













借助微軟Cloud Numerics分析“大數據”
譯文許多企業正在迅速采用Apache Hadoop和MapReduce,作為自己主要的數據分析工具。盡管嚴重缺少擁有建立Hadoop分布式文件系統集群(HDFS)或者為MapReduce任務編寫Java代碼所需開發運營(DevOps)技能的數據分析師,但這些企業還是在采用Apache Hadoop和MapReduce分析大數據。
亞馬遜網絡服務公司(AWS)確實提供托管版的彈性MapReduce(EMR),微軟則推廣在Windows Azure基于云實施的MapReduce、Hive、Pig和Mahout上的Apache Hadoop。盡管這些產品消除了內部部署型HDFS存儲區域網(SAN)的資本和管理成本,但是把Hadoop集群轉移到云端并不減少對一大批MapReduce工具的需要。
分析師們可以利用SQL的Apache HiveQL語言,把使用count()、sum()、avg()和stddev_pop()等內置函數的聚集查詢轉換成MapReduce任務。Apache Pig子項目的說明文檔聲稱,當你使用Pig Latin語言時:
很容易對簡單的、“易并行”的數據分析任務實現并行執行。由多個關聯數據轉換組成的復雜任務被顯式編碼成數據流序列,因而使得它們易于編寫、理解和維護。
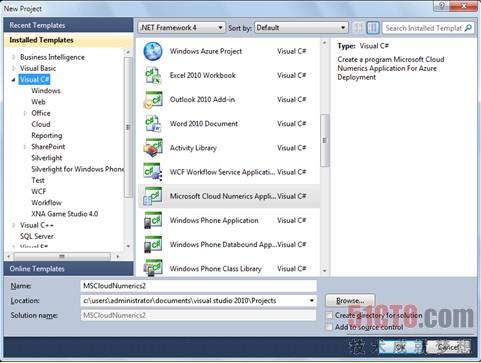
圖1:使用微軟Cloud Numerics Application C#模板,建立一個新的Visual Studio Cloud Numerics部署方案。
但是Pig Latin是個v0.9.2版本,這方面的專家語法學家甚至比MapReduce方面的還要少。所以,缺少開發運營技能的企業IT部門試圖分析云端的“大數據”時,該如何是好?微軟代號為“Cloud Numerics”的解決方案是個切實可行的辦法。
面向C#編程人員的微軟Cloud Numerics
微軟在2012年1月發布了代號為“Cloud Numerics”Lab的解決方案,它提供了除Hadoop、HDFS、MapReduce、HiveQL或Pig Latin之外的一種選擇,可用于分析大數據。Cloud Numerics為精通C#、習慣使用Visual Studio的企業級.NET編程人員提供了下列特性:
•把開發分布式算法的復雜性隱藏起來的一種編程模型
•可訪問由數值算法組成的.NET庫,這些數值算法涵蓋基本算術、高級統計和線性代數等。
•把應用程序部署到Windows Azure,并使用云環境計算能力的功能。
利用Cloud Numerics高性能計算(HPC)集群進行并行處理需要分析師輸入數據,這些數據具體表現為分布式密集數組(主要是數值數據)或矩陣。密集數組對應于所有列中都是非零值的表,而不是像稀疏數據那樣列填充在一小部分的行中。
僅限受邀用戶的Cloud Numerics Lab交付工件包括面向Visual Studio 2010及更高版本的一個微軟Cloud Numerics Application模板(圖1),它包含幾個預制的C#項目,如表格1所示。

