CTO訓練營胡偉:百度大數據布局旅游、金融、醫療領域
原創百度研究院大數據實驗室數據科學家胡偉在由51CTO高招主辦的“CTO訓練營第四課百度技術專場”做了主題為“百度大數據在旅游、金融及醫療領域的應用”的分享。從技術角度深入地剖析了百度大數據在當今三大熱門領域:旅游、金融、醫療的應用。
【講師簡介】

胡偉 百度研究院大數據實驗室數據科學家
百度研究院大數據實驗室數據科學家,分別于2005年和2011年獲西安交通大學學士及博士學位,2009年至2011年在麻省理工學院認知科學實驗室任訪問學生。加入百度前,曾在微軟亞洲互聯網工程院從事搜索廣告和機器翻譯相關研發,擁有多年大規模機器學習和數據分析經驗,研究興趣包括自然語言處理,計算廣告學,深度學習等。
百度作為全球***的中文搜索引擎,沉淀了其他傳統數據平臺無可比擬的海量數據。基于大數據分析技術,百度開放了大數據引擎,與政府、醫療、金融等傳統機構率先展開合作,并逐漸向各個行業滲透、擴展。胡偉老師本次的演講涵蓋了百度大數據技術在旅游、金融及醫療領域的探索,以及深度學習技術在大數據分析中的應用。
百度大數據在旅游領域的應用
應用實例
2014年9月份某旅游景點出現游客爆滿滯留,帶來了很大的安全隱患,旅游人流量預測問題再一次引起了全民的關注。
旅游人流量預測一向是旅游行業的重大課題,尤其是對旅游管理機構以及目的地企業而言,對未來做到“心中有數”,無論對旅游行業宏觀把握和調控,還是對目的地營銷活動的引導,以及對旅游人流流向和流量的調整,都具有很大的現實意義。百度大數據對此問題有專業的工具來解決。
通過百度關鍵詞搜索日志可以發現,事發前一個周末,這個景區有非常高的搜索量,并且搜索的用戶都是周圍的居民,這說明,這些用戶去的可能性極大,進而可以預測到未來的一兩個周末,這個景區的人流量會很大。這就是基于時間和空間的一個簡單預測。
技術要點
百度大數據來源主要有兩個方面:一是網民的廣義搜索行為;二是百度的LBS數據,這些數據基本涵蓋了游客旅游活動中和外界的信息交互行為,同時旅游業的信息密集、產品固定、移動消費等特點,無疑很大程度上契合了百度大數據的特點。

圖1:時間序列預測的基本方法
除了季節性,天氣、是否節假日等因素也影響著人流量,所有這些特征融合在一起就可以做出一個比較準確的預測。如下圖所示。
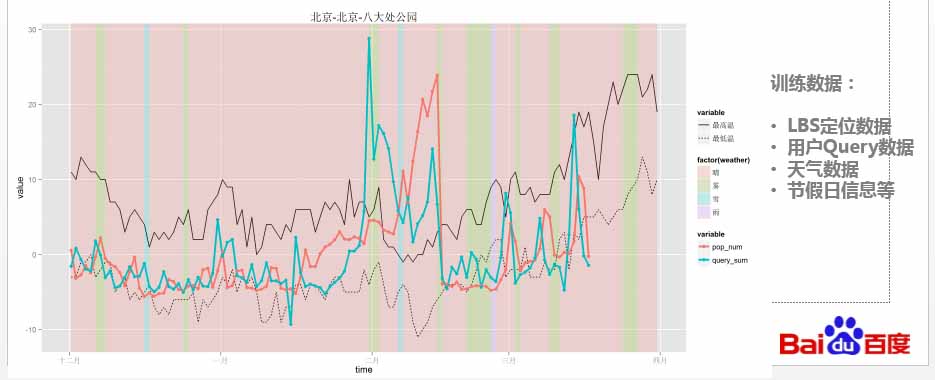
圖2:景區客流量預測
藍線代表搜索日志量,包含用戶搜門票、路線等信息,紅線代表實際旅游人數。這是一個傳統的模型,即用***個時間點預測第二個時間點,依此類推。
基本模型如ARMA,ETS等過于簡化,使用范圍有限,并且,由于時間序列的特殊性質,標準的機器學習模型難以直接應用。這就要求有更先進的模型來進行更精準的預測。即:動態空間模型State Space Model (SSM)。
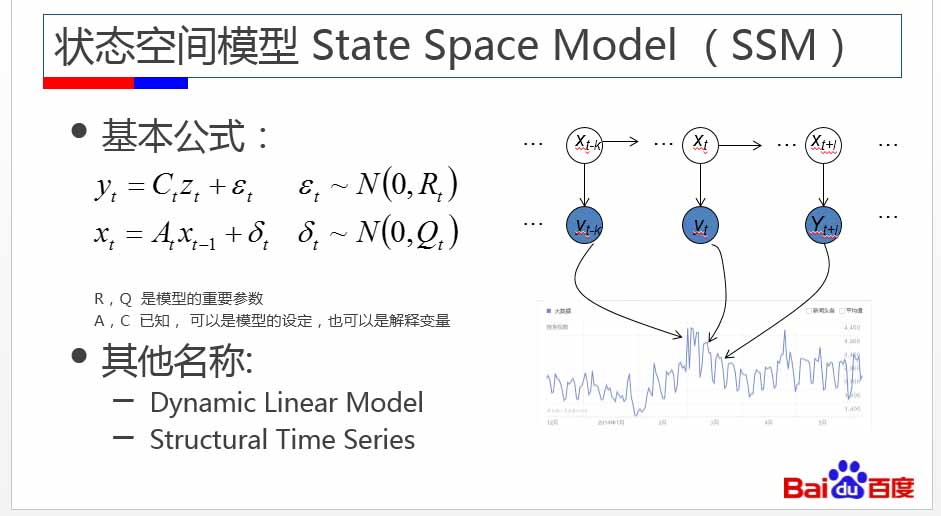
圖3:狀態空間模型
簡單地說,y是觀測的人數,當我們要預測y時,影響y的有很多因素,即內部狀態,如天氣因素、搜索因素、GPS定位的人數等,此模型可以把這些因素都隱含進去,然后通過動態的方式來預測每個時間點上的人數。這里的時間序列,是一個動態的模型。
目前,百度已經有了成熟的產品上線:trends.baidu.com

