擴展MapReduce架構的一種嘗試
假設有這樣一個游戲,一個人來出加減乘除的題目給很多小朋友來做,對每一個小朋友,給他出一道題目,然后讓他算好后給你報告答案,你再給他出一道題目,周而復始如此。如果有十個小朋友在算,還可以欣賞小朋友抓耳撓腮的樣子;如果有一百個小朋友,每個人都在爭著表現,叫嚷著讓出題,這個人肯定不堪重負;如果有成千上萬個小朋友呢?這個人瘋了。
面對這樣的場景,學生時的經驗是不斷地改進和優化算法;而工作以后的經驗是再拽的算法也難以抵擋海量的數據或任務,主要還是增加資源,其次才是優化算法,兩者可并行。小朋友越多,相應地增加出題人的數量,也可以緩解每個人的壓力。
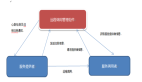
與這種場景類似,MapReduce框架也面臨類似的問題。如下圖:
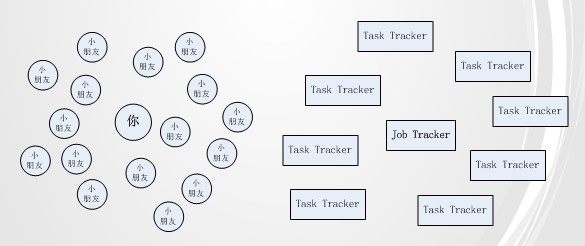
越來越多的task tracker會讓job tracker很有壓力,以至于task tracker有很多時,job tracker不能及時響應請求,很多task tracker就空閑著資源,等待job tracker的response。Job tracker的壓力與task tracker的資源浪費問題導致整個集群難于擴展,對外提供服務的能力也相當下降很多。當前Yahoo也受此困擾,正醞釀重構MapReduce架構。我沒從這個架構看出對現有問題的改善之處,所以自己來試著分析下解決方法。
回頭來看模擬場景,如果把小朋友按班分,每個班都有一位老師。每位老師從出題人那里得到很多題目,然后讓自己班的小朋友來做。這樣,出題人的壓力在于老師的數量,老師的壓力在于班里小朋友的數量。以前小朋友數量增加帶給出題人的壓力,現在分攤到老師就會成倍地減少。與之前相比,不同處在于引入了老師這個角色。
如果以同樣方式解決MapReduce問題,那“老師”的角色應該由誰來扮演呢?MapReduce的初衷之一是“盡量移動計算而不是數據”。假如數據存放于HDFS這樣的文件系統上,移動數據的成本在于機器之間的帶寬限制,由此HDFS網絡拓撲結構表示機器之間數據移動的等級。MapReduce的map task會去訪問HDFS的存儲block,如果block在機器本地或是與task tracker 在同一rack內,對執行沒有太大影響,否則集群帶寬會嚴重影響task執行效率。
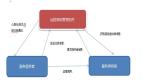
從上述描述來看,影響task執行的***網絡拓撲范圍是rack。一般來說,Rack間的網絡帶寬肯定要比rack內的帶寬小。那我們就以rack來作為“老師”的角色。以此假設,我們在每個rack內將某臺機器設為secondary job tracker,負責rack內task資源的調度與分發單位。結構圖如下:
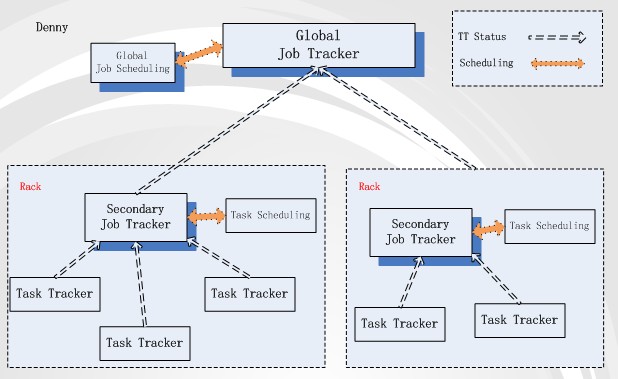
這個結構有兩種job tracker:Global job tracker與Secondary job tracker。Global JT負責跨rack的task分發與調度。基本task分配策略是根據job輸入數據的block存儲情況,只分配block在當前rack內的map task到rack上,分配reduce task 到 map task多的rack上。Secondary JT與Global JT保持著心跳,它管理的map task操作數據要么是node-local,要么是rack-local cache 級別,不會再有map task跨rack取數據的場景,所以分發策略就很簡單了。
在這個結構下,client提交job的流程就變成:1. Client上傳job相關的輸入數據到HDFS上,HDFS會將block幅本存放與不同的data node上,這些data node有在同一個rack內,也有跨rack存在的。2. job提交到Global JT后,根據block存儲情況(在哪些rack上存在block就往哪些rack的Secondary JT發送map task,且根據rack上map task的多少來分發reduce task)。3. Secondary JT向Global JT匯報當前rack內的資源情況,得到那些自己rack內的task。4. Secondary JT響應本rack內的TT 心跳,然后分配適合的task來執行。
以rack劃分MapReduce架構,也是考慮到HDFS與網絡帶寬情況的結果。如果每個rack內有15到20臺機器,10000臺機器差不多可以分布到七八百rack內。Global JT與Secondary JT的并發壓力都不大。這樣的垂直擴展只是暫時解決了部分問題,但沒有從根本上解決job分配程序的壓力。
上述只是我的個人想法,希望得到各位的指正及建議,謝謝!
【編輯推薦】