騰訊社交網絡運營部助理總經理趙建春:如果運維可以重來一次
原創2016年4月14-15日,由51CTO傳媒主辦的WOT2016互聯網運維與開發者大會在北京珠三角JW萬豪酒店召開。秉承專注技術、服務技術 人員的理念,自2012年以來,WOT品牌大會已經成功舉辦了八屆,積累了大量的技術專家資源,獲得了廣大IT從業者和技術愛好者的一致認可,成為了業界重要的技術分享交流平臺以及人脈拓展平臺。
本次會議分為11個技術主題,分別是:數據庫技術與應用,大數據與運維,云計算與運維,運維安全,移動運維,容器體系構建與實踐,運維自動化,行業運維、監控與性能優化、高可用架構和分布式存儲技術。51CTO作為本次大會的主辦方,將以快速報道、現場專訪與后期視頻等形式展示這場盛宴。
下面是來自騰訊社交網絡運營部助理總經理、技術運營通道會長趙建春先生給大家帶來的是主題為《如果運維可以重來一次》的精彩演講。

趙建春,騰訊社交網絡運營部助理總經理、技術運營通道會長、專家工程師。04年加入騰訊,先后從事過研發、運維、數據方面的建設和管理工作,在海量技術運營方面積累了豐富的實戰經驗。
【以下為現場演講實錄】
大家上午好!非常榮幸今天有這個機會在這里給大家做分享。我分享的題目是如果運維可以重來一次。我04年加入騰訊,加入之后做過賀卡的開發,05年的時候,非常榮幸加入QQ空間的開發團隊,負責留言版模塊的開發。06年底開始隨著公司組織架構變化,開始接觸運維這塊的工作,到現在有10年時間,是一個10年的運維老兵,現在在社交網絡負責大數據和運維工作。
介紹一下我們的運維團隊,主要是負責以QQ延伸出來的各種社群的運維和維護,包括QQ空間、QQ音樂、QQ會員、QQ秀等一系列的QQ產品。我看了一下,真實員工89個人,加起來外包同事,我們維護了10萬家服務器,維護的能力和谷歌比起來還是有差距,但是對很多傳統企業來講,已經是非常不錯了。
團隊也經歷了非常多事件和活動的洗禮,比如說對空間的紅米首發,讓紅米在我們的QQ空間上90秒賣出10萬臺設備,獲得1億點贊。去年8月份天津大爆炸事件,我們也是把我們天津2億多活躍用戶,從天津快速調到深圳以及上海,可能在中國互聯網史上,可能是一個從來沒有發生過的這么大規模的調動。
第三是支持了兩次春節紅包準備工作,尤其是今年比去年的紅包訪問量增加了10倍以上,快速的擴充了5000臺設備,前段統一機構部署,最高訪問量達到477萬次每秒。還是一個比較值得信賴和可靠的團隊。
今天為什么是這個題目?我自己和我的團隊在運維這一塊的工作已經經歷了10年時間,在這10年之內,我們在想回顧一下,如果回顧過去10年工作,如果我們有一次重來的機會,什么才是對我們最重要的?什么是我們團隊優先做好的一件事情?然后思考,然后再去深思,支撐我們更好的前行。
作為運維團隊來講,最最重要的事,首先讓自己做的系統可靠、要不容易出錯,不要讓自己變成一個救火隊員。可靠之后,才會有更多時間解決我們的效率,讓自己的工作變得更加高效,再追求喝咖啡這樣的事情。
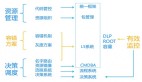
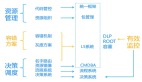
什么對我們的工作幫助最大?從這個圖上來講。我們寫出來的程序和代碼,包括現在運行的實例都是我們管理的資源,這個資源能不能進行一個清晰的劃分和分類,對每個資源能不能有一個形狀,然后進行搭建。我們維護海量服務,在運維過程中出現故障能不能影響項目服務,讓我們服務器及時處理,所以容錯方案是非常重要的,我甚至覺得是第一步的。
我們管理的資源清晰的分分類,同時有不同的形狀,我們要進行各種各樣的擺放,搬遷或者是調度的時候,有一個比較流暢的系統去做這個事情。
我們通過什么東西來做的?用統一框架,CMDBA,把一個業務模塊上所有依賴資源全部登記進去。同時如果做快速決策和調度,還需要有效的監控,今天時間關系,監控這塊不展開講了。DLP就是我們內部定義的一個非常關鍵的監控,這個點發生了以后,就知道哪里出故障了。第二個是入口監控,到底是什么根源導致了這次故障。再就是容量管理的幫助,后期如果有同事分享,大家可以再關注。我們的容錯方案的L5是幫我們解決了容錯、灰度,名字路由的功能。
