













奇云諾德CEO羅奇斌:解讀測序密碼與基因大數據
原創解讀測序密碼是開啟大健康領域的鑰匙,高通量基因測序為快速邁入精準醫療時代提供了希望,但測序只是第一步,僅僅是得到了基因數據而已,還需要精準解讀隱藏在基因大數據中的密碼,才能真正揭示發病根源。
奇云諾德CEO羅奇斌表示:“在基因信息化時代,有兩個很明顯的標志:一個是基因數據搜索引擎的出現,另一個是基因產品的封裝和實用性不斷提高。基因信息化的形成需要對基因大數據的接入和搜索進行重新的定義。在生物信息技術和互聯網技術的推動下,計算機對基因大數據的挖掘和解讀正變得日益人工智能化。 ”
基因組有多大?基因數據研究有多重要?基因行業市場現狀如何?
基因組有多大?每一個人的字母有30億個,一個字母八個字節,也就是說一個人的數據量大約是3G。存儲時要乘30倍重復,一個人最終原始數據是100D,可以擴充到1T的空間。
基因數據研究有多重要?基精準醫療里面最關鍵的是精準,而不是醫療。現在提倡的精準醫療中醫療是傳統行業,精準是大數據行業。羅奇斌表示,通過對基因數據的研究,可以不通過影像學,僅僅通過一滴血就可以判斷你是否得了腫瘤。當前已有基金數據,未來就不需要去存儲這些影像學,也許每天抽一滴血就可以來做預防,而不是診斷。診斷是出現癥狀去看病。但是從現在開始,一個人一出生就可以做預防,做健康管理。
基因行業市場現狀如何?最早做一個人的基因組需花38億,平均下來一個字母生產出來需要1美金。現在產出100個D的數據需6500塊錢人民幣。IT界對這些數據進行分析,每分析一次收三千。于是就有了測一遍讀萬遍的商業模式,數據只有讀取它,對其進行計算才會有價值。當下每一個人的基因組測序成本不到萬元,精準醫療也隨之火熱起來。中國14億人,接著每一個人的基因數據要讀幾遍。如一個應用都讀一遍要付1000塊錢,那么當一個每一個新的應用對這些基因信息的重新信用挖掘進行分析之后,產生價值我們是沒有辦法衡量的。但目前要做的就是讓每個人先有基因數據,還沒到數據變成信息,信息變成知識的過程。
什么是基因?基因可以決定哪些事情?
上面提到了基因數據研究的重要性和未來優越的市場前景,下面我們來看看之所以選擇深入研究基因數據的根本原因。那什么是基因呢?基因就是在DNA序列上,有用的信息并且能夠行使生物學功能的那部分那一段區域稱之為基因。
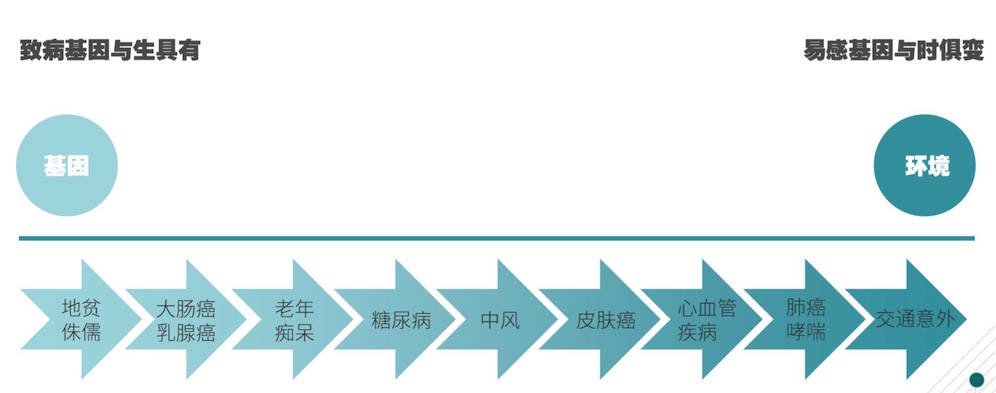
致病因素
人之所以會生病,有一部分原因是由基因導致的。基因好比是在建一棟之前的圖紙,建完這棟樓其實你已經知道這棟樓哪里是停車場,哪里是商鋪,哪里是游泳池。所以基因可以決定我們的各種特征,父母通過基因特征轉給后代,可以決定營養吸收的能力。所有疾病的發生都與基因密切相關,是內外(遺傳和外界環境)因相互作用的結果。我們身體里致病基因與生俱有,易感基因與時俱變。羅奇斌表示,現在該公司已經做出精準模型,能算出大概多少個月之后準確得到某種癌癥,而不是概率,這個已經全部做完。精準醫療的最終目的是為了人類的健康,想要做到精準理療定離不開基因數據。
數據從哪來?需要什么數據?如何解讀數據?
