Java 拾遺 — CPU Cache 與緩存行
引言
- public class Main {
- static long[][] arr;
- public static void main(String[] args) {
- arr = new long[1024 * 1024][8];
- // 橫向遍歷
- long marked = System.currentTimeMillis();
- for (int i = 0; i < 1024 * 1024; i += 1) {
- for (int j = 0; j < 8; j++) {
- sum += arr[i][j];
- }
- }
- System.out.println("Loop times:" + (System.currentTimeMillis() - marked) + "ms");
- marked = System.currentTimeMillis();
- // 縱向遍歷
- for (int i = 0; i < 8; i += 1) {
- for (int j = 0; j < 1024 * 1024; j++) {
- sum += arr[j][i];
- }
- }
- System.out.println("Loop times:" + (System.currentTimeMillis() - marked) + "ms");
- }
- }
如上述代碼所示,定義了一個(gè)二維數(shù)組 long[][] arr 并且使用了橫向遍歷和縱向遍歷兩種順序?qū)@個(gè)二位數(shù)組進(jìn)行遍歷,遍歷總次數(shù)相同,只不過(guò)循環(huán)的方向不同,代碼中記錄了這兩種遍歷方式的耗時(shí),不妨先賣個(gè)關(guān)子,他們的耗時(shí)會(huì)有區(qū)別嗎?
這問(wèn)題問(wèn)的和中小學(xué)試卷中的:“它們之間有區(qū)別嗎?如有,請(qǐng)說(shuō)出區(qū)別。”一樣沒(méi)有水準(zhǔn),沒(méi)區(qū)別的話文章到這兒就結(jié)束了。事實(shí)上,在我的機(jī)器上(64 位 mac)多次運(yùn)行后可以發(fā)現(xiàn):橫向遍歷的耗時(shí)大約為 25 ms,縱向遍歷的耗時(shí)大約為 60 ms,前者比后者快了 1 倍有余。如果你了解上述現(xiàn)象出現(xiàn)的原因,大概能猜到,今天這篇文章的主角便是他了— CPU Cache&Cache Line。
在學(xué)生生涯時(shí),不斷收到這樣建議:《計(jì)算機(jī)網(wǎng)絡(luò)》、《計(jì)算機(jī)組成原理》、《計(jì)算機(jī)操作系統(tǒng)》、《數(shù)據(jù)結(jié)構(gòu)》四門課程是至關(guān)重要的,而在我這些年的工作經(jīng)驗(yàn)中也不斷地意識(shí)到前輩們?nèi)绱私ㄗh的原因。作為一個(gè) Java 程序員,你可以選擇不去理解操作系統(tǒng),組成原理(相比這二者,網(wǎng)絡(luò)和數(shù)據(jù)結(jié)構(gòu)跟日常工作聯(lián)系得相對(duì)緊密),這不會(huì)降低你的 KPI,但了解他們可以使你寫出更加計(jì)算機(jī)友好(Mechanical Sympathy)的代碼。
下面的章節(jié)將會(huì)出現(xiàn)不少操作系統(tǒng)相關(guān)的術(shù)語(yǔ),我將逐個(gè)介紹他們,并最終將他們與 Java 聯(lián)系在一起。
什么是 CPU 高速緩存?
CPU 是計(jì)算機(jī)的心臟,最終由它來(lái)執(zhí)行所有運(yùn)算和程序。主內(nèi)存(RAM)是數(shù)據(jù)(包括代碼行)存放的地方。這兩者的定義大家應(yīng)該不會(huì)陌生,那 CPU 高速緩存又是什么呢?
