如何使用KNIME進行情感分析 | 中
在現實世界中,知識不僅以傳統數據庫中的結構化數據的形式出現,還以諸如書籍、研究論文、新聞文章、WEB頁面及電子郵件等各種各樣的形式出現。面對以這些形式出現的、浩如煙海的信息源,人類的閱讀能力、時間精力等等往往不夠,需要借助計算機的智能處理技術來幫助人類及時、方便的獲取這些數據源中隱藏的有用信息。文本挖掘技術就在這種背景下產生和發展起來的。
文本挖掘的根本價值在于能把從文本中抽取出的特征詞進行量化來表示文本信息。將它們從一個無結構的原始文本轉化為結構化的計算機可以識別處理的信息,即對文本進行科學的抽象,建立它的數學模型,用以描述和代替文本。使計算機能夠通過對這種模型的計算和操作來實現對文本的識別。文本挖掘廣泛應用于輿情監測、有害信息過濾、電子郵件和文獻分析以及情感分析等領域。
今天我們來聊一聊如何用KNIME構造一個情感分析模型,以便后期對相似的文本進行情感分析。
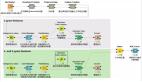
下圖是整個分析過程的概況:
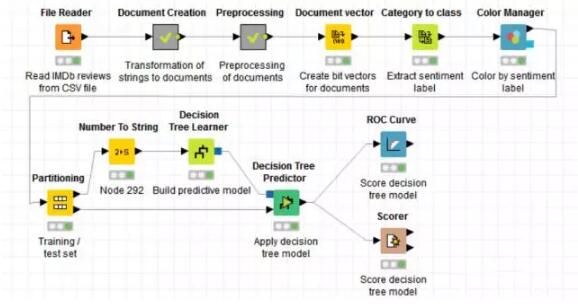
首先,我們從IMDb網站上獲取關于《Girlfight》這部影片的2000條評論,儲存為.CSV格式的文件,利用File Reader這個節點把文本讀入。

現在我們要將文件中的字符串轉化成文檔,把文件中除了文檔的列都過濾掉。
