7個示例科普CPU Cache
CPU cache一直是理解計算機體系架構的重要知識點,也是并發編程設計中的技術難點,而且相關參考資料如同過江之鯽,浩瀚繁星,閱之如臨深淵,味同嚼蠟,三言兩語難以入門。正好網上有人推薦了微軟大牛Igor Ostrovsky一篇博文《漫游處理器緩存效應》,文章不僅僅用7個最簡單的源碼示例就將CPU cache的原理娓娓道來,還附加圖表量化分析做數學上的佐證,個人感覺這種案例教學的切入方式絕對是俺的菜,故而忍不住貿然譯之,以饗列位看官。
原文地址:Gallery of Processor Cache Effects
大多數讀者都知道cache是一種快速小型的內存,用以存儲最近訪問內存位置。這種描述合理而準確,但是更多地了解一些處理器緩存工作中的“煩人”細節對于理解程序運行性能有很大幫助。
在這篇博客中,我將運用代碼示例來詳解cache工作的方方面面,以及對現實世界中程序運行產生的影響。
下面的例子都是用C#寫的,但語言的選擇同程序運行狀況以及得出的結論幾乎沒什么影響。
示例1:內存訪問和運行
你認為相較于循環1,循環2會運行多快?
- int[] arr = new int[64 * 1024 * 1024];
- // Loop 1
- for (int i = 0; i < arr.Length; i++) arr[i] *= 3;
- // Loop 2
- for (int i = 0; i < arr.Length; i += 16) arr[i] *= 3;
第一個循環將數組的每個值乘3,第二個循環將每16個值乘3,第二個循環只做了第一個約6%的工作,但在現代機器上,兩者幾乎運行相同時間:在我機器上分別是80毫秒和78毫秒。
兩個循環花費相同時間的原因跟內存有關。循環執行時間長短由數組的內存訪問次數決定的,而非整型數的乘法運算次數。經過下面對第二個示例的解釋,你會發現硬件對這兩個循環的主存訪問次數是相同的。
示例2:緩存行的影響
讓我們進一步探索這個例子。我們將嘗試不同的循環步長,而不僅僅是1和16。
- for (int i = 0; i < arr.Length; i += K) arr[i] *= 3;
下圖為該循環在不同步長(K)下的運行時間:
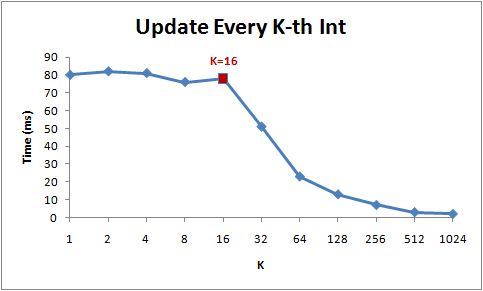
注意當步長在1到16范圍內,循環運行時間幾乎不變。但從16開始,每次步長加倍,運行時間減半。
背后的原因是今天的CPU不再是按字節訪問內存,而是以64字節為單位的塊(chunk)拿取,稱為一個緩存行(cache line)。當你讀一個特定的內存地址,整個緩存行將從主存換入緩存,并且訪問同一個緩存行內的其它值的開銷是很小的。
由于16個整型數占用64字節(一個緩存行),for循環步長在1到16之間必定接觸到相同數目的緩存行:即數組中所有的緩存行。當步長為32,我們只有大約每兩個緩存行接觸一次,當步長為64,只有每四個接觸一次。
理解緩存行對某些類型的程序優化而言可能很重要。比如,數據字節對齊可能決定一次操作接觸1個還是2個緩存行。那上面的例子來說,很顯然操作不對齊的數據將損失一半性能。
示例3:L1和L2緩存大小
今天的計算機具有兩級或三級緩存,通常叫做L1、L2以及可能的L3(譯者注:如果你不明白什么叫二級緩存,可以參考這篇精悍的博文lol)。如果你想知道不同緩存的大小,你可以使用系統內部工具CoreInfo,或者Windows API調用GetLogicalProcessorInfo。兩者都將告訴你緩存行以及緩存本身的大小。
在我的機器上,CoreInfo現實我有一個32KB的L1數據緩存,一個32KB的L1指令緩存,還有一個4MB大小L2數據緩存。L1緩存是處理器獨享的,L2緩存是成對處理器共享的。
Logical Processor to Cache Map:
*— Data Cache 0, Level 1, 32 KB, Assoc 8, LineSize 64