在計(jì)算機(jī)系統(tǒng)中,CPU高速緩存是用于減少處理器訪問(wèn)內(nèi)存所需平均時(shí)間的部件。在金字塔式存儲(chǔ)體系中它位于自頂向下的第二層,僅次于CPU寄存器。其容量遠(yuǎn)小于內(nèi)存,但速度卻可以接近處理器的頻率。
當(dāng)處理器發(fā)出內(nèi)存訪問(wèn)請(qǐng)求時(shí),會(huì)先查看緩存內(nèi)是否有請(qǐng)求數(shù)據(jù)。如果存在(***),則不經(jīng)訪問(wèn)內(nèi)存直接返回該數(shù)據(jù);如果不存在(失效),則要先把內(nèi)存中的相應(yīng)數(shù)據(jù)載入緩存,再將其返回處理器。
緩存之所以有效,主要是因?yàn)槌绦蜻\(yùn)行時(shí)對(duì)內(nèi)存的訪問(wèn)呈現(xiàn)局部性(Locality)特征。這種局部性既包括空間局部性(Spatial Locality),也包括時(shí)間局部性(Temporal Locality)。有效利用這種局部性,緩存可以達(dá)到極高的***率。
在處理器看來(lái),緩存是一個(gè)透明部件。因此,程序員通常無(wú)法直接干預(yù)對(duì)緩存的操作。但是,確實(shí)可以根據(jù)緩存的特點(diǎn)對(duì)程序代碼實(shí)施特定優(yōu)化,從而更好地利用緩存。
— 維基百科
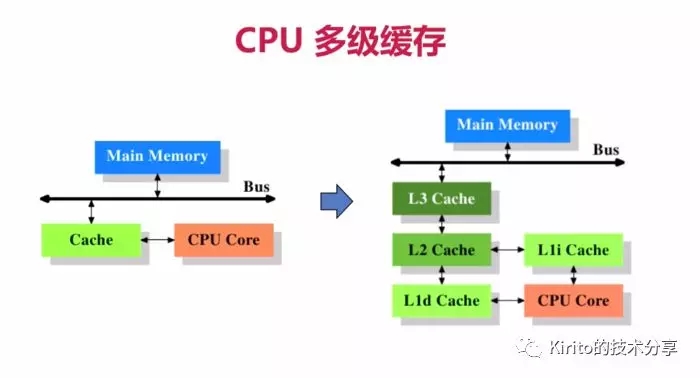
CPU 緩存架構(gòu)
左圖為最簡(jiǎn)單的高速緩存的架構(gòu),數(shù)據(jù)的讀取和存儲(chǔ)都經(jīng)過(guò)高速緩存,CPU 核心與高速緩存有一條特殊的快速通道;主存與高速緩存都連在系統(tǒng)總線上(BUS),這條總線還用于其他組件的通信。簡(jiǎn)而言之,CPU 高速緩存就是位于 CPU 操作和主內(nèi)存之間的一層緩存。
為什么需要有 CPU 高速緩存?
隨著工藝的提升,最近幾十年 CPU 的頻率不斷提升,而受制于制造工藝和成本限制,目前計(jì)算機(jī)的內(nèi)存在訪問(wèn)速度上沒(méi)有質(zhì)的突破。因此,CPU 的處理速度和內(nèi)存的訪問(wèn)速度差距越來(lái)越大,甚至可以達(dá)到上萬(wàn)倍。這種情況下傳統(tǒng)的 CPU 直連內(nèi)存的方式顯然就會(huì)因?yàn)閮?nèi)存訪問(wèn)的等待,導(dǎo)致計(jì)算資源大量閑置,降低 CPU 整體吞吐量。同時(shí)又由于內(nèi)存數(shù)據(jù)訪問(wèn)的熱點(diǎn)集中性,在 CPU 和內(nèi)存之間用較為快速而成本較高(相對(duì)于內(nèi)存)的介質(zhì)做一層緩存,就顯得性價(jià)比極高了。
為什么需要有 CPU 多級(jí)緩存?
結(jié)合 圖片 -- CPU 緩存架構(gòu),再來(lái)看一組 CPU 各級(jí)緩存存取速度的對(duì)比
- 各種寄存器,用來(lái)存儲(chǔ)本地變量和函數(shù)參數(shù),訪問(wèn)一次需要1cycle,耗時(shí)小于1ns;
- L1 Cache,一級(jí)緩存,本地 core 的緩存,分成 32K 的數(shù)據(jù)緩存 L1d 和 32k 指令緩存 L1i,訪問(wèn) L1 需要3cycles,耗時(shí)大約 1ns;
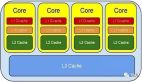
- L2 Cache,二級(jí)緩存,本地 core 的緩存,被設(shè)計(jì)為 L1 緩存與共享的 L3 緩存之間的緩沖,大小為 256K,訪問(wèn) L2 需要 12cycles,耗時(shí)大約 3ns;
- L3 Cache,三級(jí)緩存,在同插槽的所有 core 共享 L3 緩存,分為多個(gè) 2M 的段,訪問(wèn) L3 需要 38cycles,耗時(shí)大約 12ns;
大致可以得出結(jié)論,緩存層級(jí)越接近于 CPU core,容量越小,速度越快,同時(shí),沒(méi)有披露的一點(diǎn)是其造價(jià)也更貴。所以為了支撐更多的熱點(diǎn)數(shù)據(jù),同時(shí)追求***的性價(jià)比,多級(jí)緩存架構(gòu)應(yīng)運(yùn)而生。
什么是緩存行(Cache Line)?
