學習python處理python編碼
概括、從python1.6開始就可以處理unicode字符了。
一、幾種常見的編碼格式。
1.1、ascii,用1個字節表示。
1.2、UTF-8,用1個至三個字節表示,表示ascii碼時只占用1個字節,ascii編碼是UTF-8的子集。
1.3、UTF-16,用2個字節表示,在python中,unicode的含義就是UTF-16。
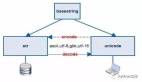
二、python源文件的編碼與解碼,我們寫的python程序從產生到執行的過程如下:
編輯器---->源代碼---->解釋器---->輸出結果
2.1、編輯器決定源代碼的編碼格式(在編輯器中設定)
2.2、也必須要解釋器知道源代碼的編碼格式(很遺憾很難從編碼的數據獲知源文件的編碼格式)
2.3、補充:在Windows下當用UltraEdit把源代碼存成UTF-8時,會在文件中記錄BOM標志(不必祥究)這樣ActivePython解釋器會自動識別源文件是UTF-8格式,但是如果用eclipse編輯源文件,雖然在編輯器中指定文件編碼為UTF-8,但是因為沒有記入BOM標志,所以必須在源文件開始處加上#coding=utf-8,用注釋來提示解釋器源文件的編碼方式挺有意思。
2.4、舉例:例如我們要向終端輸出"我是中國人"。
- #coding=utf-8 告訴python解釋器用的是utf-8編碼,我用的是eclipse+pydev
- print "我是中國人" #源文件本身也要存成UTF-8編碼
三、編碼的轉換,兩種編碼的轉換要用UTF-16作為中轉站。
舉例:如果有一個文本文件jap.txt,里面有內容 "私は中國人です。",編碼格式是日文編碼SHIFT_JIS,
還有一個文本文件chn.txt,內容是"中華人民共和國",編碼格式是中文編碼GB2312。
我們如何把兩個文件里的內容合并到一起并存儲到utf.txt中并且不顯示亂碼呢,可以采用把兩個文件的內容都轉成UTF-8格式,因為UTF-8里包含了中文編碼和日文編碼。
- #coding=utf-8
- try:
- JAP=open("e:/jap.txt","r")
- CHN=open("e:/chn.txt","r")
- UTF=open("e:/utf.txt","w")
- jap_text=JAP.readline()
- chn_text=CHN.readline()
- #先decode成UTF-16,再encode成UTF-8
- jap_text_utf8=jap_text.decode("SHIFT_JIS").encode("UTF-8") #不轉成utf-8也可以
- chn_text_utf8=chn_text.decode("GB2312").encode("UTF-8")#編碼方式大小寫都行utf-8也一樣
- UTF.write(jap_text_utf8)
- UTF.write(chn_text_utf8)
- except IOError,e:
- print "open file error",e
四、Tk庫支持ascii,UTF-16,UTF-8
- #coding=utf-8
- from Tkinter import *
- try:
- JAP=open("e:/jap.txt","r")
- str1=JAP.readline()
- except IOError,e:
- print "open file error",e
- root=Tk()
- label1=Label(root,text=str1.decode("SHIFT_JIS")) #如果沒有decode則顯示亂碼
- label1.grid()
- root.mainloop()
以上是學習python處理python編碼的基本過程,希望對大家有幫助。
【編輯推薦】
- Python 3.2 alpha 2發布 改善單元模塊
- 全能選手 看看Python應乎潮流的72變
- Python自動單元測試框架的應用詳解
- Perl Unicode全程攻略
- Python unicode ascii編碼在windows中的實際應用
- Python unicode ascii編碼在windows上的問題的解決