*— Instruction Cache 0, Level 1, 32 KB, Assoc 8, LineSize 64
-*– Data Cache 1, Level 1, 32 KB, Assoc 8, LineSize 64
-*– Instruction Cache 1, Level 1, 32 KB, Assoc 8, LineSize 64
**– Unified Cache 0, Level 2, 4 MB, Assoc 16, LineSize 64
–*- Data Cache 2, Level 1, 32 KB, Assoc 8, LineSize 64
–*- Instruction Cache 2, Level 1, 32 KB, Assoc 8, LineSize 64
—* Data Cache 3, Level 1, 32 KB, Assoc 8, LineSize 64
—* Instruction Cache 3, Level 1, 32 KB, Assoc 8, LineSize 64
–** Unified Cache 1, Level 2, 4 MB, Assoc 16, LineSize 64
(譯者注:作者平臺是四核機,所以L1編號為0~3,數據/指令各一個,L2只有數據緩存,兩個處理器共享一個,編號0~1。關聯性字段在后面例子說明。)
讓我們通過一個實驗來驗證這些數字。遍歷一個整型數組,每16個值自增1——一種節約地方式改變每個緩存行。當遍歷到最后一個值,就重頭開始。我們將使用不同的數組大小,可以看到當數組溢出一級緩存大小,程序運行的性能將急劇滑落。
- int steps = 64 * 1024 * 1024;
- // Arbitrary number of steps
- int lengthMod = arr.Length - 1;
- for (int i = 0; i < steps; i++)
- {
- arr[(i * 16) & lengthMod]++; // (x & lengthMod) is equal to (x % arr.Length)
- }
下圖是運行時間圖表:
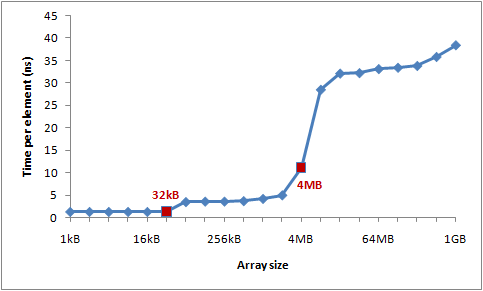
你可以看到在32KB和4MB之后性能明顯滑落——正好是我機器上L1和L2緩存大小。
#p#
示例4:指令級別并發
現在讓我們看一看不同的東西。下面兩個循環中你以為哪個較快?
- int steps = 256 * 1024 * 1024;
- int[] a = new int[2];
- // Loop 1
- for (int i=0; i<steps; i++) { a[0]++; a[0]++; }
- // Loop 2
- for (int i=0; i<steps; i++) { a[0]++; a[1]++; }
結果是第二個循環約比第一個快一倍,至少在我測試的機器上。為什么呢?這跟兩個循環體內的操作指令依賴性有關。
第一個循環體內,操作做是相互依賴的(譯者注:下一次依賴于前一次):

但第二個例子中,依賴性就不同了:

現代處理器中對不同部分指令擁有一點并發性(譯者注:跟流水線有關,比如Pentium處理器就有U/V兩條流水線,后面說明)。這使得CPU在同 一時刻訪問L1兩處內存位置,或者執行兩次簡單算術操作。在第一個循環中,處理器無法發掘這種指令級別的并發性,但第二個循環中就可以。
[原文更新]:許多人在reddit上詢問有關編譯器優化的問題,像{ a[0]++; a[0]++; }能否優化為{ a[0]+=2; }。實際上,C#編譯器和CLR JIT沒有做優化——在數組訪問方面。我用release模式編譯了所有測試(使用優化選項),但我查詢了JIT匯編語言證實優化并未影響結果。
示例5:緩存關聯性