上面我們介紹了 CPU 多級(jí)緩存的概念,而之后的章節(jié)我們將嘗試忽略“多級(jí)”這個(gè)特性,將之合并為 CPU 緩存,這對(duì)于我們理解 CPU 緩存的工作原理并無(wú)大礙。
緩存行 (Cache Line) 便是 CPU Cache 中的最小單位,CPU Cache 由若干緩存行組成,一個(gè)緩存行的大小通常是 64 字節(jié)(這取決于 CPU),并且它有效地引用主內(nèi)存中的一塊地址。一個(gè) Java 的 long 類型是 8 字節(jié),因此在一個(gè)緩存行中可以存 8 個(gè) long 類型的變量。
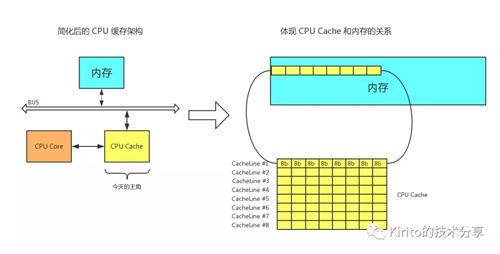
多級(jí)緩存
試想一下你正在遍歷一個(gè)長(zhǎng)度為 16 的 long 數(shù)組 data[16],原始數(shù)據(jù)自然存在于主內(nèi)存中,訪問(wèn)過(guò)程描述如下
- 訪問(wèn) data[0],CPU core 嘗試訪問(wèn) CPU Cache,未***。
- 嘗試訪問(wèn)主內(nèi)存,操作系統(tǒng)一次訪問(wèn)的單位是一個(gè) Cache Line 的大小 — 64 字節(jié),這意味著:既從主內(nèi)存中獲取到了 data[0] 的值,同時(shí)將 data[0] ~ data[7] 加入到了 CPU Cache 之中,for free~
- 訪問(wèn) data[1]~data[7],CPU core 嘗試訪問(wèn) CPU Cache,***直接返回。
- 訪問(wèn) data[8],CPU core 嘗試訪問(wèn) CPU Cache,未***。
- 嘗試訪問(wèn)主內(nèi)存。重復(fù)步驟 2
CPU 緩存在順序訪問(wèn)連續(xù)內(nèi)存數(shù)據(jù)時(shí)揮發(fā)出了***的優(yōu)勢(shì)。試想一下上一篇文章中提到的 PageCache,其實(shí)發(fā)生在磁盤 IO 和內(nèi)存之間的緩存,是不是有異曲同工之妙?只不過(guò)今天的主角— CPU Cache,相比 PageCache 更加的微觀。
再回到文章的開(kāi)頭,為何橫向遍歷 arr = new long[1024 * 1024][8] 要比縱向遍歷更快?此處得到了解答,正是更加友好地利用 CPU Cache 帶來(lái)的優(yōu)勢(shì),甚至有一個(gè)專門的詞來(lái)修飾這種行為 — Mechanical Sympathy。
偽共享
通常提到緩存行,大多數(shù)文章都會(huì)提到偽共享問(wèn)題(正如提到 CAS 便會(huì)提到 ABA 問(wèn)題一般)。
偽共享指的是多個(gè)線程同時(shí)讀寫同一個(gè)緩存行的不同變量時(shí)導(dǎo)致的 CPU 緩存失效。盡管這些變量之間沒(méi)有任何關(guān)系,但由于在主內(nèi)存中鄰近,存在于同一個(gè)緩存行之中,它們的相互覆蓋會(huì)導(dǎo)致頻繁的緩存未***,引發(fā)性能下降。偽共享問(wèn)題難以被定位,如果系統(tǒng)設(shè)計(jì)者不理解 CPU 緩存架構(gòu),甚至永遠(yuǎn)無(wú)法發(fā)現(xiàn) — 原來(lái)我的程序還可以更快。
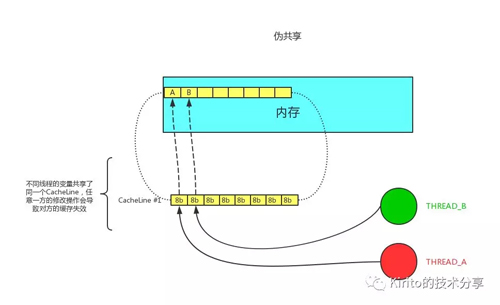
偽共享
正如圖中所述,如果多個(gè)線程的變量共享了同一個(gè) CacheLine,任意一方的修改操作都會(huì)使得整個(gè) CacheLine 失效(因?yàn)?CacheLine 是 CPU 緩存的最小單位),也就意味著,頻繁的多線程操作,CPU 緩存將會(huì)徹底失效,降級(jí)為 CPU core 和主內(nèi)存的直接交互。
偽共享問(wèn)題的解決方法便是字節(jié)填充。
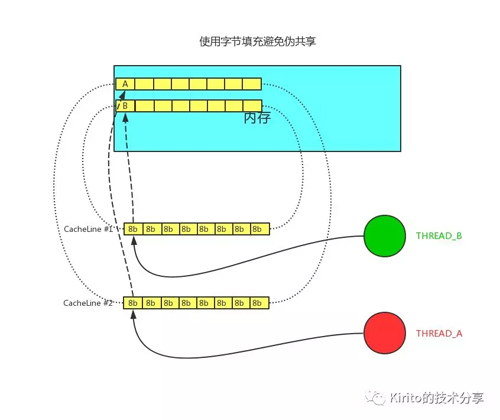
偽共享-字節(jié)填充
我們只需要保證不同線程的變量存在于不同的 CacheLine 即可,使用多余的字節(jié)來(lái)填充可以做點(diǎn)這一點(diǎn),這樣就不會(huì)出現(xiàn)偽共享問(wèn)題。在代碼層面如何實(shí)現(xiàn)圖中的字節(jié)填充呢?
Java6 中實(shí)現(xiàn)字節(jié)填充
- public class PaddingObject{
- public volatile long value = 0L; // 實(shí)際數(shù)據(jù)
- public long p1, p2, p3, p4, p5, p6; // 填充
- }
- PaddingOb
