谷歌云服務(wù)大規(guī)模中斷事件溯源,API 管理系統(tǒng)故障引發(fā)全球癱瘓
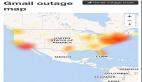
2025年6月12日,谷歌云(Google Cloud)遭遇近年來最嚴(yán)重的服務(wù)中斷事件,其API管理系統(tǒng)出現(xiàn)關(guān)鍵故障,導(dǎo)致全球數(shù)十項服務(wù)癱瘓長達(dá)七小時。此次事故源于服務(wù)控制(Service Control)二進(jìn)制文件中出現(xiàn)的空指針異常,該組件負(fù)責(zé)管理API授權(quán)和配額策略,影響范圍覆蓋谷歌云平臺(GCP)和Google Workspace產(chǎn)品的數(shù)百萬用戶。

二進(jìn)制文件崩潰引發(fā)全球故障
故障根源在于谷歌的服務(wù)控制系統(tǒng)——這個區(qū)域性服務(wù)負(fù)責(zé)在基礎(chǔ)設(shè)施中授權(quán)API請求并執(zhí)行配額策略。2025年5月29日,工程師部署了新增配額策略檢查功能,但相關(guān)代碼既缺乏完善的錯誤處理機制,也未啟用功能標(biāo)志(feature flag)保護(hù)。
危機爆發(fā)的直接原因是:包含意外空白字段的策略變更被寫入服務(wù)控制系統(tǒng)依賴的區(qū)域性Spanner數(shù)據(jù)庫表。由于配額管理具有全球同步特性,這些損壞的元數(shù)據(jù)在幾秒內(nèi)就完成了全球復(fù)制。當(dāng)服務(wù)控制系統(tǒng)嘗試處理這些空白字段時,觸發(fā)了未受保護(hù)的代碼路徑,導(dǎo)致空指針異常,最終引發(fā)所有區(qū)域二進(jìn)制文件同時進(jìn)入崩潰循環(huán)狀態(tài)。
"本次變更的根本問題在于既沒有配置適當(dāng)?shù)腻e誤處理機制,也沒有啟用功能標(biāo)志保護(hù)。由于缺乏錯誤處理,空指針直接導(dǎo)致二進(jìn)制文件崩潰。"谷歌在事故報告中解釋道。
網(wǎng)站可靠性工程(SRE)團(tuán)隊在10分鐘內(nèi)定位到根本原因,并在40分鐘內(nèi)部署了"紅色按鈕"緊急終止開關(guān),關(guān)閉問題服務(wù)路徑。雖然大部分區(qū)域在兩小時內(nèi)恢復(fù),但us-central1區(qū)域卻遭遇持續(xù)性問題——當(dāng)服務(wù)控制任務(wù)在這個主要區(qū)域重啟時,對底層Spanner基礎(chǔ)設(shè)施形成"羊群效應(yīng)",海量并發(fā)請求導(dǎo)致數(shù)據(jù)庫不堪重負(fù)。
工程師發(fā)現(xiàn)服務(wù)控制系統(tǒng)缺乏預(yù)防級聯(lián)故障的隨機指數(shù)退避機制。谷歌不得不限制任務(wù)創(chuàng)建,并將流量路由至多區(qū)域數(shù)據(jù)庫以減輕過載基礎(chǔ)設(shè)施的壓力。這一延長恢復(fù)過程影響了包括谷歌計算引擎(Compute Engine)、BigQuery、云存儲(Cloud Storage)在內(nèi)的核心服務(wù),這些產(chǎn)品構(gòu)成眾多企業(yè)數(shù)字業(yè)務(wù)的基石。
整改措施
針對此次大規(guī)模服務(wù)中斷,谷歌制定了全面整改方案:
- 立即凍結(jié)服務(wù)控制堆棧的所有變更和手動策略推送,直至系統(tǒng)完全修復(fù)
- 對服務(wù)控制架構(gòu)進(jìn)行模塊化改造,確保在個別檢查失敗時仍能保持API請求處理能力(故障開放而非關(guān)閉)
- 全面審計所有使用全局復(fù)制數(shù)據(jù)的系統(tǒng)
- 強制要求所有關(guān)鍵二進(jìn)制變更必須啟用功能標(biāo)志保護(hù)
受影響服務(wù)超過60項,涵蓋Gmail、Google Drive、Google Meet、App Engine、云函數(shù)(Cloud Functions)和Vertex AI等產(chǎn)品。谷歌強調(diào)現(xiàn)有流媒體和基礎(chǔ)設(shè)施即服務(wù)(IaaS)資源仍保持運行,但客戶在整個中斷期間遭遇API和用戶界面間歇性訪問問題。