緩存設計的一個關鍵決定是確保每個主存塊(chunk)能夠存儲在任何一個緩存槽里,或者只是其中一些(譯者注:此處一個槽位就是一個緩存行)。
有三種方式將緩存槽映射到主存塊中:
- 直接映射(Direct mapped cache)
- 每個內存塊只能映射到一個特定的緩存槽。一個簡單的方案是通過塊索引chunk_index映射到對應的槽位(chunk_index % cache_slots)。被映射到同一內存槽上的兩個內存塊是不能同時換入緩存的。(譯者注:chunk_index可以通過物理地址/緩存行字節計算 得到)
- N路組關聯(N-way set associative cache)
- 每個內存塊能夠被映射到N路特定緩存槽中的任意一路。比如一個16路緩存,每個內存塊能夠被映射到16路不同的緩存槽。一般地,具有一定相同低bit位地址的內存塊將共享16路緩存槽。(譯者注:相同低位地址表明相距一定單元大小的連續內存)
- 完全關聯(Fully associative cache)
- 每個內存塊能夠被映射到任意一個緩存槽。操作效果上相當于一個散列表。
直接映射緩存會引發沖突——當多個值競爭同一個緩存槽,它們將相互驅逐對方,導致命中率暴跌。另一方面,完全關聯緩存過于復雜,并且硬件實現上昂貴。N路組關聯是處理器緩存的典型方案,它在電路實現簡化和高命中率之間取得了良好的折中。

(此圖由譯者給出,直接映射和完全關聯可以看做N路組關聯的兩個極端,從圖中可知當N=1時,即直接映射;當N取最大值時,即完全關聯。讀者可以自行想象直接映射圖例,具體表述見參考資料。)
舉個例子,4MB大小的L2緩存在我機器上是16路關聯。所有64字節內存塊將分割為不同組,映射到同一組的內存塊將競爭L2緩存里的16路槽位。
L2緩存有65,536個緩存行(譯者注:4MB/64),每個組需要16路緩存行,我們將獲得4096個集。這樣一來,塊屬于哪個組取決于塊索引的低12位bit(2^12=4096)。因此緩存行對應的物理地址凡是以262,144字節(4096*64)的倍數區分的,將競爭同一個緩存槽。我機器上最多維持16個這樣的緩存槽。(譯 者注:請結合上圖中的2路關聯延伸理解,一個塊索引對應64字節,chunk0對應組0中的任意一路槽位,chunk1對應組1中的任意一路槽位,以此類 推chunk4095對應組4095中的任意一路槽位,chunk0和chunk4096地址的低12bit是相同的,所以chunk4096、 chunk8192將同chunk0競爭組0中的槽位,它們之間的地址相差262,144字節的倍數,而最多可以進行16次競爭,否則就要驅逐一個 chunk)。
為了使得緩存關聯效果更加明了,我需要重復地訪問同一組中的16個以上的元素,通過如下方法證明:
- public static long UpdateEveryKthByte(byte[] arr, int K)
- {
- Stopwatch sw = Stopwatch.StartNew();
- const int rep = 1024*1024; // Number of iterations – arbitrary
- int p = 0;
- for (int i = 0; i < rep; i++)
- {
- arr[p]++;
- p += K;
- if (p >= arr.Length) p = 0;
- }
- sw.Stop();
- return sw.ElapsedMilliseconds;
- }
該方法每次在數組中迭代K個值,當到達末尾時從頭開始。循環在運行足夠長(2^20次)之后停止。
我使用不同的數組大小(每次增加1MB)和不同的步長傳入UpdateEveryKthByte()。以下是繪制的圖表,藍色代表運行較長時間,白色代表較短時間:
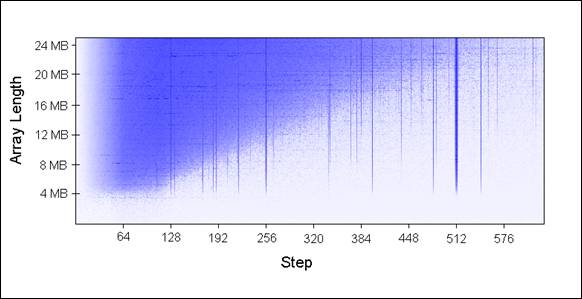
藍色區域(較長時間)表明當我們重復數組迭代時,更新的值無法同時放在緩存中。淺藍色區域對應80毫秒,白色區域對應10毫秒。
