如何用KNIME進(jìn)行情感分析 | 下
如何能夠讓機器“讀懂”人的情感?情感分析提供了解決的一個思路。這也使得它成為自然語言分析(Natural Language Processing)中最令人神往的山對面的“風(fēng)景”。
什么是情感分類(sentiment classification)
簡單說,就是對于一句或一段話,判斷說話者的情感,是正向(積極)的,還是負(fù)向(消極)的。這種情感分類任務(wù)可以看作一個二分類問題。
完成情感分類的核心問題
決定分類準(zhǔn)確率的關(guān)鍵在于特征的選取與語料的質(zhì)量。其中特征問題解決的是:用什么樣的特征來抽取,得到的文本才足夠原始呢?每個詞看似已經(jīng)是文本的足夠底層的特征,但其實也是經(jīng)過高度抽象的。這也會給深度學(xué)習(xí)在自然語言領(lǐng)域的應(yīng)用帶來一些困難。同樣,這也是提高模型準(zhǔn)確度的一個有效的方法。
在上一篇情感分析的講解中,我們已經(jīng)知道如何使用KNIME構(gòu)造一個情感分析模型。這一篇中,我們將使用N元語法(N-gram),借助KNIME來探究如何選取詞語特征,獲得的模型能夠?qū)崿F(xiàn)更準(zhǔn)確地分類。
N元語法
在計算語言學(xué)中,n-gram指的是文本中連續(xù)的n個item。n-gram中如果n=1則為unigram,n=2則為bigram,n=3則為trigram。n>4后,則直接用數(shù)字指稱,如4-gram,5gram。(Wikipedia)
以 I would like to go to Beijing. 這句話為例。
bigram為:
- I would
- would like
- like to
- to go
- go to
- to Beijing
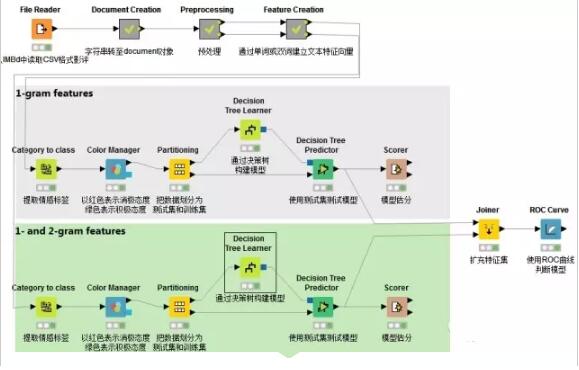
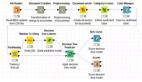
結(jié)點概覽
1.讀取CSV格式文件
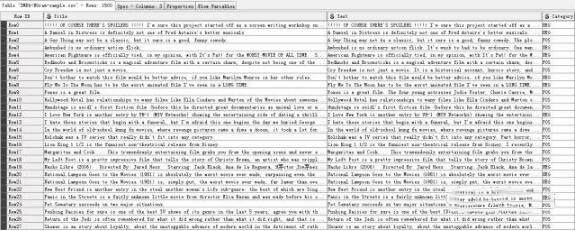
使用CSV reader結(jié)點讀取一個CSV格式文件,該文件寫入了1500條載于IMBD上的影評,并且給出了情感向量即POS(positive)和NEG(negative)。
2.字符串轉(zhuǎn)化為文檔格式
接下來將字符串轉(zhuǎn)化為文檔格式,繼而使用“過濾”節(jié)點刪除無關(guān)列,使文件只留下儲存文檔對象的一列。
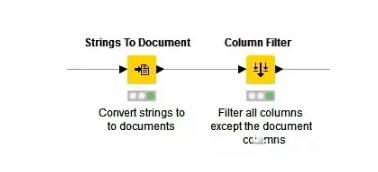
以上結(jié)點內(nèi)屬于Document creation元結(jié)點
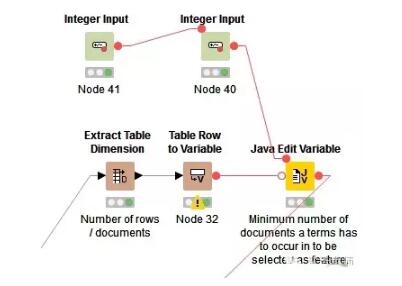
3.數(shù)據(jù)預(yù)處理