世界管理服務器最多的系統是什么?是運營管理系統,大家可能不會有太多意見,因為它管理了上億服務器,脈絡非常清晰,根本不會出現混亂。我們L5系統也類似于DNS系統,底下有一排能提供的服務模塊,從而解決的單點問題。
它怎么做容錯?L5有兩部分,一個是L5和DNS,另外一個是L5和agent。CGI通過給這個模塊提供一個ID,然后根據模塊以下設備的成功率和延遲情況,給我們一個回饋,訪問完之后,通過成功率和延遲情況,把數據上報給了L5 agent,然后有一個統計數據。當發現失敗率特別低的時候,就踢掉。如果發現成功率和失敗率有一定下降,會把訪問權重降低,從而達到容錯和負載均衡的作用。
我們可以注冊一個模塊,加多臺設備,形成容錯效果。如果發現一臺機器失敗率很高,就把它踢掉。它的成功率恢復過來,我們還可以再加回來。
我們新加一臺服務器設計它的權重為1,假如之前的是100,我們可以逐漸上線。我們還可以給它一個得分,得分下降的時候,快速把它踢掉。
L5對運維團隊的幫助是最大的事情,幫我們解決了日常工作中大量單點故障,早期做開發的同事都知道,非常習慣用一個ip+Port處理故障,它也解決了這個問題。
同過名字便利的服務上下線,可通過權重灰度上線。模塊訪問關系可幫助定位根源故障,接口的延遲和失敗率可用來監控,它是集容錯、負債均衡、路由、灰度監控能力于一身的,所以對運維的幫助非常大。
統一框架和架構。我們團隊里面有上千號開發同事,每年有大量畢業生加入,也會有社交同事。他們進來以后,都希望在我們平臺上做很多代碼的貢獻,或者展現一些技術實力,或者提高自己。問題是我們的開發里面,我們有管道、消息隊列、信息文件鎖、記錄鎖、文件影射內存,還有迭代服務器Select poll Io等,我們用各種各樣技術組合生產出來的代碼,交給團隊維護,數以萬計不同性格的服務器,要掌握得非常好,能了解它的工作機制和原理,更好的維護它基本上是不可能的事情,所以我要求把這個框架的部分,也就是網絡通訊的部分,列成一個標準框架,提高它的通訊效率,統一維護。業務邏輯部分以SO動態庫方式編寫,與框架分離部署,類似WEB服務器上的CGI。接入層用QZHTTP,邏輯層是SPP和SF的框架。
我們社區類服務,用戶的熱點并不是很集中,數據量、訪問量還是很大的,我們大量的是用CKV存儲,同時還有一個訪問量非常大的,比如說一個用戶沒有開通空間,甚至是一個游戲用戶,他甚至是會員等等的標記,有一個定位就可以了,形成一個高訪問量的模塊。
這樣一個架構體系,接入層是TGW,流量從它進、從它出。對于中間層,我們L5進行一個這樣的調度,在存儲層,因為每一個存儲模塊要分耗段,我們加了Access,從上到下把技術架構進行了統一規范,同時在組織上也通過接入邏輯運維層,進行標準化的維護。框架的統一大大減少了運維成員學習的成本。框架不斷的提高,不會說大量的服務器交給我們出現各種不同故障的可能性,可以極大的提高我們的工作效率。
對我們開發出的程序包進行了一個標準打包操作,一個程序開發出來有不同特征,有的需要加銀行參數,有的需要依賴目錄,有的需要前面的準備工作和后續的善后工作,我們把它全部放在一個類似于包里面,裝進一個盒子里,我們提供標準的操作接口,比如說安裝、卸載、啟動、停止這樣的操作,讓它變成一個關聯的操作。
再也不會擔心說,你不會操作這個接口。早期的時候程序開發出來,目錄都不知道放在哪里,故障的時候都找不見,類似這樣的問題再不會發生。還可以幫我們做很多善后和準備工作。進程級運轉的所有資源都在盒子里面了,不用擔心跑不起來。因為一個進程要運行起來,還不足以提供整體服務,我們要提供整體服務應該是同一個模塊提供,這個模塊需要幾個整體服務來進行組合,還要依賴其他的資源,我們會把這些資源形成一個虛擬的鏡像。
比如說這個業務包,有可能有一些基礎包,有一些配置,還有一些目錄文件,還有權限。權限是騰訊獨有的,有些公司有,有些公司不會有。騰訊的業務,比如QQ關系鏈是非常敏感的,所以我們內部采用互不信任的機制。機器不能隨便標記這個用戶是會員用戶,或者說是一個特權用戶,一般都是采用互不信任的機制,所以在發展過程中,逐漸出現了要授權的模塊,而這個模塊需要我們去線下發郵件走流程申請,或者在線上走一個電子流審批,這時候就有人介入了。我就不展開講了,因為它對我們很重要,但是可能在小公司或者一些傳統企業并不會存在。完成這樣一件事情以后,我們就相當于把這個模塊運行的完整資源依賴全部裝箱操作,進行整體完整的部署,這樣會導致我們不再需要類似以前老是要提供什么模塊的使用文檔、說明書這樣的事情,就非常容易操作了。
