機器學習應用實例|如何識別標題黨?
相信你也遇到過這樣的情況:懷著猶如探秘般萬分期待的心情,點開一篇文章,結果卻發現又一次中了“標題黨”的誘餌,成功上鉤。這種現象,在國際有一個形象的名字 “Clickbait”。
“Clickbait”則被定義為引誘人進入某網站的標題誘餌。Facebook、谷歌自2014年末就開始了對“標題誘餌”的識別,并且在最近宣布減少該類新聞出現在新聞摘要中。因此,準確的識別出作者所寫的文章是不是標題誘餌就顯得尤為重要。
標題誘餌一般有哪些特征
先讓我們來看看一些點擊量較高的、典型的標題黨:
· 關于新iPhone,10件蘋果公司不會告訴你的的事
· 接下來發生的一切將會讓你大跌眼鏡
· 90年代的演員是什么樣子的
· 特朗普說了奧巴馬和克林頓什么
· 成為一個好的數據科學家必備的9個技能
· 擁有iphone如何提高你的性生活
從這些標題中我們似乎可以尋找到某些模式。趣味性和模糊性是這些標題的主要特點,看到這些標題,我們就不自覺的想點開看看這些文章到底要說什么。當然,通常情況下,文章的內容會讓你很失望。
一些小的網站依靠標題陷阱獲得流量,就連一些較為受歡迎的新聞網,如Buzzfeed也被冠以標題陷阱集散地的稱號, 正如“今日頭條”在App store的遭遇一樣,隨著谷歌和Facebook對這類文章采取的一系列措施懲罰,這種現象還會持續多久?
識別標題誘餌
不同于其他應用機器學習的文章,這篇文章將不包括機器學習的基礎,我們直接進入主體的分析部分。
1 創建數據集
為了識別clickbaits,我們必須先從一些新聞網站抓取一些標題,并創建兩個相對的數據集:一個為clickbait標題數據集,包含十萬條數據;另一個為non-clickbait標題數據集,包含五千條數據,以此形成一個監督學習問題,即用non-clickbaits數據集對clickbaits進行類別判斷。
2 數據集特征分析及模型訓練
在創建好數據集之后,我們將對不同的數據集進行特征分析,并用機器學習算法進行識別模型的訓練。
詞頻-逆向文本頻率(TF-IDF)
TF-IDF是一種用戶信息檢索與數據挖掘的常用加權技術,用以評估一個字詞在一個文件集或一個語料庫中的重要程度。在這個方法中,我分別對字符和單詞進行分析,并且運用 n-gram模型的(1,1),(1,2),(1,3)。接著,我們用scikit-learn這一用于機器學習的python模塊來實現以上算法。