讓我們來解釋一下圖表中藍色部分:
1.為何有垂直線?垂直線表明步長值過多接觸到同一組中內存位置(大于16次)。在這些次數里,我的機器無法同時將接觸過的值放到16路關聯緩存中。
一些糟糕的步長值為2的冪:256和512。舉個例子,考慮512步長遍歷8MB數組,存在32個元素以相距262,144字節空間分布,所有32個元素都會在循環遍歷中更新到,因為512能夠整除262,144(譯者注:此處一個步長代表一個字節)。
由于32大于16,這32個元素將一直競爭緩存里的16路槽位。
(譯者注:為何512步長的垂直線比256步長顏色更深?在同樣足夠多的步數下,512比256訪問到存在競爭的塊索引次數多一倍。比如跨越 262,144字節邊界512需要512步,而256需要1024步。那么當步數為2^20時,512訪問了2048次存在競爭的塊而256只有1024 次。最差情況下步長為262,144的倍數,因為每次循環都會引發一個緩存行驅逐。)
有些不是2的冪的步長運行時間長僅僅是運氣不好,最終訪問到的是同一組中不成比例的許多元素,這些步長值同樣顯示為藍線。
2.為何垂直線在4MB數組長度的地方停止?因為對于小于等于4MB的數組,16路關聯緩存相當于完全關聯緩存。
一個16路關聯緩存最多能夠維護16個以262,144字節分隔的緩存行,4MB內組17或更多的緩存行都沒有對齊在262,144字節邊界上,因為16*262,144=4,194,304。
3.為何左上角出現藍色三角?在三角區域內,我們無法在緩存中同時存放所有必要的數據,不是出于關聯性,而僅僅是因為L2緩存大小所限。
舉個例子,考慮步長128遍歷16MB數組,數組中每128字節更新一次,這意味著我們一次接觸兩個64字節內存塊。為了存儲16MB數組中每兩個緩存行,我們需要8MB大小緩存。但我的機器中只有4MB緩存(譯者注:這意味著必然存在沖突從而延時)。
即使我機器中4MB緩存是全關聯,仍無法同時存放8MB數據。
4.為何三角最左邊部分是褪色的?注意左邊0~64字節部分——正好一個緩存行!就像上面示例1和2所說,額外訪問相同緩存行的數據幾乎沒有開銷。比如說,步長為16字節,它需要4步到達下一個緩存行,也就是說4次內存訪問只有1次開銷。
在相同循環次數下的所有測試用例中,采取省力步長的運行時間來得短。
將圖表延伸后的模型:
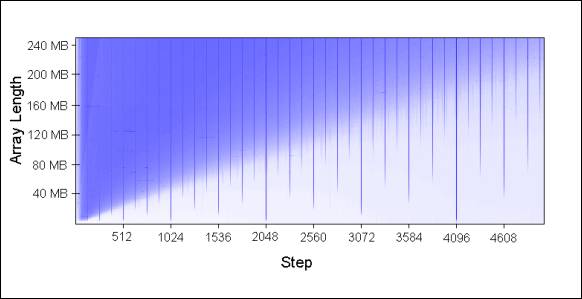
緩存關聯性理解起來有趣而且確能被證實,但對于本文探討的其它問題比起來,它肯定不會是你編程時所首先需要考慮的問題。
#p#
示例6:緩存行的偽共享(false-sharing)
在多核機器上,緩存遇到了另一個問題——一致性。不同的處理器擁有完全或部分分離的緩存。在我的機器上,L1緩存是分離的(這很普遍),而我有兩對 處理器,每一對共享一個L2緩存。這隨著具體情況而不同,如果一個現代多核機器上擁有多級緩存,那么快速小型的緩存將被處理器獨占。
當一個處理器改變了屬于它自己緩存中的一個值,其它處理器就再也無法使用它自己原來的值,因為其對應的內存位置將被刷新(invalidate)到所有緩存。而且由于緩存操作是以緩存行而不是字節為粒度,所有緩存中整個緩存行將被刷新!
為證明這個問題,考慮如下例子:
- private static int[] s_counter = new int[1024];
- private void UpdateCounter(int position)
- {
- for (int j = 0; j < 100000000; j++)
- {
- s_counter[position] = s_counter[position] + 3;
- }
- }
在我的四核機上,如果我通過四個線程傳入參數0,1,2,3并調用UpdateCounter,所有線程將花費4.3秒。
另一方面,如果我傳入16,32,48,64,整個操作進花費0.28秒!