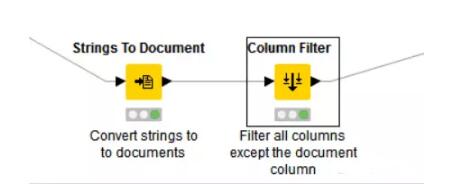
(上圖即為Document Creation元節點里面的內容)
接著我們對這個文檔進行文本的預處理。先后將標點清除,數字過濾掉,將小于三個詞語的文檔過濾掉,停用詞過濾,將大寫轉化為小寫,***提取詞干。

(上圖即為Preprocessing元節點里面的內容)
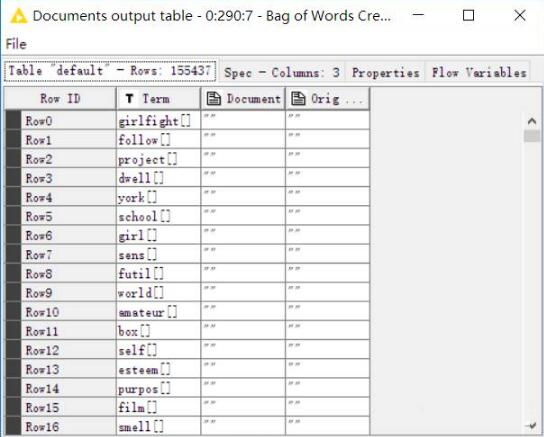
之后我們就可以創建詞袋了,即把提取出來的詞干扔進一個袋子里,可以看到,在本例中,我們創造的詞袋中一共包含155437行數據。
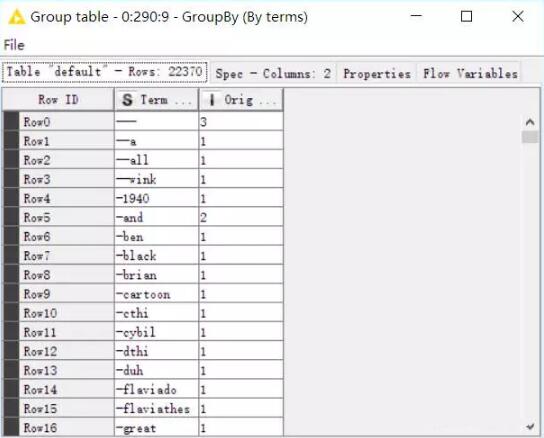
然后把詞袋中的詞轉化為字符串,并根據原評論中詞出現的次數分組,可以看到,分組后我們的詞袋變成了22370行(這是因為之前的詞是有重復的)。
之后我們過濾掉出現次數小于N的詞,(注意這個N是由從原文件中提取出的行數經過一段語法計算決定的,在本例中,是用行數除以100)。
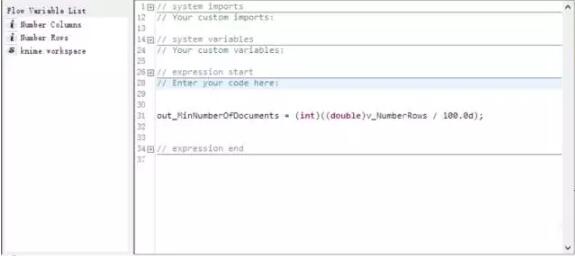
接著,我們以上一步過濾掉的詞為參考,在最初創建的詞袋中過濾掉它們,過濾后我們可用的詞是100728行數據,***計算這些詞的詞頻。
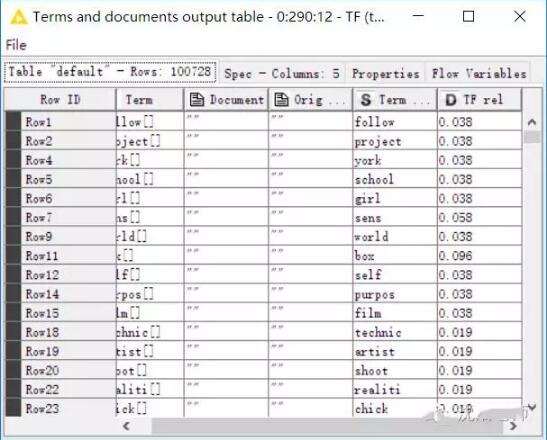