之后做變更就會非常容易。我們有一個內部的織云自動化部署平臺,第一步申請設備獲取資源,發布部署,然后檢測,檢測完之后進行測試,測試之后就可以上線。每一步里面,還有一些細節的步驟,比如說這么多步。比如說申請設備的時候要屏蔽告警事件,發布的時候要同步傳輸文件,發布之后要檢測程序的包進程是不是啟動了,啟動之后進行業務測試,然后進行慢慢上線。
這就是我們織云內部自動化部署的平臺,我們相當于把這個進程開發出來以后,依賴的資源全部打包放在盒子里,把盒子里的東西放在我們的資源倉庫中,有一些模塊全部登記在CMDB。如果我們要部署一個模塊A,或者說進行擴容,可能是人工觸發,或者自動系統觸發,控制人工系統進行操作,把模塊邊上三個資源,由資源倉儲部署在模塊1上,通過L5系統進行一個注冊,這個模塊就自動上線了。我們還有一個容量監控的監控體系的介入,今天就不展開了。
我們會把一個模塊登記回來,可以對它進行自動化的操作,每一個方塊是一個步驟,這個步驟執行過去之后就是綠色的,執行失敗就是紅色,或者沒有執行的就是灰色的。執行成功之后,可以看到,我們可以做自動化的擴容,可以做一些日常的演習,還有一些回收等等這樣的工作。
走在這一步的時候,我們看到整體的過程,看起來還是比較自然而然的過來。但是實際上這個事并沒有這么容易做,它是這樣的發展歷程,我們的打包規范在06到08年進行推廣,那時候開發代碼必須要打包,我們會做專職打包。08年到2010年組件標準化,只能選擇一種服務,當然也有其他,你選擇其他就會非常麻煩,你需要寫為什么,還需要一些審核,當然一定會有特例,所以這個特例就會盡量避免和減少。我們現在有一個業務團隊就是維護特例的服務性,維護能力非常低,一個人可能只能維護幾百臺設備,但是標準模塊可以維護上萬臺設備。2010到2013我們一直在進行L5容錯和名字服務。2013年到現在在做資源登記權限中心和智能化自動化。我們能不能把08年到2010年,2010年到2013年,2013年到現在的事情,全部放在05到08年的時間?08年到現在就有8年時間做智能化、自動化的工作,處在什么樣的自動化的水平,這是非常讓人振奮的,所以才會有這樣的感觸。
運維最難解決的問題是什么?就是歷史問題。每個團隊都會遇到自己的歷史問題,我挖了一個坑,又出來一個坑。講一個案例,這個事情,看起來和我們講的內容沒有什么關系。美國有一個西南航空公司,1971年成立,現在是美國第二大航空公司,大概有600架飛機,國航是590多架,它的市值是280多億美金。最大成績是連續33年持續盈利,包括911恐怖襲擊之后,美國大批航空公司倒閉,它還可以盈利,非常的平穩。它在創始之初就做了一個決策,只購買播音737-700型飛機,用網狀去樞紐化的營運策略,目的就是高效運營起來,不去中心樞紐型的地方排隊,飛機也是中小型飛機,這樣就可以看出來,它最初的頂層設計,就是比較高效的運作方式,也是未來過程中產生立于不敗之地的情況。
雖然我們的團隊不能重來一次,現在有很多創業團隊,有很多新項目,我們能不能在最初的時候,就有運維和開發共同參與制訂這樣一些,對未來運維工作有預見性的規范規則,最后再由開發把它根基打好,開發對用戶的幫助非常大,一定是運維和開發深度配合合作,才能打造高效運維基礎,達到一個高效的效果。
云計算是這幾年發展最快的一個產品,而且我們相信它也一定會是我們在IT領域未來的一個大趨勢,同時再一個標準這樣的東西,一定程度上和高效、可靠一定是同義詞。我相信云計算未來一定會成為超級標準,它是把IT領域里面的各種問題的解決方案逐漸的通過整個行業的智慧,把它最終形成一個統一的解決方案。
騰訊也有騰訊云的服務,我們騰訊云現在也是業界領先的公有云的服務商,經過過去幾年發展,尤其是去年翻倍式增長,目前全球有50家數據中心,有500家數據加速節點,超過10T整體帶寬,4T防DDOS攻擊能力,700萬+域名提供解析。我們也希望各位同事可以關注騰訊云,支持騰訊云,謝謝大家!
以上是51CTO.com記者從一線為您帶來的精彩報道。后續我們還有更加精彩的獨家報道,敬請關注。