基因數據從哪來?羅奇斌表示,測序儀是基因數據的來源。目前全球一共有7389臺高通量測序儀,分布在1027家機構,平均每家機構擁有7.2臺。從lllumina進入市場以來,基因預測費用的下降速度遠遠超過按照摩爾定律預測的價格。
需要什么數據?羅奇斌表示,如整個生命體是個網絡,每一個人的基因跟其它另外的基因是有關系的,每一個蛋白質跟其它蛋白質有關系的。可以算出來從一個蛋白質到另外一個蛋白質之間有最短的路徑,這個路徑應該是自然選擇形成的。可以用數學的算法去模擬它,模擬的過程就是優化過程。可以把一個在大型機里面能夠算幾十年蛋白質結構的網絡縮短為一分鐘。那么就可以及時反饋,可以迅速算出在一個網絡里面共進的一個蛋白應該要藥廠去設計一個藥靶,所以這就是賺錢的地方。回到IT,就是建立一個簡單模型。這樣就可以看到任何生命的數據可以被量化,整個生命被量化以后可以清晰的知道每一個數據,從DNA到INA到蛋白質,到細胞,到組織,到系統,到個人,但現在只做DNA。因為整個醫療數據太復雜,在這些數據中,最分析容易就是DNA。通過測序儀來側基因,有哪些數據是可以測出來的呢?
什么是基因檢測,就是從血液或從其他體液細胞中檢測一個人DNA的技術。基因檢測可以指導生活健康、及時診斷治療、預防疾病、節省醫療為用。
基因檢測流程
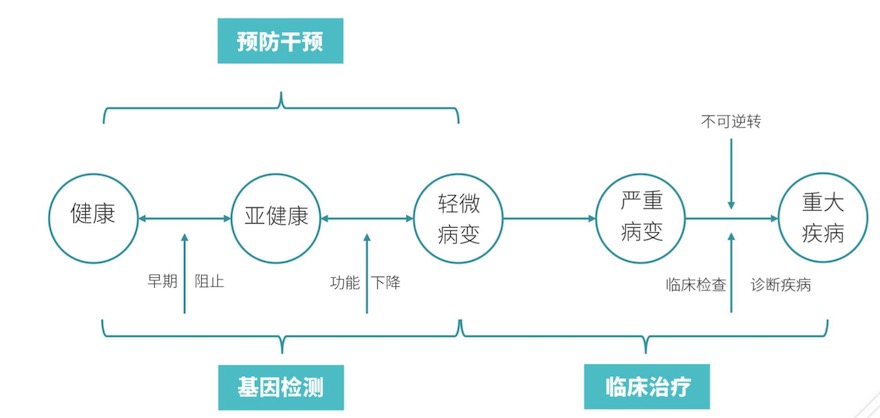
基因檢測的顯示意義
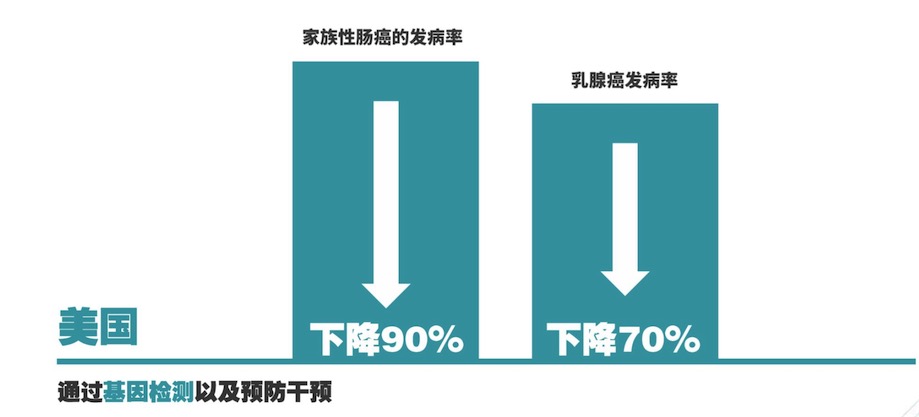