PaddingObject 類中需要保存一個(gè) long 類型的 value 值,如果多線程操作同一個(gè) CacheLine 中的 PaddingObject 對(duì)象,便無(wú)法完全發(fā)揮出 CPU Cache 的優(yōu)勢(shì)(想象一下你定義了一個(gè) PaddingObject[] 數(shù)組,數(shù)組元素在內(nèi)存中連續(xù),卻由于偽共享導(dǎo)致無(wú)法使用 CPU Cache 帶來(lái)的沮喪)。
不知道你注意到?jīng)]有,實(shí)際數(shù)據(jù) value + 用于填充的 p1~p6 總共只占據(jù)了 7 * 8 = 56 個(gè)字節(jié),而 Cache Line 的大小應(yīng)當(dāng)是 64 字節(jié),這是有意而為之,在 Java 中,對(duì)象頭還占據(jù)了 8 個(gè)字節(jié),所以一個(gè) PaddingObject 對(duì)象可以恰好占據(jù)一個(gè) Cache Line。
Java7 中實(shí)現(xiàn)字節(jié)填充
在 Java7 之后,一個(gè) JVM 的優(yōu)化給字節(jié)填充造成了一些影響,上面的代碼片段 public long p1, p2, p3, p4, p5, p6; 會(huì)被認(rèn)為是無(wú)效代碼被優(yōu)化掉,有回歸到了偽共享的窘境之中。
為了避免 JVM 的自動(dòng)優(yōu)化,需要使用繼承的方式來(lái)填充。
- abstract class AbstractPaddingObject{
- protected long p1, p2, p3, p4, p5, p6;// 填充
- }
- public class PaddingObject extends AbstractPaddingObject{
- public volatile long value = 0L; // 實(shí)際數(shù)據(jù)
- }
Tips:實(shí)際上我在本地 mac 下測(cè)試過(guò) jdk1.8 下的字節(jié)填充,并不會(huì)出現(xiàn)無(wú)效代碼的優(yōu)化,個(gè)人猜測(cè)和 jdk 版本有關(guān),不過(guò)為了保險(xiǎn)起見(jiàn),還是使用相對(duì)穩(wěn)妥的方式去填充較為合適。
如果你對(duì)這個(gè)現(xiàn)象感興趣,測(cè)試代碼如下:
- public final class FalseSharing implements Runnable {
- public final static int NUM_THREADS = 4; // change
- public final static long ITERATIONS = 500L * 1000L * 1000L;
- private final int arrayIndex;
- private static VolatileLong[] longs = new VolatileLong[NUM_THREADS];
- static {
- for (int i = 0; i < longs.length; i++) {
- longs[i] = new VolatileLong();
- }
- }
- public FalseSharing(final int arrayIndex) {
- this.arrayIndex = arrayIndex;
- }
- public static void main(final String[] args) throws Exception {
- final long start = System.currentTimeMillis();
- runTest();
- System.out.println("duration = " + (System.currentTimeMillis() - start));
- }
- private static void runTest() throws InterruptedException {
- Thread[] threads = new Thread[NUM_THREADS];
- for (int i = 0; i < threads.length; i++) {
- threads[i] = new Thread(new FalseSharing(i));
- }
- for (Thread t : threads) {
- t.start();
- }
- for (Thread t : threads) {
- t.join();
- }
- }
- public void run() {
- long i = ITERATIONS + 1;
- while (0 != --i) {
- longs[arrayIndex].value = i;
- }
- }
- public final static class VolatileLong {
- public volatile long value = 0L;
