













Hadoop云服務之戰:微軟vs.亞馬遜
毫無疑問,Apache Hadoop軟件庫擁有當今最多的大數據分析思想。Gartner在2012年三月的報告中指出Hadoop作為一個流行的搜索詞,在網站上的搜索量已經比2011年增加了601.8%。Hadoop逐漸普及的背后主要的驅動力在于大數據和社交計算的炒作,廣泛的企業級開源軟件應用,擁有Hadoop熟練技能的開發人員資源池以及Hadoop可以用預期達成的性能以低廉的商業服務器集群成本交付高可用性。后面的這個性能讓企業能夠將Hadoop工作負載部署到IaaS和PaaS提供商的云上,代替數據中心資本投資中的幾次付費費用。
Apache軟件基金會將Hadoop描述為:
Apache Hadoop項目是用以開發可靠、可擴展且分布式的計算的開源軟件。
Apache Hadoop軟件庫是一種通過使用簡單的編程模型,跨計算機集群的大型數據集分布式處理框架。旨在從單一服務器擴展到成千上萬的機器,每一個產品本地計算并存儲。而不是依賴于硬件來交付高可用性,該軟件庫本身旨在檢測和處理應用層的失敗,從而交付計算機集群頂層的高可用性服務,每一個都可能發生故障。
商業開源分布式軟件,像紅帽Enterprise Linux,屬于企業級不可或缺的。Cloudera領先的商業Hadoop分布式用免費增值模式,提供了免費的Cloudera Distribution for Hadoop (CDH),但是需要對支持和Cloudera Manager應用許可證。因為其商業模式和市場支配,Cloudera成為很多“紅帽Hadoop”的使用者的考慮對象。Yahoo!經典的Hadoop開發者,已經改變了野蠻,但是Cloudera卻在出售其“Hadoop圣經。”因此Yahoo!于2011年六月甩掉了其Hadoop工程師團隊,進入Hortonworks,Benchmark資本投資的一個新的實體,來獲取Hadoop的收益,從而與Cloudera競爭。Cloudera2012年三月宣布同IBM合作,將其CDH、Cloudera Manager同本地的IBM BigInsights平臺整合,并放入IBM的公有SmartCloud服務中。
亞馬遜的彈性MapReduce
亞馬遜Web服務(AWS)于2009年4月2日引入了彈性MapReduce服務(EMR),讓AWS成為基于云的Hadoop服務的祖父。EMR使用按需的EC2實例集群處理存儲于S3或者DynamoDB中的數據。專業的按需EMR實例陳本范圍從小型的每小時0.105美元到每小時0.864美元的大型Hi-CPU實例,包括EMR額外的費用。S3和Dynamo DB存儲為標準的按月付費,每GB數據傳輸到亞馬遜數據中或者從亞馬遜數據中心輸出都適用。你可以按每小時付費或者你實際運行的實例付費。
AWS在EMR開始手冊中提供了代碼示例和教程,介紹在Linux、UNIX以及Windows語法中,通過EMR Command Line Interface (CLI)創建Streaming Job Flow。或者你可以適用Hive和亞馬遜EMR工作流創建和執行一個簡單的Contextual Advertising,如圖一所示,EMR Management Console,鏈接中的博客描述了細節。
圖一圖解自動化彈性MapReduce和Hive工作流。你可以從CLI或者AWS管理控制臺運行交互的Hive會話。
這篇文章對比了用AWS Management Console(圖二)創建Hive工作流,而不是CLI,因為微軟的Apache Hadoop on Windows Azure (AHoWA)服務包括了交互式Hive控制臺,性能類似。Apache基金會將Hive描述為:
Hive是一個Hadoop的數據倉庫系統,促進簡化數據摘要、臨時查詢和存儲在Hadoop兼容文件系統中的大型數據集的分析。Hive提供了數據之上項目結構以及使用類SQL語言HiveQL查詢數據的一種機制。同時,HiveQL中不方便或者表達不清這個邏輯時,該語言可以讓傳統的map/reduce程序員插入其自定義的mappers和reducers。
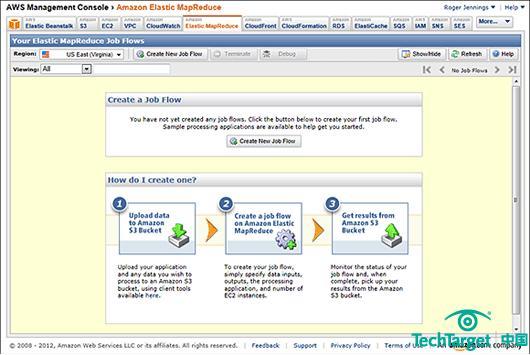