基因檢測應用成果
數據怎么去解讀?數據流的產生需經過Data-Information-Knowledg,如下圖。在這個過程中,需要一個體系的建立,一個生態環境的成熟。
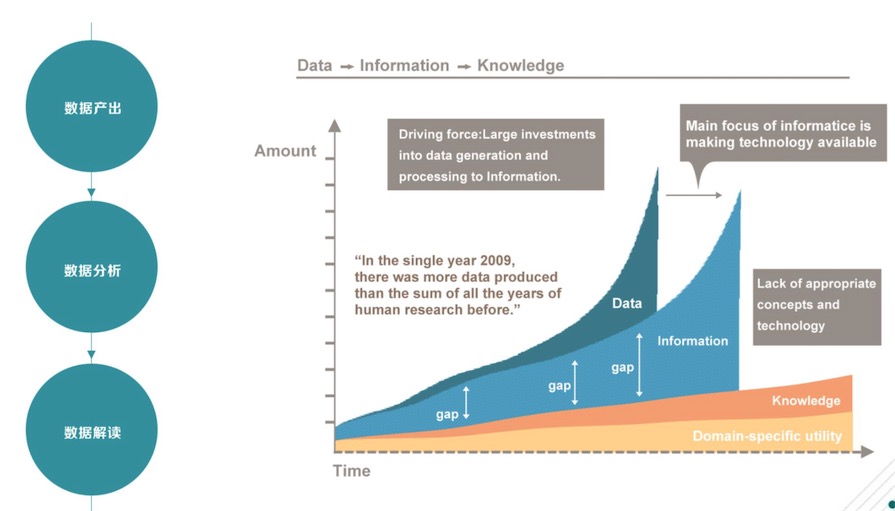
Data-Information-Knowledg
羅奇斌表示,目前生物信息的人很難找到,基因行業格局未定。還出現了基因信息太冗余和解讀跟不上的瓶頸。解讀跟不上取決于數據分析沒有被封裝模塊標準化。針對這個情況,可以對基因行業產業鏈細分,最終實現精準數據挖掘。但這個過程就需要一個的數據引擎來做支撐。
關于奇云諾德搜索引擎
奇云諾德重新定義了搜索引擎,使其場景化和多維化。多維的數據交付給行業專家在特定場景下發揮有價值的應用。
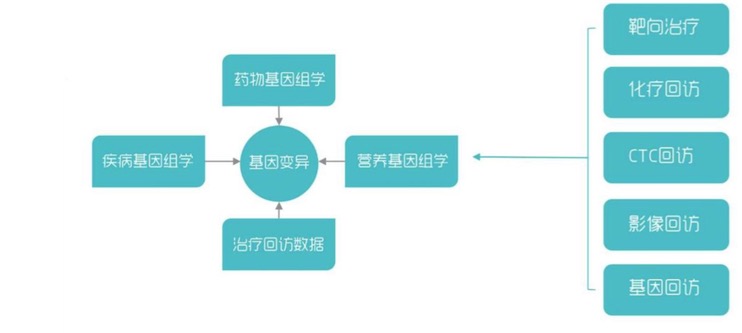
數據庫構成
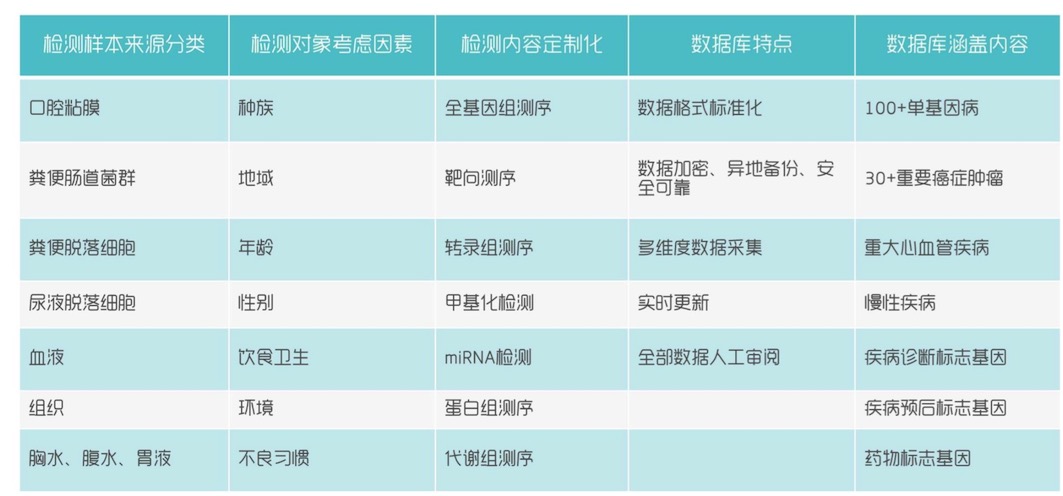
數據庫特點
奇云諾德整個數據庫有多年的積累,可以對不同的數據類型以及這種基因,從不同的組織和細胞里面去產,最后進行一個不同的分析。在這部分羅奇斌舉了幾個案例有藥物研發與基因大數據、耳聾基因檢測策略等。
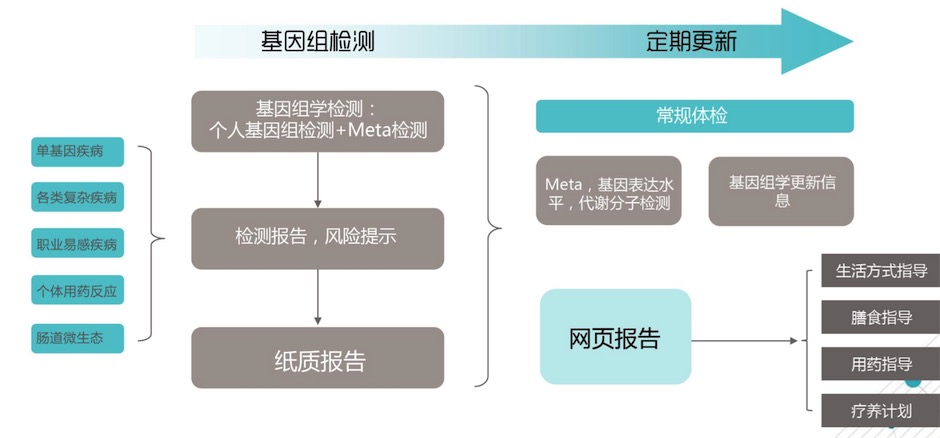
個人健康管理
個人健康管理有各種各樣的端口輸送,每一個都會給大家提供,包括大家的API接口對接的是APP,包括大家的網頁經常看的侵入式,可以侵入到你的網站上去,直接可以看到有個模塊。