- public long p1, p2, p3, p4, p5, p6; // 填充,可以注釋后對(duì)比測(cè)試
- }
- }
Java8 中實(shí)現(xiàn)字節(jié)填充
- @Retention(RetentionPolicy.RUNTIME)
- @Target({ElementType.FIELD, ElementType.TYPE})
- public @interface Contended {
- String value() default "";
- }
Java8 中終于提供了字節(jié)填充的官方實(shí)現(xiàn),這無(wú)疑使得 CPU Cache 更加可控了,無(wú)需擔(dān)心 jdk 的無(wú)效字段優(yōu)化,無(wú)需擔(dān)心 Cache Line 在不同 CPU 下的大小究竟是不是 64 字節(jié)。使用 @Contended 注解可以***的避免偽共享問(wèn)題。
一些***實(shí)踐
可能有讀者會(huì)問(wèn):作為一個(gè)普通開(kāi)發(fā)者,需要關(guān)心 CPU Cache 和 Cache Line 這些知識(shí)點(diǎn)嗎?這就跟前幾天比較火的話題:「程序員有必要懂 JVM 嗎?」一樣,仁者見(jiàn)仁了。但確實(shí)有不少優(yōu)秀的源碼在關(guān)注著這些問(wèn)題。他們包括:
ConcurrentHashMap
面試中問(wèn)到要吐的 ConcurrentHashMap 中,使用 @sun.misc.Contended 對(duì)靜態(tài)內(nèi)部類 CounterCell 進(jìn)行修飾。另外還包括并發(fā)容器 Exchanger 也有相同的操作。
- /* ---------------- Counter support -------------- */
- /**
- * A padded cell for distributing counts. Adapted from LongAdder
- * and Striped64. See their internal docs for explanation.
- */
- @sun.misc.Contended static final class CounterCell {
- volatile long value;
- CounterCell(long x) { value = x; }
- }
Thread
Thread 線程類的源碼中,使用 @sun.misc.Contended 對(duì)成員變量進(jìn)行修飾。
- // The following three initially uninitialized fields are exclusively
- // managed by class java.util.concurrent.ThreadLocalRandom. These
- // fields are used to build the high-performance PRNGs in the
- // concurrent code, and we can not risk accidental false sharing.
- // Hence, the fields are isolated with @Contended.
- /** The current seed for a ThreadLocalRandom */
- @sun.misc.Contended("tlr")
- long threadLocalRandomSeed;
- /** Probe hash value; nonzero if threadLocalRandomSeed initialized */
- @sun.misc.Contended("tlr")
- int threadLocalRandomProbe;
- /** Secondary seed isolated from public ThreadLocalRandom sequence */
- @sun.misc.Contended("tlr")
- int threadLocalRandomSecondarySeed;
RingBuffer
來(lái)源于一款優(yōu)秀的開(kāi)源框架 Disruptor 中的一個(gè)數(shù)據(jù)結(jié)構(gòu) RingBuffer ,我后續(xù)會(huì)專門花一篇文章的篇幅來(lái)介紹這個(gè)數(shù)據(jù)結(jié)構(gòu)
- abstract class RingBufferPad
- {
- protected long p1, p2, p3, p4, p5, p6, p7;
- }
- abstract class RingBufferFields<E> extends RingBufferPad{}
使用字節(jié)填充和繼承的方式來(lái)避免偽共享。