老曹眼中的Lambda世界

“ λ ”像一個雙手插兜兒,獨(dú)自行走的人,有“失意、無奈、孤獨(dú)”的感覺。λ 讀作Lambda,是物理上的波長符號,放射學(xué)的衰變常數(shù),線性代數(shù)中的特征值……在程序和代碼的世界里,它代表了函數(shù)表達(dá)式,系統(tǒng)架構(gòu),以及云計算架構(gòu)。
代碼中的Lambda
Lambda表達(dá)式基于數(shù)學(xué)中的λ演算得名,可以看作是匿名函數(shù),可以代替表達(dá)式,函數(shù),閉包等,也支持類型推論,可以遠(yuǎn)離匿名內(nèi)部類。
為什么使用Lambda呢?
1)代碼更緊湊
2)擁有函數(shù)式編程中修改方法的能力
3)有利于多核計算
Lambda的目的是讓程序員能夠?qū)Τ绦蛐袨檫M(jìn)行抽象,把代碼行為看作數(shù)據(jù)。
Java
Java 8的一個大亮點(diǎn)是引入Lambda表達(dá)式,在編寫Lambda表達(dá)式時,也會隨之被編譯成一個函數(shù)式接口。
一個典型的例子是文件類型過濾 :
- File dir = new File("/an/dir/"); FileFilter directoryFilter = new FileFilter() { public boolean accept(File file) { return file.isDirectory(); } };
用lambda 重寫后:
- File dir = new File("/an/dir/"); File[] dirdirs = dir.listFiles((File f) -> f.isDirectory());
Lambda 表達(dá)式本身沒有類型,因為常規(guī)類型系統(tǒng)沒有“Lambda 表達(dá)式”這一內(nèi)部概念。
Python
與Java語言不同,Python的Lambda表達(dá)式的函數(shù)體只能有唯一的一條語句,也就是返回值表達(dá)式語句。Python編程語言使用lambda來創(chuàng)建匿名函數(shù)。
一個典型的例子是求一個列表中所有元素的平方。
一般寫法
- def sq(x): return x * x map(sq, [y for y in range(108)])
使用Lambda 的寫法
- map( lambda x: x*x, [y for y in range(108)] )
在spark 中,用python 操作RDD時,Lambda 更是隨處可見。
- out_rdd = in_rdd.filter( # filter the empty record
- lambda x:x[1] is not None and x[1] != {}
- ).map(
- lambda x:utils.parse_data(x[1],es_relations)
- ).filter( # filter the empty record
- lambda x:x is not None
- ).filter( # filter the record
- lambda x:x[u'timestamp']>time_start)
大數(shù)據(jù)架構(gòu)中的Lambda
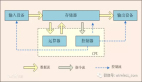
Lambda架構(gòu)的目標(biāo)是設(shè)計出一個能滿足實時大數(shù)據(jù)系統(tǒng)關(guān)鍵特性的架構(gòu),包括有:高容錯、低延時和可擴(kuò)展等。Lambda架構(gòu)整合離線計算和實時計算,融合不可變性(Immunability),讀寫分離和復(fù)雜性隔離等一系列架構(gòu)原則,可集成Hadoop,Kafka,Storm,Spark,Hbase等各類大數(shù)據(jù)組件。