為何會這樣?第一個例子中的四個值很可能在同一個緩存行里,每次一個處理器增加計數,這四個計數所在的緩存行將被刷新,而其它處理器在下一次訪問它 們各自的計數(譯者注:注意數組是private屬性,每個線程獨占)將失去命中(miss)一個緩存。這種多線程行為有效地禁止了緩存功能,削弱了程序 性能。
示例7:硬件復雜性
即使你懂得了緩存的工作基礎,有時候硬件行為仍會使你驚訝。不用處理器在工作時有不同的優化、探試和微妙的細節。
有些處理器上,L1緩存能夠并發處理兩路訪問,如果訪問是來自不同的存儲體,而對同一存儲體的訪問只能串行處理。而且處理器聰明的優化策略也會使你 感到驚訝,比如在偽共享的例子中,以前在一些沒有微調的機器上運行表現并不良好,但我家里的機器能夠對最簡單的例子進行優化來減少緩存刷新。
下面是一個“硬件怪事”的奇怪例子:
- private static int A, B, C, D, E, F, G;
- private static void Weirdness()
- {
- for (int i = 0; i < 200000000; i++)
- {
- // do something...
- }
- }
當我在循環體內進行三種不同操作,我得到如下運行時間:
操作 時間
A++; B++; C++; D++; 719 ms
A++; C++; E++; G++; 448 ms
A++; C++; 518 ms
增加A,B,C,D字段比增加A,C,E,G字段花費更長時間,更奇怪的是,增加A,C兩個字段比增加A,C,E,G執行更久!
我無法肯定這些數字背后的原因,但我懷疑這跟存儲體有關,如果有人能夠解釋這些數字,我將洗耳恭聽。
這個例子的教訓是,你很難完全預測硬件的行為。你可以預測很多事情,但最終,衡量及驗證你的假設非常重要。
關于第7個例子的一個回帖
Goz:我詢問Intel的工程師最后的例子,得到以下答復:
“很顯然這涉及到執行單元里指令是怎樣終止的,機器處理存儲-命中-加載的速度,以及如何快速且優雅地處理試探性執行的循環展開(比如是否由于內部 沖突而多次循環)。但這意味著你需要非常細致的流水線跟蹤器和模擬器才能弄明白。在紙上預測流水線里的亂序指令是無比困難的工作,就算是設計芯片的人也一 樣。對于門外漢來說,沒門,抱歉!”
P.S.個人感悟——局部性原理和流水線并發
程序的運行存在時間和空間上的局部性,前者是指只要內存中的值被換入緩存,今后一段時間內會被多次引用,后者是指該內存附近的值也被換入緩存。如果在編程中特別注意運用局部性原理,就會獲得性能上的回報。
比如C語言中應該盡量減少靜態變量的引用,這是因為靜態變量存儲在全局數據段,在一個被反復調用的函數體內,引用該變量需要對緩存多次換入換出,而如果是分配在堆棧上的局部變量,函數每次調用CPU只要從緩存中就能找到它了,因為堆棧的重復利用率高。
再比如循環體內的代碼要盡量精簡,因為代碼是放在指令緩存里的,而指令緩存都是一級緩存,只有幾K字節大小,如果對某段代碼需要多次讀取,而這段代碼又跨越一個L1緩存大小,那么緩存優勢將蕩然無存。
關于CPU的流水線(pipeline)并發性簡單說說,Intel Pentium處理器有兩條流水線U和V,每條流水線可各自獨立地讀寫緩存,所以可以在一個時鐘周期內同時執行兩條指令。但這兩條流水線不是對等的,U流水線可以處理所有指令集,V流水線只能處理簡單指令。
CPU指令通常被分為四類,第一類是常用的簡單指令,像mov, nop, push, pop, add, sub, and, or, xor, inc, dec, cmp, lea,可以在任意一條流水線執行,只要相互之間不存在依賴性,完全可以做到指令并發。
第二類指令需要同別的流水線配合,像一些進位和移位操作,這類指令如果在U流水線中,那么別的指令可以在V流水線并發運行,如果在V流水線中,那么U流水線是暫停的。
第三類指令是一些跳轉指令,如cmp,call以及條件分支,它們同第二類相反,當工作在V流水線時才能通U流水線協作,否則只能獨占CPU。
第四類指令是其它復雜的指令,一般不常用,因為它們都只能獨占CPU。
如果是匯編級別編程,要達到指令級別并發,必須要注重指令之間的配對。盡量使用第一類指令,避免第四類,還要在順序上減少上下文依賴。