Airbnb王宇:揭秘Airbnb的跨洋大數據平臺架構
【51CTO.com原創稿件】2017年12月01日-02日,由51CTO主辦的WOTD全球軟件開發技術峰會在深圳中州萬豪酒店隆重舉行。本次峰會以軟件開發為主題,數十位專家級嘉賓將帶來多場精彩的技術內容分享。
Airbnb Sr Software Engineer王宇在大數據系統架構設計專場與來賓分享了"Airbnb的跨洋大數據架構"主題演講,為大家揭秘Airbnb是如何解決大數據的存儲應用以及跨洋的數據平臺的搭建和支持,詳析Airbnb大數據挑戰和解決方案,分享如何解決大數據高效存儲和計算的過程,并了解如何進行大數據平臺的跨洋支持。
Airbnb Sr Software Engineer 王宇
Airbnb愛彼迎成立于2008年8月,擁有世界***的客戶服務和日益增長的用戶社區,在這里用戶可以通過網站、手機或平板電腦發布、挖掘和預訂世界各地的獨特房源。目前在全球范圍內擁有數千名員工,支持超過191 個國家的65000 個城市的物業租賃。隨著Airbnb的業務日益復雜,其大數據平臺數據量也迎來了爆炸式增長。
揭秘Airbnb的跨洋大數據平臺架構
大數據時代,每個公司都會遇到一些共性的挑戰,比如大數據的采集、整合、存儲、計算。Airbnb Sr Software Engineer王宇表示,Airbnb特殊之處就在于是一家美國公司,在中國就會存在數據的跨區域備份的問題。作為一個旅游平臺,Airbnb會存儲一些和個人相關的信息。中國的研發團隊不僅需要在***可能的程度上使用中國本身還有國際的數據,還需要保證數據的安全性和使用時的延時。
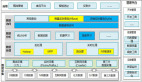
基于這些挑戰,Airbnb構建了一套從數據采集、數據整合、數據清洗到數據瀏覽的一套系統。在global,整個架構采用了兩套獨立的Hadoop集群,分別為Gold集群和Sliver集群。
所有的原始數據都會先導到Gold集群里面,Gold集群負責數據最初的清洗和整合,等這些數據清洗整合好之后,再把這些數據傳輸到Sliver集群。在這兩個集群中間,Airbnb通過自己研發的一個名為Reair的系統 ,可以保證兩邊的數據完全一致。如果Gold集群中的數據有一些變化,也會很快會反饋到Sliver集群。
王宇指出,設計兩個獨立的集群的優勢就在于用戶作業的錯誤隔離,方便容量規劃,保證SLA,易于測試新版本,災難恢復。而劣勢在于不利用戶容易混淆,數據同步還需要單獨開發ReAir以及運營成本。
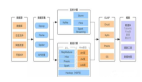
在中國,Airbnb新建了一套和global類似的大數據系統,中間是由AWS S3作為數據的通道,由于AWS有跨區域備份(Cross-Region Replication ,CRR)功能,可以便捷地進行備份。
通過大數據平臺的構建,幫助Airbnb成為一家數據驅動型公司,凡事以數據說話。通過數據分析能夠為用戶提供***的旅行體驗,基于數據做出正確的產品決策。收集指標,通過實驗驗證假設。構建機器學習模型和挖掘商業機會使得Airbnb公司高速、靈活的成長。
構建跨國大數據平臺,合規首當其沖
Airbnb在大數據平臺架構構建的過程中,也收獲了很多寶貴的經驗。首先,多關注開源社區。在開源社區有很多大數據架構方面優秀的資源可以采用。其次,多采用標準組件和方法。有時候自己開發并不如使用已有的更好資源。第三,確保大數據平臺的可擴展性。當前業務數據呈現爆發性增長,因此要確保產品能滿足業務的增長。第四,多傾聽同事的反饋來解決問題。第五,預留多余資源。
針對構建跨國大數據平臺需要注意的問題,他談到,要從法規、流程、技術、整套系統上做到可靠。首先最重要的是法規,要了解在跨國支持的時候在法律法規上將面臨限制和挑戰。其次,一定要有一套可靠的數據通道。第三,整套系統要設計的通用一些,因為要從global導入很多不同的數據。同時,一定要做好監測,哪些數據能出哪些數據不能出,包括兩邊數據的一致性。
***,在談到未來規劃時,王宇表示,由于業務對數據增長不是線性的,可能是呈指數級增長,因此,一定要進一步提升大數據平臺的能力,特別是加強在不同場景下的機器學習的能力。同時,對于新技術、新產品要時刻保持一個開放、樂于嘗試的心態,才能讓Airbnb的大數據平臺更上一層樓。
【51CTO原創稿件,合作站點轉載請注明原文作者和出處為51CTO.com】