Batch Layer進(jìn)行預(yù)運(yùn)算的作用實際上就是將大數(shù)據(jù)變小,從而有效地利用資源,改善實時查詢的性能。主要功能是:
- 存儲Master Dataset,這是一個不變的持續(xù)增長的數(shù)據(jù)集
- 針對這個Master Dataset進(jìn)行預(yù)運(yùn)算
Serving Layer就要負(fù)責(zé)對batch view進(jìn)行操作,從而為最終的實時查詢提供支撐。主要作用是:
- 對batch view的隨機(jī)訪問
- 更新batch view
speed layer與batch layer非常相似,它們之間***的區(qū)別是前者只處理最近的數(shù)據(jù),后者則要處理所有的數(shù)據(jù)。另一個區(qū)別是為了滿足最小的延遲,speed layer并不會在同一時間讀取所有的新數(shù)據(jù),在接收到新數(shù)據(jù)時,更新realtime view,而不會像batch layer那樣重新運(yùn)算整個view。speed layer是一種增量的計算,而非重新運(yùn)算(recomputation)。Speed Layer的作用包括:
- 對更新到serving layer帶來的高延遲的一種補(bǔ)充
- 快速、增量的算法
- 最終Batch Layer會覆蓋speed layer
大數(shù)據(jù)系統(tǒng)一般具有如下屬性:
* 健壯性和容錯性(Robustness和Fault Tolerance)
* 低延遲的讀與更新(Low Latency reads and updates)
* 可伸縮性(Scalability)
* 通用性(Generalization)
* 可擴(kuò)展性(Extensibility)
* 內(nèi)置查詢(Ad hoc queries)
* 維護(hù)最小(Minimal maintenance)
* 可調(diào)試性(Debuggability)
個人覺得,有了spark streaming 之后,spark 本身就是一種Lambda架構(gòu)。
云計算中的Lambda
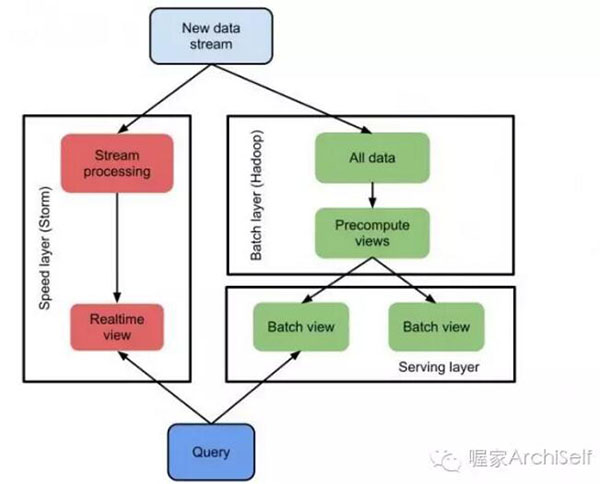
云計算中的Lambda,是指serverless architecture,無需配置或管理服務(wù)器即可運(yùn)行代碼。借助 Lambda,幾乎可以為任何類型的應(yīng)用程序或后端服務(wù)運(yùn)行代碼,而且全部無需管理。
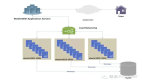
以AWS 為例,云計算中的Lambda 示意流程如下:
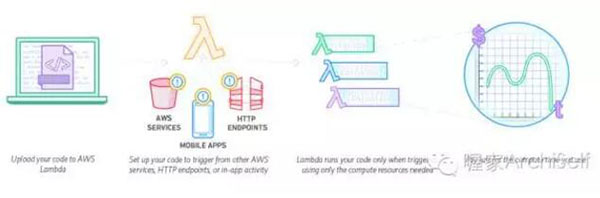
只需上傳代碼,Lambda 會處理運(yùn)行和擴(kuò)展高可用性代碼所需的一切工作。還可以將代碼設(shè)置為自動從其他服務(wù)觸發(fā),或者直接從任何 Web 或移動應(yīng)用程序調(diào)用。
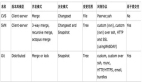
ETL 是數(shù)據(jù)挖掘與數(shù)據(jù)分析中的必備環(huán)節(jié),可以方便的通過AWS的Lambda實現(xiàn),示例如下:
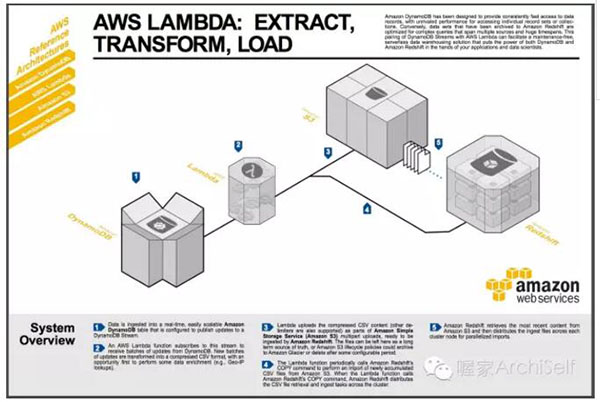
其實,在spark 上實現(xiàn)Lambda 云服務(wù)也不是太費(fèi)力的事。
總之,了解越多,越會喜歡上它,神奇而有趣的Lambda。
【本文來自51CTO專欄作者老曹的原創(chuàng)文章,作者微信公眾號:喔家ArchiSelf,id:wrieless-com】