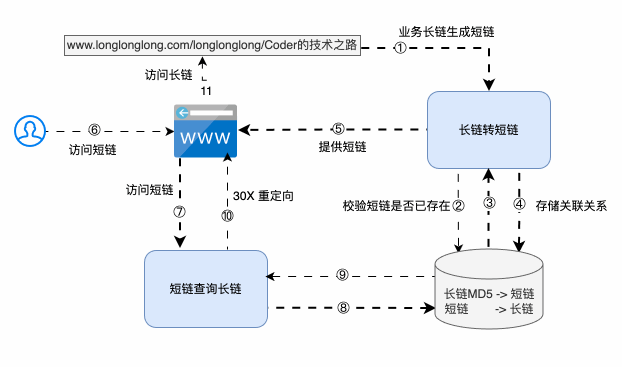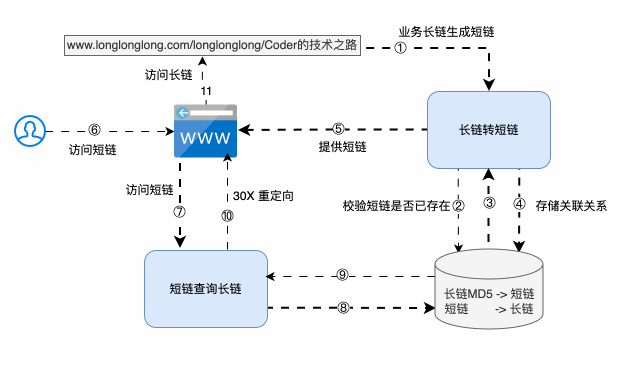
條條大路通羅馬,系統方案有很多,但采取哪種最合適,還需要和存儲策略以及訪問性能聯合起來一起看~
Part two 實現方案分析
Hash是最容易想到的實現策略之一,那么,Hash方式有哪些優缺點,我們又該怎么改進呢?
Hash策略關鍵點解析
首先,如果用hash方式來生成短鏈,那么短鏈是沒法通過hash碼反解出長鏈的,因此,必須存儲短鏈和長鏈的關聯關系;
其次,長鏈的長度一般又很長,不便于索引的構建,需要再生成一個長鏈的固定唯一短串來輔助存儲和查詢。( 如32位MD5壓縮,加密算法一般不利于壓縮,而壓縮算法一般不可逆);
再次,hash難免會有沖突,需要對原始長鏈尾部拼接一個或多個固定串來消除沖突,因此,在訪問長鏈時同樣需要裁剪固定串。
Hash策略的存儲設計
如果用mysql進行結構化存儲比較簡單:
id | 短鏈 | 長鏈MD5 | 長鏈 | 時間戳
并且需要給 短鏈 和 長鏈MD5 構建索引,供查詢時使用。
- 優點是結構化查詢、結構清晰,可以設置索引提升效率;
- 缺點是高并發下性能需要額外關注,保存的數據要過期,理論上得進行額外處理;
如果用redis等非結構化kv存儲,則需要存儲多個關系用于查詢:
長鏈MD5 -> 短鏈 |
短鏈 -> 長鏈MD5 |
長鏈MD5 -> 長鏈
- 優點是查詢性能高,可以抗量,且自帶過期機制;
- 缺點是需要維護多個KV關系,稍顯繁瑣。
改進-- 自增ID+高位進制法
如果說長鏈的MD5標識的生成和存儲是不可缺少的,那么,可優化的點,就只能從短鏈 -> 長鏈MD5的轉化這里來下手了。
有沒有辦法既可以省掉短鏈 -> 長鏈MD5的存儲呢?
如果我們讓唯一標識和短鏈之間可以通過計算相互編碼解碼,是不是就可以了!?既省了一部分存儲,而且也省掉了查詢存儲的時間耗時,本地簡單計算總歸要比查詢外部存儲要快的多。
經常使用進制轉換,可以知道,進制越高所占位數越少。

 16進制轉換示例
16進制轉換示例
這個時候,用MD5應該就不太合適了,不好參與計算,因此,我們改用純數字的分布式ID來代替MD5串(一般公司應該都有現成的分布式ID生成服務吧)。
利用進制轉換雖然可以很方便編碼成短鏈,但有時候,我們不希望出現 短鏈被輕松解碼,導致服務端可被遍歷,因此,需要考慮對進制轉換進行加密處理。
編碼實現帶加密的進制轉換
首先,需要選擇高位進制:我們啟用 0-9 a-z A-Z 全部的數字和字母,一共62位,即支持62進制轉換
private static final String DIGITAL_STRING = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ";
//byte數組
private static final byte[] DIGITAL;
static {
DIGITAL = DIGITAL_STRING.getBytes(StandardCharsets.US_ASCII);
}
從10進制向62進制轉換的編碼實現:
public static String encode(long 分布式id) {
//內部復制
long value = id;
//創建短鏈所需長度的空間,這里可以限制短鏈長度為最多12位,最少6位
ByteBuffer buf = ByteBuffer.allocate(12);
//最多執行12次轉換
for (int i = 0; i < 12; i++) {
//分布式ID對62取模
int mod = (int) (value % 62);
//加密, 再取模
int pos = (mod + (OFFSET << i)) % 62;
//根據模值從數組中獲取對應的值,加入結果集中
buf.put(DIGITAL[pos]);
//求余數,用余數繼續參加后續模操作,直到余數為0 或 短鏈長度達到要求
value = value / 62;
if (value==0 && i >= 6) {
break;
}
}
//從ByteBuffer中獲取結果集合
byte[] result=new byte[buf.position()];
buf.rewind();
buf.get(result);
//反轉順序
ArrayUtils.reverse(result);
return new String(result);
}
重點關注(mod + (OFFSET << i)) % 62 這個操作,其目的是在模值上加上一個偏移量(偏移大小和所處位置有關,非固定偏移) ,用來防止被直接解碼。
//將短鏈串解碼為分布式ID
public static long decode(String code) {
long value = 0;
byte[] buf = code.getBytes();
int length = buf.length;
//循環次數為短鏈字符串長度
for (int i = 0; i < length; i++) {
byte digital = buf[i];
//當前字符對應的下標
int index = Arrays.binarySearch(DIGITAL, digital);
//當前下標需要減掉加密時增加的部分(同樣和所處位置有關)
index = index - (OFFSET << (length - i - 1));
//因為減掉的有可能是一個非常大的值,再把index對62取余,如果任然小于0 ,就加上62(62進制內負變正)
index = index % 62;
if (index < 0) {
index = index + 62;
}
//10進制復原原值
value = value * 62 + index;
}
return value;
}
Part three 總結
每一種技術方案,都是通過不斷論證和嘗試才可以最終決定的。我們在學習一個技術架構時,最好可以從它的發展歷程,每個瓶頸點的解決來進行整體把握,會對我們處理問題時候的入手角度和思考方式的鍛煉起到很好的作用。
本文轉載自微信公眾號「Coder的技術之路」,可以通過以下二維碼關注。轉載本文請聯系Coder的技術之路公眾號。