首先計算特征詞語需要在文檔中出現(xiàn)最小次數(shù)N。利用java語句計算:out_MinDF = (Number_Rows / 100) * Min_Percentage
繼而進(jìn)行刪除標(biāo)點,刪除數(shù)字,刪除文檔中出現(xiàn)次數(shù)小于N的詞匯,將大寫轉(zhuǎn)化為小寫,提取詞語主干(stemmed)和刪除停用詞(stop word)。至此我們可以完成預(yù)處理。但是由于我們想探索的是雙詞分類與單詞分類的效果差異,所以這里花開兩朵各表一枝,雙詞分類的這一支不需要做主干提取和停用詞刪除的工作。
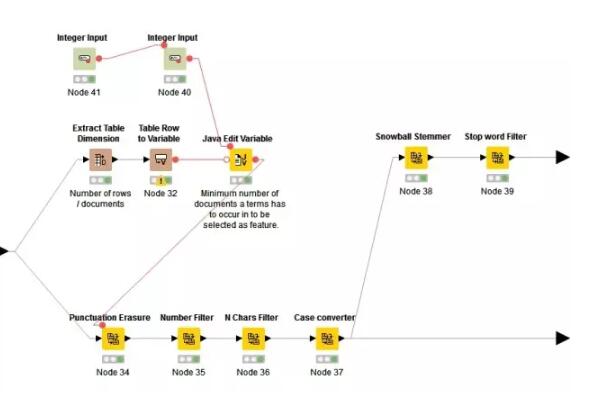
(stemmed意指將詞的變形歸類,使得機器在處理文本時減少需要跟蹤的獨特詞匯,這會加快“標(biāo)簽化”處理的過程。停用詞是人類語言中沒有實際意義或功用的詞語,如助詞,限定詞等)
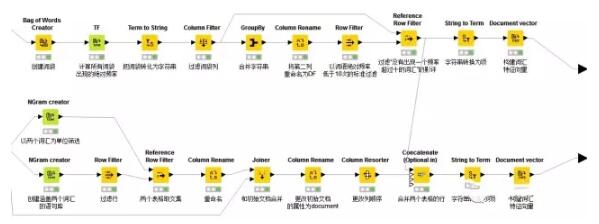
4.通過單詞或雙詞建立文本特征向量
想象在一個巨大的文檔集合,里面一共有M個文檔,而文檔里面的所有單詞提取出來后,一起構(gòu)成一個包含N個單詞的詞典,利用詞袋(Bag-of-words)模型,每個文檔都可以被表示成為一個N維向量(將每篇文檔表示為一個向量,每一維度代表一個詞語,其數(shù)值代表詞語在該文檔中的出現(xiàn)次數(shù))。這樣,就可以利用計算機來完成海量文檔的分類過程。
一般來說,太多的特征會降低分類的準(zhǔn)確度,所以需要使用一定的方法,來“選擇”出信息量最豐富的特征,再使用這些特征來分類。
特征選擇遵循如下步驟:
- 1. 計算出整個語料里面每個詞的信息量
- 2. 根據(jù)信息量進(jìn)行倒序排序,選擇排名靠前的信息量的詞
- 3. 把這些詞作為特征
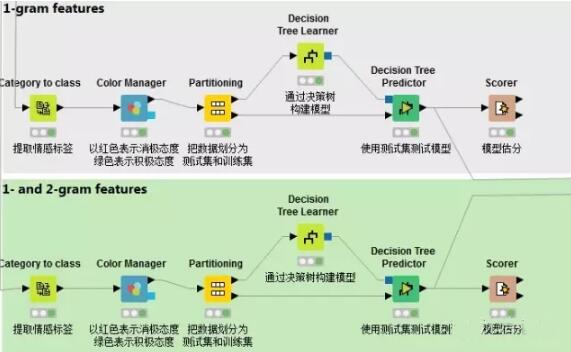
5.構(gòu)建模型
通過決策樹算法構(gòu)建模型在上一篇已經(jīng)講過,需要注意的是本篇需要對1-gram特征和1-gram 2-gram集合特征分別構(gòu)建模型,以進(jìn)行比較。這里不再贅述。
6.ROC曲線對比
在文檔向量集創(chuàng)建后,詞匯的情感分類已經(jīng)被提取出來,系統(tǒng)自動創(chuàng)建了兩種預(yù)測模型并打分。一個模型基于一個單獨詞匯的特征建立,第二個模型基于1-gram和2gram集合的特征。接著通過ROC接收器操作特性曲線(receiver operating characteristic curve)對這兩個進(jìn)行比較。
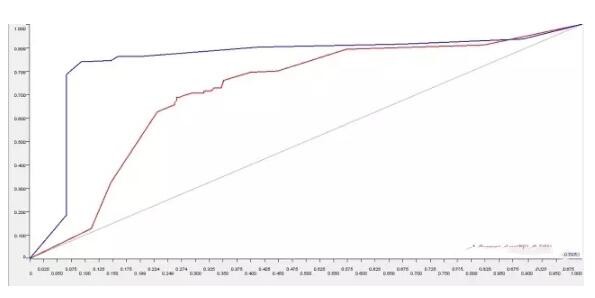
可以看出,在分析影評這一文本的情感態(tài)度時,使用N元語法構(gòu)建出來的情感分類模型,診斷準(zhǔn)確度更高,為85.05%。這樣有助于我們針對“何種情感分類模型對NLP分析更為有效”這一問題時做出決策。