腫瘤個體化醫療方案
腫瘤個體化診療的模型,包括剛才講的人的全基因測序測完之后是30億字母,一共是100據的數據。針對這么大數據量,可以把全部分拆,做成分布式。
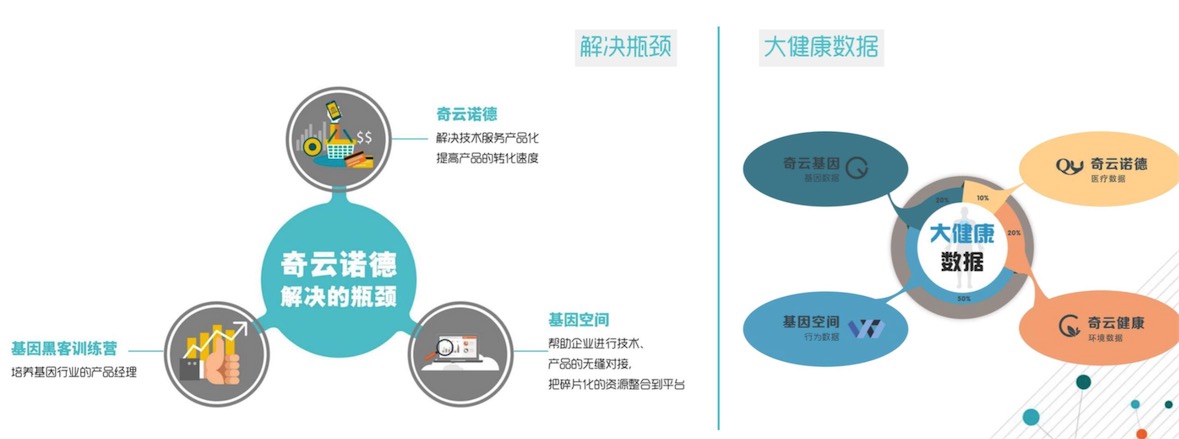
奇云諾德解決的痛點
最后,羅奇斌簡單的介紹奇云諾德,該公司的定位是分析引擎。通過引擎去理解整個大健康數據會不同的場景應用,向各種的企業級別提供服務,有提供API接口給行業需要者使用,有針對不同產品產品提供對接,還有可以提供產品轉化的服務。同時歡迎更多IT的人進入到領域,希望從IT領域的人直接培養成為一個基因數據挖掘師。
本文整理自【WOT2015”互聯網+”時代大數據技術峰會】期間,奇云諾德CEO羅奇斌主題為《解讀測序密碼——基因大數據解讀》的演講。
講師簡介:
羅奇斌,奇云諾德創始人,《互聯網+》叢書聯合作者和《互聯網+基因空間》主編。中信出版社《互聯網+醫療》聯合作者。貝殼社BioMan成員。基因空間微信公眾號和基因世界APP的內容主編, 2007年獲得浙江大學沃森研究院生物信息學碩士學位,2008年獲得德國DAAD全額獎學金赴慕尼黑工業大學生物信息學系攻讀博士學位,專注于二代測序技術和互作網絡在基因數據中的應用。2014年離開中科院創辦奇云生物 (QY Genomics)和奇云諾德 (QY NODE),專注于通過互聯網技術和生物信息分析技術幫助每一家生物企業,打造基因行業的工業4.0。












