緩存穿透、緩存擊穿、緩存雪崩,這樣回答要滿分呀!
前言
大家好,我是田螺。
緩存穿透、緩存擊穿、緩存雪崩是經典的老八股文啦,之前去面試一個銀行,就被問到啦,本文跟大家聊聊怎么回答哈~~
1.緩存穿透問題
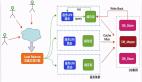
先來看一個常見的緩存使用方式:
讀請求來了,先查下緩存,緩存有值命中,就直接返回;緩存沒命中,就去查數據庫,然后把數據庫的值更新到緩存,再返回。
 圖片
圖片
1.1 什么是緩存穿透問題
緩存穿透:指查詢一個一定不存在的數據,由于緩存是不命中時需要從數據庫查詢,查不到數據則不寫入緩存,這將導致這個不存在的數據每次請求都要到數據庫去查詢,進而給數據庫帶來壓力。
通俗點說,讀請求訪問時,緩存和數據庫都沒有某個值,這樣就會導致每次對這個值的查詢請求都會穿透到數據庫,這就是緩存穿透。
1.2 緩存穿透產生原因
緩存穿透一般都是這幾種情況產生的:
- 業務邏輯設計不合理:比如大多數用戶都沒開守護,但是你的每個請求都去查詢緩存,查詢某個userid有沒有開守護~
- 黑客非法請求攻擊:比如黑客故意捏造大量非法請求,以讀取不存在的業務數據。
- 數據生命周期管理問題:某些數據被刪除后,緩存沒有及時更新,導致后續查詢穿透。
如何避免緩存穿透呢? 一般有三種方法。
- 用戶請求進行有效性檢查:它的核心思想是對請求參數進行合法性校驗,提前過濾掉明顯無效的請求。(主要包括數據格式校驗、數據范圍校驗、權限校驗等等)
- 緩存空值:如果查詢數據庫為空,我們可以給緩存設置個空值,或者一個特殊標記的默認值,設置一個較短的過期時間,避免頻繁訪問數據庫。(業務上比較常用,簡單有效)
- 使用布隆過濾器:快速判斷數據是否存在。即一個查詢請求過來時,先通過布隆過濾器判斷值是否存在,存在才繼續往下查。如果不存在,就不訪問數據庫啦~~
 圖片
圖片
布隆過濾器原理:它由初始值為0的位圖數組和N個哈希函數組成。一個對一個key進行N個hash算法獲取N個值,在比特數組中將這N個值散列后設定為1,然后查的時候如果特定的這幾個位置都為1,那么布隆過濾器判斷該key存在,否則不存在。
2.緩存雪崩問題
緩存雪崩:在某個時間點,大量緩存數據同時過期, 導致大量請求直接訪問數據庫,引起數據庫壓力過大甚至down機。
2.1 緩存雪崩常見原因:
- 緩存設置了集中的過期時間:大量緩存數據設置了相同或者相似的過期時間,導致它們在同一時間段內集體過期。
- 緩存預熱不充分:系統啟動時緩存數據加載不充分,導致大量請求直接訪問數據庫。
- 緩存服務器宕機:redis集群中,多個節點同時宕機,導致大量緩存數據不可用
常見一些經典場景:促銷活動結束(大量商品緩存同時失效)、或者定時任務觸發(比如凌晨批量更新緩存,固定過期時間觸發雪崩)
2.2 如何解決緩存雪崩的問題
通過分散過期時間,是解決緩存雪崩最簡單有效的解決方案~~
可通過均勻設置過期時間解決,即讓過期時間相對離散一點。如采用一個較大固定值+一個較小的隨機值,1小時+0到100秒醬紫。
Redis 故障宕機也可能引起緩存雪奔。這就需要構造Redis高可用集群啦。比如redis主從、哨兵模式、集群模式(Redis cluster)。
當然,還有最后的防線,就是限流和降級~~
3. 緩存擊穿問題
緩存擊穿是指某個熱點數據在緩存中過期的同時,大量并發請求訪問該數據,導致這些請求直接訪問數據庫,造成數據庫壓力驟增。
緩存擊穿看著跟緩存雪崩有點像,其實它兩區別是:
- 緩存擊穿針對單個熱點 Key,緩存雪崩針對大量Key或整個緩存服務
- 影響結果不一樣,緩存擊穿導致數據庫短期壓力劇增;緩存雪崩則可能導致數據庫被壓垮
3.1 緩存擊穿常見原因
- 高并發場景,比如秒殺活動呀,熱點新聞等
- 管理員手動誤清除:運維人員誤刪或主動清理某個熱點Key(如商品價格調整),刪除后突發流量訪問。
3.2 緩存擊穿的解決方案
常見的解決方案:
- 使用互斥鎖方案。緩存失效時,不是立即去加載db數據,而是先使用某些帶成功返回的原子操作命令,如(Redis的setnx)去操作,成功的時候,再去加載db數據庫數據和設置緩存。否則就去重試獲取緩存。
- “永不過期”,是指沒有設置過期時間,但是熱點數據快要過期時,異步線程去更新和設置過期時間。
- 隨機過期時間,通過為熱點數據設置略有差異的過期時間,避免大量熱點數據同時失效