表格1:組成一個微軟Cloud Numerics應用程序的六個預制項目。
默認的MSCloudNumericsApp項目隨帶一個基本的Main()函數,以便控制臺應用程序使用一個簡單的進程,在本地開發環境中測試運行。該函數對微軟Numerics運行時環境初始化,創建元素數組并填入隨機數,執行矩陣相乘,然后運用喬里斯基分解方法來求解線性方程,關閉微軟Numerics運行時環境,返回表示完成的消息。
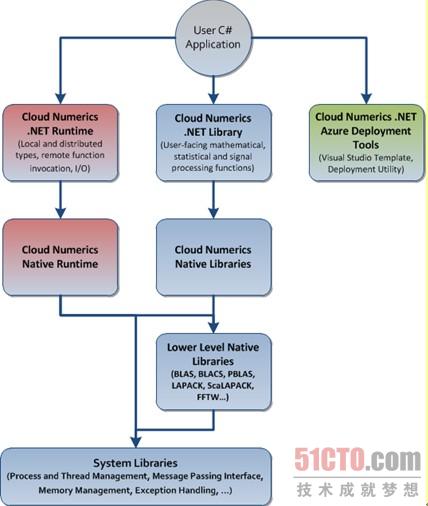
圖2:Cloud Numerics運行時環境、庫和Windows Azure部署工具之間的關系。
在大多數情況下,開發人員只需要把Main()函數中的幾行默認代碼換成自己的過程就行。圖2表明了各Cloud Numerics組件之間的關系。
最初的Cloud Numerics Lab版本提供了下列端到端的示例應用程序(http://connect.microsoft.com/site1267/Downloads/DownloadDetails.aspx?DownloadID=40598),可從微軟Microsoft Connect下載:
1. 使用潛在語義索引(Latent Sematic Indexing)的文檔分類實例(LSICloudApplication)。
2. 深入視察一些統計功能(StatisticsCloudApplication)。
3. 對串行產量數據進行時間序列分析(TimeSeriesApplication)。
我之前發表了一篇配有插圖的逐步教程,介紹在本地開發環境中安裝和運行LSICloudApplication(http://oakleafblog.blogspot.com/2012/01/introducing-microsoft-codename-cloud.html),并將它部署到Windows Azure帳戶(http://oakleafblog.blogspot.com/2012/01/deploying-cloud-numerics-sample.html)。#p#
使用Cloud Numerics分析航空公司起飛延誤
航班準點率是許多消費者選擇航班時參考的一個重要方面。美國聯邦航空管理局(FAA)保存著自1987年以來每一家美國注冊航空公司的所有航班抵達和起飛延誤數據的完整記錄。FAA通過研究和創新技術管理局(RITA)下設運輸統計局(BTS)的網站(http://www.transtats.bts.gov/DL_SelectFields.asp?Table_ID=236&DB_Short_Name=On-Time),通過含有每個月的*.csv文件的*.zip壓縮文檔這一形式,向公眾公布這些數據。每個*.csv文件含有大約500000行數據,它們的大小平均大約是225 MB。因此,截至2012年2月的共302個月的數據總量約為1.5億行和68 GB。
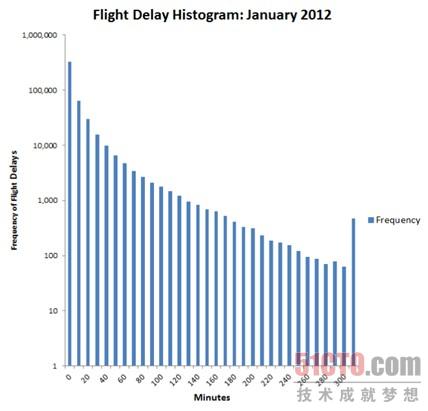
圖3:該直方圖顯示了2012年1月美國注冊航空公司從0到5小時的航班延誤。
Cloud Numerics團隊宣布了一款新的示例程序,可以歸納32個月來FAA航班數據的平均延誤和延誤數據的標準偏差。圖3所示的Excel直方圖顯示了2012年1月從0到5小時的航班抵達延誤。
為了讓開發人員輕松地使用該示例程序,Cloud Numerics團隊把直到2012年1月的32個*.csv文件拷貝到了公眾可以訪問的Windows Azure二進制大對象容器(blob container),該容器位于微軟建在美國中北部的一個數據中心。32個文件可不算少,因為每一個超大計算節點(ExtraLarge ComputeNode)實例都有8個處理器核心;而AppConfigure項目部署了4個這樣的實例。
微軟SQL Azure Labs社區技術預覽(CTP)在預覽期間提供了隨意免費所用資源這一便利,但是Cloud Numerics不提供這種便利。運行有四個ComputeNode、一個HeadNode工作者角色和一個FrontEnd Web角色的OnTimeStats應用程序每小時要收費5.10美元。這樣的成本使得你在不用部署的Cloud Numerics時就會刪除它們。
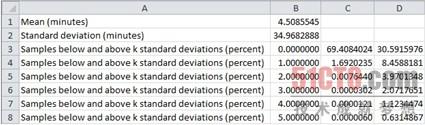
圖4:Excel工作表單,平均偏差和標準偏差數據來自FlightDataInfo.csv文件。
MSCloudNumericsApp項目的Main()方法含有的添加代碼可計算平均抵達延誤時間、抵達時間的標準偏差以及低于及高于1、2、3、4和5標準偏差的時間以及值,這些代碼添加到存儲在Windows Azure二進制大對象容器的FlightDataInfo.csv文件(見圖4)。把近800萬行數據讀入到含有抵達延誤時間(單位:分鐘)的數組用時不到2分鐘。使用兩個超大計算實例(16個核心)來分析只需要不到2分鐘的時間。
這個結果對乘客來說既是好消息又是壞消息。好消息是,你至多延誤5分鐘抵達的可能性是70%。不過,按照條件概率,尾部曲線的指數性質意味著如果你已經要等35分鐘,那么再等35分鐘的可能性是50%。#p#
比較Cloud Numerics和Windows Azure上的Apache Hive
Windows Azure上的Apache Hadoop預覽版讓你可以分析存儲在Windows Azure二進制大對象容器的文件夾中的數據。不過,能夠用專用Azure二進制大對象容器取代HDFS數據集的功能并不適用于像Cloud Numerics團隊上傳的這些公共二進制大對象容器。

圖5:顯示航空公司航班延誤的Excel圖表,來自Hadoop。
我消除了不必要的列,把2011年8月到2012年1月的六個*.csv文件上傳到美國中北部數據中心的二進制大對象容器中的一個文件夾,從而縮減了這些文件的大小。我把這個二進制大對象文件夾指定為Hive數據倉庫表格的數據源,創建了Hive表格,然后使用Hive開放數據庫連接(ODBC)驅動程序和Excel插件,對它執行了簡單的HiveQL聚集查詢(見圖5)。
Hive方法所用的時間要比Cloud Numerics示例程序所用的時間短得多,因為后者通過低速的DSL互聯網連接,把HPC集群上傳到Windows Azure大概需要2個小時。不過,Cloud Numerics可以更快地獲取同樣的數據;我估計,使用HiveQL查詢來確定這個結果至少要花掉我半天的時間。不然,我需要另外花幾個小時來編寫和測試Pig Latin腳本。 要不是互聯網連接不對稱這種現狀,利用Cloud Numerics獲得數據的速度會大大加快。
原文鏈接:http://searchcloudcomputing.techtarget.com/tip/Analyzing-big-data-with-Microsoft-Cloud-Numerics