圖二,AWS Management Console下Elastic MapReduce選項創建Job Flow頁面。點擊Create New Job Flow按鈕,可以選擇Contextual Advertising示例HiveQL聲明,轉換ad-server impression數據到Hive表中。此外,MapReduce操作生成匯總廣告效率的順序文件。
2012年5月31日,AWS升級EMR到最新的Hive版本(0.8.1)中。Hive能夠翻譯HiveQL聲明到MapReduce操作中并在執行這個操作,相反本地文件中湖綜合公有云數據存儲(比如亞馬遜 S3或者Windows Azure blobs)的Hive表中的數據也是。例如,下面示例的HiveQL聲明創建了一個名為impressions的Hive表,在SerializeDeserialize (serde)格式中有七個字段,從S3中JavaScript Object Notation (JSON)格式存儲的ad-server impression日志文件……/表/ impressions folder:
CREATE EXTERNAL TABLE impressions (
requestBeginTime string
adId string,
impressionId string,
referrer string,
userAgent string,
userCookie string,
ip string )
PARTITIONED BY (dt string)
ROW FORMAT
serde 'com.amazon.elasticmapreduce.JsonSerde'
with serdeproperties ( 'paths'='requestBeginTime, adId,
impressionId, referrer,
userAgent, userCookie, ip' )
LOCATION '${SAMPLE}/tables/impressions' ;
Contextual Advertising工作流運行之前的聲明,存儲在S3腳本文件中,從而為后來的分析創建Hive表。第二個CREATE EXTERNAL TABLE聲明生成一個點擊表,從ad click日志數據和另一個impressions和clicks聯合的表。如果你使用推薦的大型實例,每個實例每小時0.42美元,需要一個關鍵或者兩個核心實例,成本是1.26美元。使用默認的小型實例,成本降到0.315美元。小型實例整個執行時間大約是20分鐘。整個執行完成后,管理控制臺停止運行所有實例。
進一步的操作會生成一個功能主頁表,可以用于計算一個廣告的點擊估價。以S3腳本的形式存儲這些估價HiveQL聲明,選擇一個而你不是第二步中的工作流處理示例腳本,在管理控制臺的S3選擇項中查看作為結果生成的S3文件。 #p#
微軟的Apache Hadoop on Windows Azure服務預覽
2011年12月14日SQL Server大數據團隊發布了Apache Hadoop on Windows Azure服務商業技術預覽(CTP)版本的邀請碼,該團隊期望在2012年初公諸于眾。微軟同Hortonworks合作,創建服務,提供核心的Hadoop/MapReduce功能、JavaScript庫,可以用JavaScript編寫MapReduce程序,用標準的Web瀏覽器運行工作,以及一個交互的JavaScript/Hive 控制臺來編寫和執行HiveQL聲明。分析師使用Excel和其他的微軟商業智能(BI)工具可以下載一個Hive ODBC驅動和Excel插件,允許他們用BI工具,比如PowerPivot和PowerView,發布HiveQL查詢到分析結構或者非結構的Hadoop數據。預期AHoWA 用戶必須通過邀請碼郵件填寫一個簡要的調查。通過邀請碼登錄到AHoWA 網站,打開Request a New Cluster 頁面(圖三所示)。在預覽期間沒有AHoWA 資源消耗費用。然而,集群48小時候回收;你可以在24小時內重新創建一個,其生命周期持續6小時。
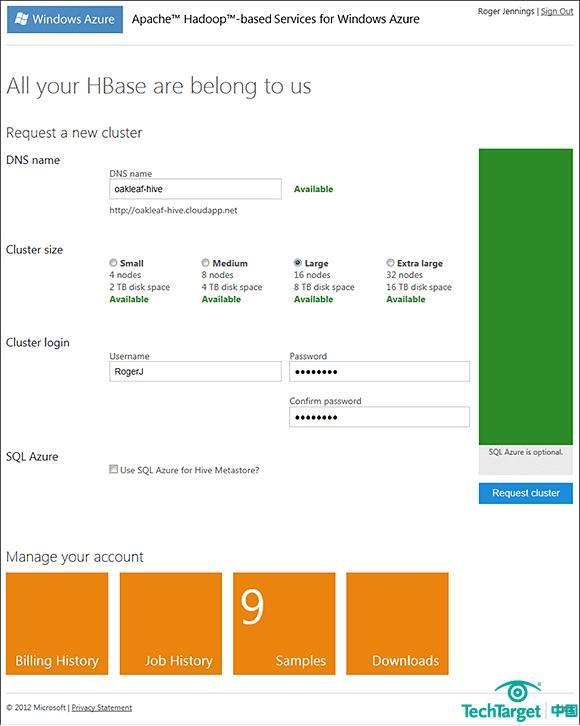
圖三,AhoWA網站的Metro-ized Create a New Cluster頁面。制定一個唯一的DNS命名,選擇一個集群大小并提供管理認證,啟用Request Cluster按鈕。分配一個大型集群的一個集群頭和四個工作結點只需要幾分鐘。