字符分析器如下:

詞語分析器如下:

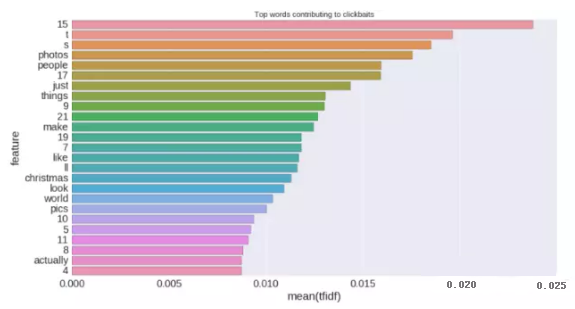
TF-IDF向量分析器非常強大,能清楚的告訴我們哪些字符、單詞在clickbaits中的出現的頻率***,如下圖所示:
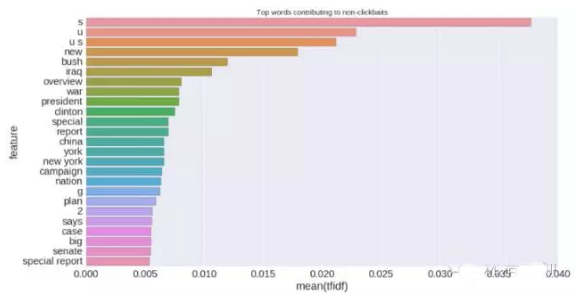
同樣,在non-clickbaits中出現頻率***的字符、單詞為:
接下來,我使用了兩種不同的機器學習算法, 邏輯回歸和梯度增加,并用以下指標評估模型算法:
· ROC曲線下的面積
· 準確度
· 召回率
· F1-分數
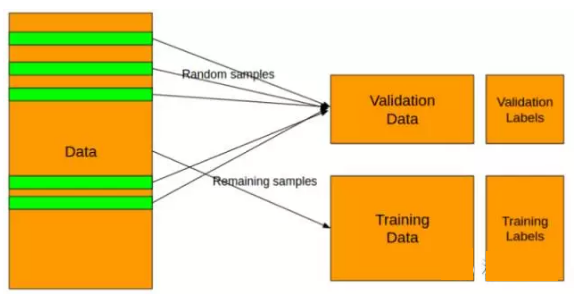
為了避免過度擬合,我使用5折分層抽樣。下圖展示了如何實現隨機抽樣。在分層抽樣的情況下,預測集合訓練集具有相同的正、負標簽比例。
經過一些簡單的模型參數調整,上述兩種機器學習模型的各指標得分如下:
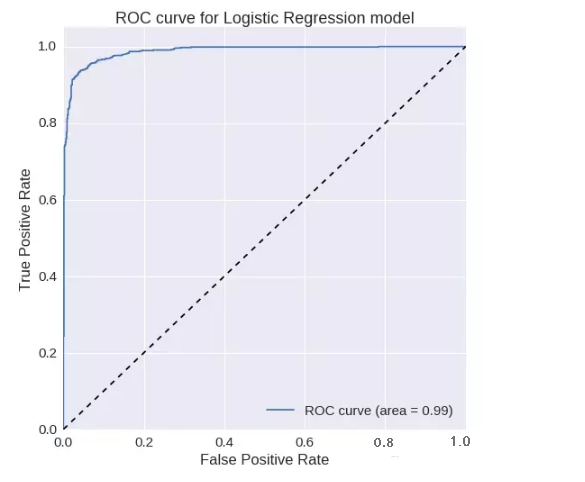
邏輯回歸
:ROC曲線下的面積= 0.987319021551
精確度= 0.950326797386
召回率= 0.939276485788F1
得分= 0.944769330734ROC曲線:
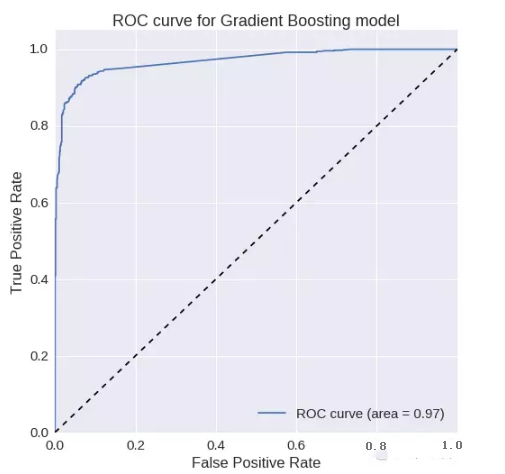
梯度增加:
ROC曲線下的面積= 0.969700677962
精確度= 0.95756718529
召回率= 0.874677002584F1
得分= 0.914247130317ROC
曲線:
Word2Vec
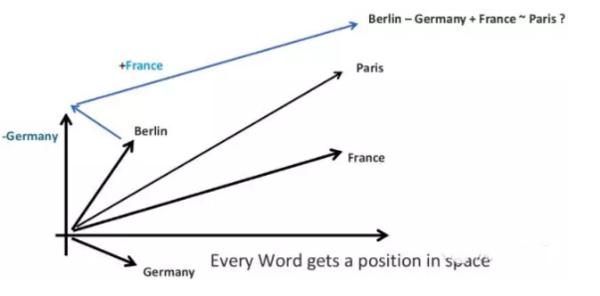
Word2Vec模型在自然語言處理中很受歡迎,總是為我們提供偉大的見解。Word2Vec從本質上來說就是一個矩陣分解的模型,簡單地說,矩陣刻畫了每個詞和其上下文的詞的集合的相關情況。
在本文中,我們用Word2Vec來表示相似或意義非常接近的單詞,如下圖所示:
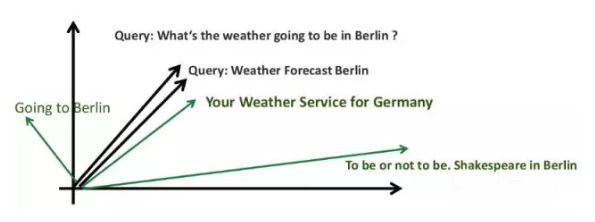
同樣,我們也可以使用word2vec代表句子:
我們將每個單詞(每個句子/標題)作為一個200維的向量。可視化word2vec的***辦法是將這些向量運用t-SNE方法分解在兩維的坐標系中,如下圖:
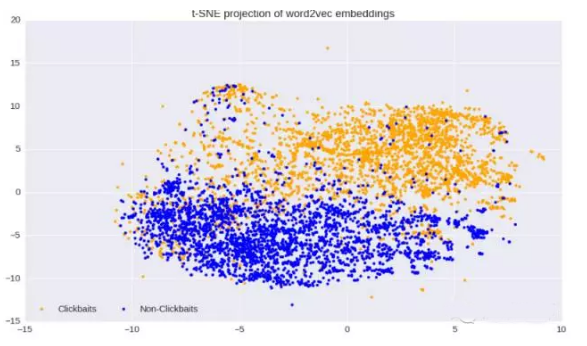
從上圖我們看到,我們只用word2vec就明顯的區分出了clickbaits和non-clickbaits的特征,這意味著,在這一算法上使用一個機器學習模型將會極大的改善我們的分類。
我們使用與上文相同的兩個機器學習模型處理數據集,模型的各指標得分如下:
邏輯回歸:
ROC曲線下的面積= 0.981149604411
精確度= 0.936280884265
召回率= 0.93023255814F1
得分= 0.933246921581ROC
曲線:
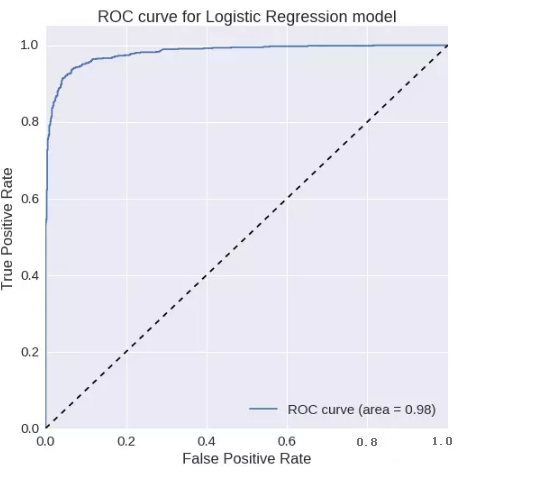
梯度增加:
ROC曲線下的面積= 0.981312768055
精確度= 0.939947780679
召回率= 0.93023255814F1
得分= 0.935064935065ROC
曲線:
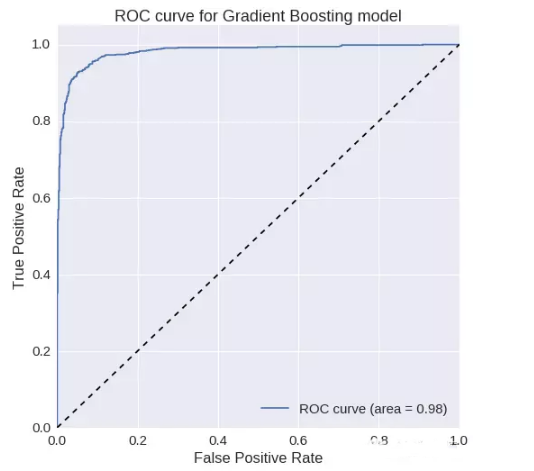
我們可以看到在梯度增加模型中,各項指標得分明顯提高。
為了進一步提高評估,我們結合TF-IDF和Word2Vec兩種算法進行特征識別,并根據這些特征進行自動識別clickbaits的機器模型訓練,可以看到模型分數顯著提高。
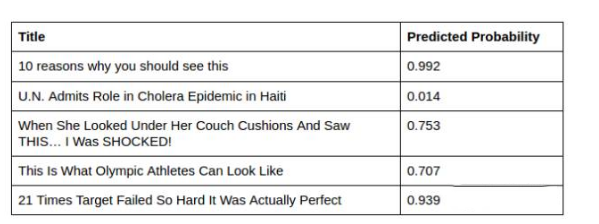
一個嚴肅的結論停止使用標題陷阱。
對新聞工作者來說,這些標題可能會給你帶來額外的閱讀量,但隨著幾大互聯網巨頭的聯合行動,這類現象不會持續很長時間。
文章來源36大數據,www.36dsj.com ,微信號dashuju36 ,36大數據是一個專注大數據創業、大數據技術與分析、大數據商業與應用的網站。分享大數據的干貨教程和大數據應用案例,提供大數據分析工具和資料下載,解決大數據產業鏈上的創業、技術、分析、商業、應用等問題,為大數據產業鏈上的公司和數據行業從業人員提供支持與服務。