圖4:旅游預測與狀態空間模型
百度大數據在金融領域的應用
首先,胡偉老師明確了一點:我們做的不是風控方面,而是投資方面。百度大數據在金融領域的應用主要基于兩種形式:用戶數據分析和高斯圖模型關聯挖掘。
用戶數據分析
用戶關注某個事物或者心里想什么,會在互聯網上留下一些信息,比如搜索某個公司、新聞信息,或者直接搜索某支股票,這些都可以或多或少的反映出他的投資傾向。
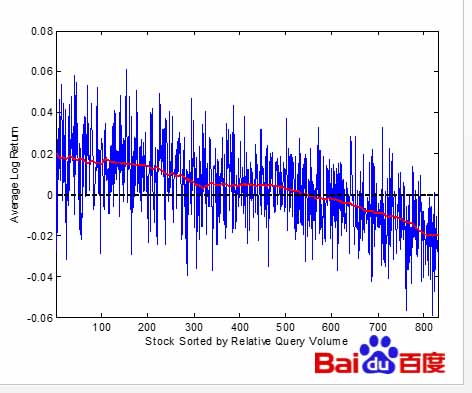
圖5:用戶數據分析
這張圖顯示了一個很有意思的現象:哪個公司的搜索率高,往往這只股票就會跌。這是什么原因呢?用戶其實不會平白無故的搜索一只股票,或者說每個公司的搜索量應該差不多,但是當出現一些負面新聞時,比如破產或者法人出現什么問題,就會有很多人搜索。這一搜索,其實已經相當于一個預警,這個公司的股價有可能會受到負面消息的影響。
金融工程中的數據分析多基于小數據(高頻交易除外),模型評價主要以回測模擬實現,無法直接應用機器學習算法。百度金融大數據基于Query的等權重指數,可以很清晰地顯示出這些變化特征。
高斯圖模型關聯挖掘
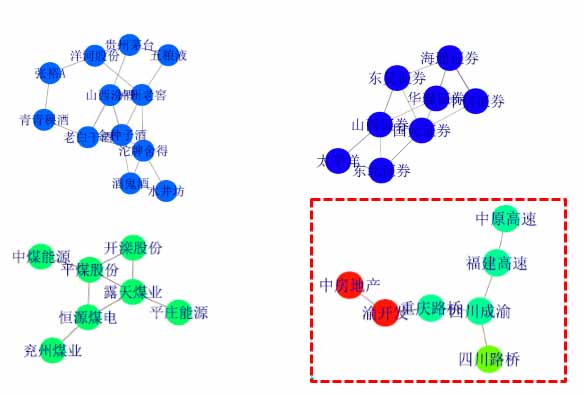
圖6:高斯圖模型關聯挖掘
高斯圖模型(Gaussian Graphical Model)
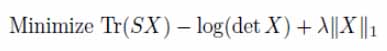
其中,S為樣本協方差矩陣,X為所求的偏相關系數。基于高斯圖模型挖掘出的股票聯動圖如圖6所示。
具體來說,各個股票之間會有一種內在關聯信息,比如說行業中上下游的關系,鋼材、石油、化工這些都會有一定的關聯。這種關系有的比較直觀,有一些比較滯后,百度通過數據挖掘的方式找出了這種規律,進而對整個金融市場做了一個全新的版圖。
百度大數據在醫療領域的應用
現狀
艾瑞咨詢2015的調查結果顯示:有89%的用戶生病***反應是進行互聯網咨詢,百度疾病、癥狀類的檢索量是平均每天4億。
醫療資源比較匱乏,掛號排隊等是當今醫療行業的現狀,百度內部很早就開始關注如何用新的技術手段改進這一現狀,百度采用的方法是機器學習。
深度機器學習
傳統的數據挖掘時一般用文本分類,即情感分析:當客戶用一段話描述一個癥狀時,會被打上標簽,根據這些標簽,建議用戶去哪些醫院或者科室檢查。這種傳統方法的缺點主要有兩個:一是BoW丟失了詞序等重要信息,二是無法對復雜的非線性關系建模。Word Embedding的缺點是運算量大,embedding過程損失原始文本信息。
百度采用的是基于稀疏特征的CNN,具體來說,就是讓機器自己找出數據內在規律,不對其做人工設置。并且,采用GPU加速,比CPU快了10倍以上。

圖7:基于稀疏特征的CNN
通過搜索流量來獲得用戶疾病數據,通過人工智能有效地挖掘相關數據,百度的疾病診斷和科室診斷都達到了很高的準確率。
***,胡偉老師例舉了一些上線產品:百度健康PC端、百度健康移動端、百度醫療助手DuNurse。
結語:
百度大數據建立在搜索的基礎上,擁有龐大的用戶群和很強的用戶黏性,使用人工智能挖掘技術對數據深入剖析,把智能硬件資源整合,這些優勢都驅動著百度一步步向各個行業滲透。