創建了集群后你可以運行九個示例Apache MapReduce中的一個,Pig、Sqoop和Mahout項目。或者你可以設置Windows Azure Marketplace Datamarket產品,Windows Azure對象容器或者亞馬遜S3文件所謂數據源,放入Hive表中,具體的介紹詳見鏈接的博客(圖四)。
圖四,從亞馬遜S3表格上傳。Manage Cluster頁面的啟動S3按鈕打開這個表格,需要你的AWS Access Key和Secret Key進行驗證。你為S3數據源文件選定具體的URL進入到HiveQL聲明中。
下面的HiveQL聲明鍵入在文本框中的數據顯示區域,創建了一個本地功能主頁Hive表,以Hadoop SEQUENCEFILE的格式有四列,用于后來的查詢:
CREATE EXTERNAL TABLE feature_index (
feature STRING,
ad_id STRING,
clicked_percent DOUBLE )
COMMENT 'Amazon EMR Hive Output'
STORED AS SEQUENCEFILE
LOCATION 's3n://oakleaf-emr/hive-ads/output/2012-05-29/feature_index';
點擊Evaluate按鈕執行這個聲明,大約四秒的時間內清空文本框并創建一個鏈接到數據源(見圖五)。從S3數據源中選擇查詢下載數據。
圖五,去人HiveQL查詢的執行。查看工作日志需要一個遠程桌面協議(RDP)連接到Azure High Performance Cluster中。
創建一個Hive表,增加其名稱到表格列表中,命名列到列列表中,執行SELECT * FROM feature_index LIMIT ,20個查詢結果顯示出來,這是最先的20個結果(見圖六)。
圖六,第一個20行。花了7.265秒來執行一個簡單的HiveQL SELECT查詢,由于互聯網延遲和相對較低的DSL連接。
AWS的Contextual Advertisin中的“Applying the Heuristic”部分建議執行下面的示例HiveQL查詢對抗功能主頁表“功能'us:safari' and 'ua:chrome'如何執行”:
SELECT ad_id, -sum(log(if(0.0001 > clicked_percent, 0.0001, clicked_percent))) AS value
FROM feature_index
WHERE feature = 'ua:safari' OR feature = 'ua:chrome'
GROUP BY ad_id
ORDER BY value DESC
LIMIT 100;
根據文章:
結果就是通過試探性的偶然點擊排序廣告。在這一點上,我們查閱廣告,假設蘋果產品的優勢。
圖七展示了執行之前查詢的結果,展示了最高點擊率的廣告:
圖七,返回的100個最高點擊率的第一個15行。Hive History數據并沒有顯示出來,期間兩個MapReduce工作已經執行。
如果你對于集成PowerPivot和Excel,通過交互Hive控制臺生產數據感興趣,看看我的《Using Excel 2010 and the Hive ODBC Driver to Visualize Hive Data Sources in Apache Hadoop on Windows Azure》一文。為了給控制臺進行Windows Azure對象測試作為數據源,看《Using Data from Windows Azure Blobs with Apache Hadoop on Windows Azure CTP》一文。
總結
與微軟的AhoWA相比,亞馬遜的EMR是一個經驗豐富的Hadoop/MapReduce老手,AhoWA讓是預覽階段。二者都提供了Apache Hadoop完全詳細的核心功能,但是AhoWA用其交互式Hive和JavaScript控制臺贏得了可用性。如果你的分析團隊使用Excel或者其他的微軟BI工具,Hive ODBC驅動和Excel Hive Ad-In在增加性能方面就是贏家。