終于我們完成了文本的預處理過程。
現在,我們要為原始的評論創建向量,來觀察詞袋中的詞是否存在于原文本中。之后提取原評論的情感標簽,并以顏色分類。
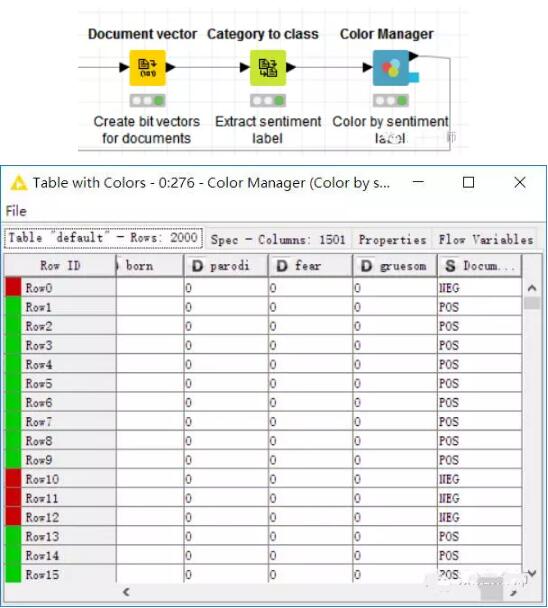
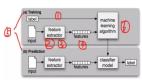
接著我們把2000條評論分成兩個部分,本例中將70%用作訓練集,來構建決策樹模型,另外的30%用來測試決策樹模型。
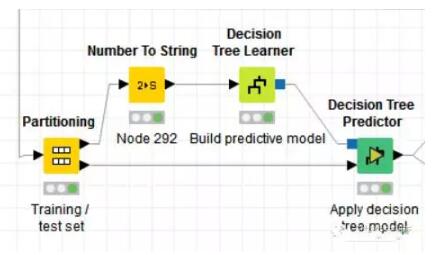
這就是決策樹模型,根據一個詞是否存在將文本集分為兩個部分。
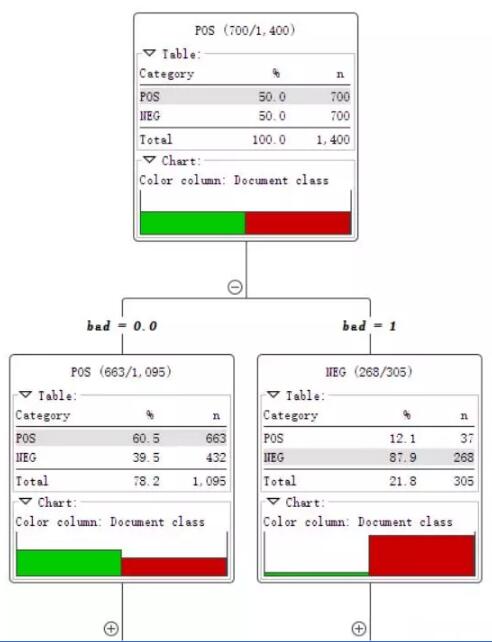
直到所有記錄都屬于同一類決策樹就會停止。
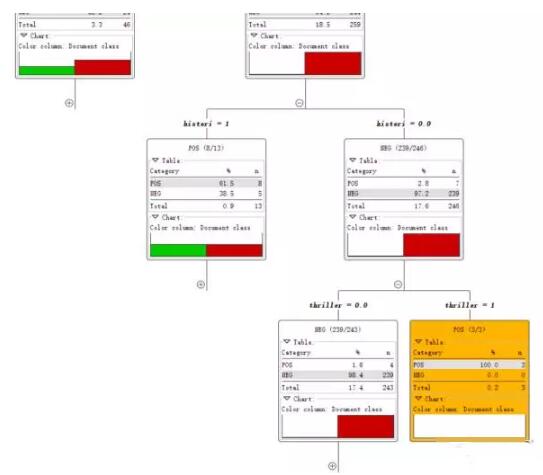
***我們用兩種方法來對模型進行評價。
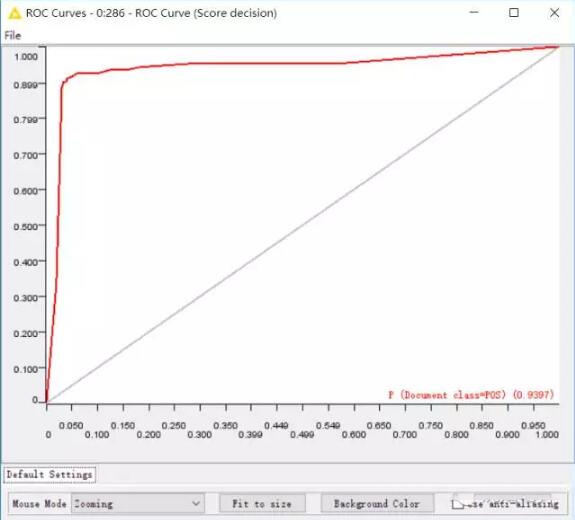
一種是ROC曲線,曲線下方面積達到0.9397,如此可見,模型還是很不錯的。
再來看一下矩陣,準確率高達93.167%。
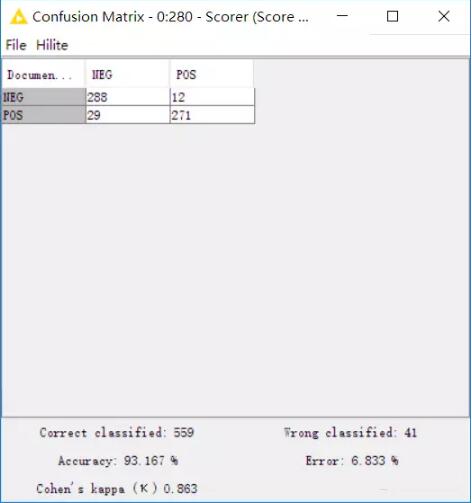
如此看來,我們的模型可以用來進行類似的文本情感分析。比如說網購的商品評論,企業官微下的評論等類似的情況,都可以用來進行情感分析。
點擊查看: