如何科學地蹭熱點:用python爬蟲獲取熱門微博評論并進行情感分析
前言:本文主要涉及知識點包括新浪微博爬蟲、python對數據庫的簡單讀寫、簡單的列表數據去重、簡單的自然語言處理(snowNLP模塊、機器學習)。適合有一定編程基礎,并對python有所了解的盆友閱讀。
甩鍋の聲明
- 1.本數據節選自新浪熱門微博評論,不代表本人任何觀點
- 2.本人不接受任何非技術交流類批評指責(夸我可以)
- 3.本次分析結果因技術問題存在一定誤差(是引入的包的問題,不是我的)
- 4.本次選取熱門微博為一個月以前的(翻譯一下:熱點已經冷了,我只是個寫教程的)
- 頂鍋蓋逃
繼上次更完“國慶去哪兒”文之后,被好多編程相關的公眾號翻了牌子_(:зゝ∠)_,讓我過了一把v的癮,也讓我更加努力的想要裝(消音)。
在我埋頭學習mysql、scrapy、django準備下一波吹水的時候,有人說,你去爬下老薛的微博呀,還能蹭個熱點,這讓勤(mo)奮(mo)學(kou)習(jiao)的我停下了寄幾敲代碼的手。
然后我趕緊去關注了一下最近老薛的新聞…在感受了劇情的復雜和案情的撲朔迷離之后…我默默地學習了如何閱讀合同…如何利用ELA分析圖片…如何寫作文…如何查別人的銀行流水…知識點有點多…讓我緩一會…
所以呢,這次的主題是分析老薛最新微博的評論,分析評論粉絲們的心情狀態,且聽我娓娓道來。
1.新浪微博API
在經歷了幾次爬蟲被禁的悲痛(真的很痛)之后,我學會了在爬網站之前先查有沒有API的“優良”習慣。新浪作為一個大廠,怎么會不推出新浪微博API呢,面向開發者新浪有自己的開放平臺,這里是python調用微博API的方法,下面是通過登錄App_key和App_secret方式訪問微博API的代碼,代碼是基于py2的。py3對weibo模塊使用存在一定問題。
- from weibo import APIClient
- import webbrowser
- import sys
- reload(sys)
- sys.setdefaultencoding('utf-8')
- APP_KEY = '你的App Key ' #獲取的App Key
- APP_SECRET = '你的AppSecret' #獲取的AppSecret
- CALLBACK_URL = 'https://api.weibo.com/oauth2/default.html' #回調鏈接
- client = APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=CALLBACK_URL)
- url = client.get_authorize_url()
- webbrowser.open_new(url) #打開默認瀏覽器獲取code參數
- print '輸入url中code后面的內容后按回車鍵:'
- code = raw_input()
- r = client.request_access_token(code)
- access_token = r.access_token
- expires_in = r.expires_in
- client.set_access_token(access_token, expires_in)
知道如何登錄API了,辣么如何調用API爬單條微博的評論呢?一行代碼搞定。
- r = client.comments.show.get(id = 4154417035431509,count = 200,page = 1)
所有關于單條微博的評論信息都在r.comments中了,這里需要對照微博API文檔,微博API有聲明調用微博評論API需要獲取用戶授權,但是捏,只要知道單條微博的id,就可以調用這個API了,關于單條微博的id如何獲取在后面會說(小聲一點,千萬別讓微博知道,萬一封了呢)。

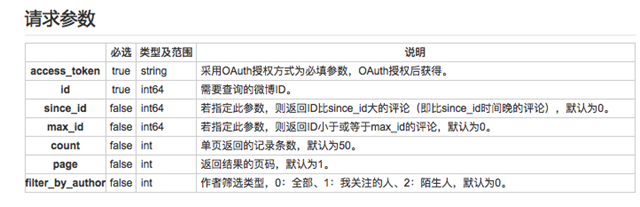
按照client.接口名.get(請求參數)的方式獲取API,獲取API后的規格可在接口詳情中查看,文檔中有給出返回結果的示例。
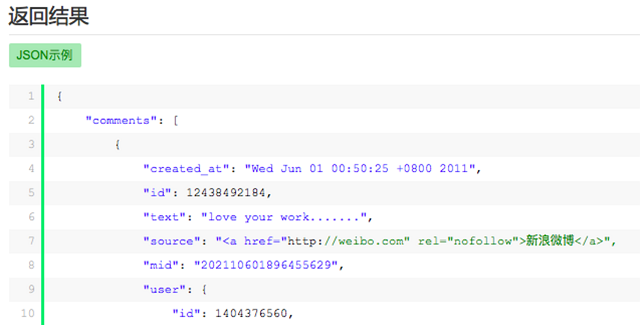
文檔中也給出了關鍵數據的json接口名稱。
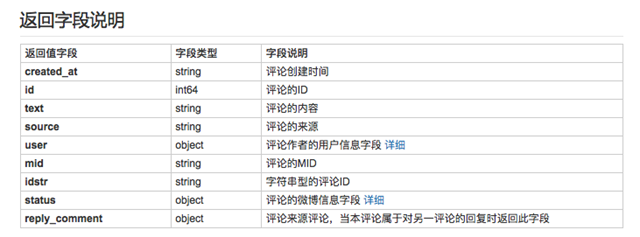
如果我們要獲取微博評論的內容,只需要調用text接口即可。
- for st in r.comments:
- text = st.text
2.微博爬蟲
通過調用新浪微博API的方式,我們就可以簡單獲取單條微博的評論信息了,為啥說簡單呢,因為人紅信息貴啊!你以為大V的微博就這么免費的給你API調用了嗎,非認證應用開發者單日只能請求幾千次API,這對像老薛這樣單條微博幾十萬評論的大V來說…太少了(TT)
所以捏,還是要寫微博爬蟲。
正所謂,知己知彼百戰不殆,新浪作為大廠,怎么說也是身經百戰,必定是經歷了無數場爬蟲與反爬之間的戰爭,必然有著健全的反爬策略。正所謂,強敵面前,繞道而行,有位大佬說得好,爬網站,先爬移動端:https://m.weibo.cn/
登錄微博后,進入到老薛回應P圖事件的微博中去,_(:зゝ∠)_老薛啊,怪我,怪我來得太晚了,點進去的時候已經有70w+的評論了(截止至發文當天已經100w+的評論了),可以看到安靜的微博下粉絲們不安的心…
移動端微博的網址顯得肥腸簡單,不似PC端那么復雜而不明邏輯:https://m.weibo.cn/status/4154417035431509 多點幾條微博就可以知道status后面的數字,就是單條微博的id了。
評論里包含了熱門評論和最新評論倆種,但無論是哪種評論,繼續往下翻網址都不會變化。江湖慣例(不懂江湖慣例的去看我之前的文),chrome瀏覽器右鍵“檢查”,觀察network變化。
從network的xhr文件中,可以得知熱門評論的變化規律是:
- 'https://m.weibo.cn/single/rcList?format=cards&id=' + 單條微博id + '&type=comment&hot=1&page=' + 頁碼
最新評論的變化規律是:
- 'https://m.weibo.cn/api/comments/show?id=' + 單條微博id + '&page=' + 頁碼
打開https://m.weibo.cn/single/rcList?format=cards&id=4154417035431509&type=comment&hot=1&page=1 就可以看到熱門評論的json文件。
接下來就是套路了,偽裝瀏覽器header,讀取json文件,遍歷每一頁…這都不是重點!而且這些我以前都講過~直接上代碼~這里開始是py3的代碼了~
- import re,time,requests,urllib.request
- weibo_id = input('輸入單條微博ID:')
- # url='https://m.weibo.cn/single/rcList?format=cards&id=' + weibo_id + '&type=comment&hot=1&page={}' #爬熱門評論
- url='https://m.weibo.cn/api/comments/show?id=' + weibo_id + '&page={}' #爬時間排序評論
- headers = {
- 'User-agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:55.0) Gecko/20100101 Firefox/55.0',
- 'Host' : 'm.weibo.cn',
- 'Accept' : 'application/json, text/plain, */*',
- 'Accept-Language' : 'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
- 'Accept-Encoding' : 'gzip, deflate, br',
- 'Referer' : 'https://m.weibo.cn/status/' + weibo_id,
- 'Cookie' : '登錄cookie信息',
- 'DNT' : '1',
- 'Connection' : 'keep-alive',
- }
- i = 0
- comment_num = 1
- while True:
- # if i==1: #爬熱門評論
- # r = requests.get(url = url.format(i),headers = headers)
- # comment_page = r.json()[1]['card_group']
- # else:
- # r = requests.get(url = url.format(i),headers = headers)
- # comment_page = r.json()[0]['card_group']
- r = requests.get(url = url.format(i),headers = headers) #爬時間排序評論
- comment_page = r.json()['data']
- if r.status_code ==200:
- try:
- print('正在讀取第 %s 頁評論:' % i)
- for j in range(0,len(comment_page)):
- print('第 %s 條評論' % comment_num)
- user = comment_page[j]
- comment_id = user['user']['id']
- print(comment_id)
- user_name = user['user']['screen_name']
- print(user_name)
- created_at = user['created_at']
- print(created_at)
- text = re.sub('<.*?>|回復<.*?>:|[\U00010000-\U0010ffff]|[\uD800-\uDBFF][\uDC00-\uDFFF]','',user['text'])
- print(text)
- likenum = user['like_counts']
- print(likenum)
- source = re.sub('[\U00010000-\U0010ffff]|[\uD800-\uDBFF][\uDC00-\uDFFF]','',user['source'])
- print(source + '\r\n')
- comment_num+=1
- i+=1
- time.sleep(3)
- except:
- i+1
- pass
- else:
- break
這里有幾點說明:
- 設置爬取間隔時間之后,微博爬蟲被禁的概率降低了很多(特別是晚上)
- 新浪每次返回的json數據條數隨機,所以翻頁之后會出現數據重復的情況,所以用到了數據去重,這會在后面說。
- 在text和source中添加了去除emoji表情的代碼(折騰了很久寫不進數據庫,差點就從刪庫到跑路了/(ㄒoㄒ)/),同時也去除了摻雜其中的回復他人的html代碼。
- 我只寫了讀取數據,沒有寫如何保存,因為我們要用到數!據!庫!辣!(這是重點!敲黑板)
3.python中數據庫的讀取與寫入
雖然微博爬蟲大大提高了數據獲取量,但也因為是爬蟲而容易被新浪封禁。這里結束循環的判斷是網絡狀態不是200,但當微博發現是爬蟲時,微博會返回一個網頁,網頁中什么實質內容都木有,這時候程序就會報錯,而之前爬到的數據,就啥也沒有了。
但是如果爬一會,保存一次數據,這數據量要一大起來…冷冷的文件在臉上胡亂地拍…我的心就像被…這時候我們就需要用到數據庫了。
數據庫,顧名思義,就是存放數據的倉庫,數據庫作為一個發展了60多年的管理系統,有著龐大的應用領域和復雜的功能……好了我編不下去了。
在本文中,數據庫的主要作用是AI式的excel表格(●—●)。在爬蟲進行的過程中,爬到一個數就存進去,爬到一個數就存進去,即使爬蟲程序運行中斷,中斷前爬到的數據都會存放在數據庫中。
大多數數據庫都能與python對接使用的,米醬知道的有mysql、sqlite、mongodb、redis。這里用的是mysql,mac上mysql的安裝,管理數據庫的軟件Navicat使用幫助,其他系統自己找吧,安裝使用過程中有啥問題,請不要來找我(逃
根據上面的代碼,在navicat中創建數據庫、表和域以及域的格式。在Python程序中添加代碼。
- conn =pymysql.connect(host='服務器IP(默認是127.0.0.1)',user='服務器名(默認是root)',password='服務器密碼',charset="utf8",use_unicode = False) #連接服務器
- cur = conn.cursor()
- sql = "insert into xue.xueresponse(comment_id,user_name,created_at,text,likenum,source) values(%s,%s,%s,%s,%s,%s)" #格式是:數據名.表名(域名)
- param = (comment_id,user_name,created_at,text,likenum,source)
- try:
- A = cur.execute(sql,param)
- conn.commit()
- except Exception as e:
- print(e)
- conn.rollback()
運行python程序,大概爬了2w條實時評論,新浪微博的反爬還是很強大的,有倆個解決方法:更換IP和切換賬號,IP代理的使用方法我以前有寫過,賬號可以在X寶購買,但是!_(:зゝ∠)_由于本文的作者是一個肥腸貧窮肥腸摳門并且身患重病(懶癌)的人……2w條數據也是有研究價值的對不對(((;꒪ꈊ꒪;))),不如我們就這樣繼續我們研究吧(((;꒪ꈊ꒪;)))……
在進行下一步研究之前,我們還要將數據庫中的內容讀取出來,python中數據庫的讀取代碼也很簡單。
- conn =pymysql.connect(host='服務器IP',user='用戶名',password='密碼',charset="utf8") #連接服務器
- with conn:
- cur = conn.cursor()
- cur.execute("SELECT * FROM xue.xueresponse WHERE id < '%d'" % 20000)
- rows = cur.fetchall()
這樣之前爬取的信息就被讀取出來了,但是前面也說了,微博爬蟲翻頁時返回數據條數隨機,所以會出現重復的狀況,所以讀取之后,需要用if…not in語句進行一個數據去重。
- for row in rows:
- row = list(row)
- del row[0]
- if row not in commentlist:
- commentlist.append([row[0],row[1],row[2],row[3],row[4],row[5]])
完整代碼在文末。
4.自然語言處理NLP
NLP是人工智能的一個領域,可以通過算法的設計讓機器理解人類語言,自然語言也屬于人工智能中較為困難的一環,像中文這么博大精深、變幻莫測的語言更是NLP中的一大難點,python中有很多NLP相關的模塊,有興趣的盆友可以通過用python實現簡單的文本情感分析初探NLP。
我參(ban)考(yun)了一些現成的情感分析算法,對爬取的評論進行分析,錯誤率肥腸高_(:зゝ∠)_,這可腫么辦?難道要重新設計算法?米醬仿佛遇到了人生中第一個因為語文沒學好而引發的重大問題……
當然像米醬這樣靈(lan)活(duo)的姑娘,自然是很快發現了python中較為出名的一個中文NLP庫:snowNLP。snowNLP調用的方法比較簡單,源碼中詳細解釋了調用方法,和生成結果。
- def snowanalysis(textlist):
- sentimentslist = []
- for li in textlist:
- s = SnowNLP(li)
- print(li)
- print(s.sentiments)
- sentimentslist.append(s.sentiments)
這段代碼中獲取了讀取數據庫后由評論主體text生成的列表文件,并依次對每一個評論進行情感值分析。snowNLP能夠根據給出的句子生成一個0-1之間的值,當值大于0.5時代表句子的情感極性偏向積極,當分值小于0.5時,情感極性偏向消極,當然越偏向倆頭,情緒越明顯咯,讓我們來看看測試評論的結果。

第一條:惡心 呸 給出了0.01的分值,最后一條:力挺薛之謙 給出了0.99的分值。看其他幾句基本符合語境的態度,當需要評測單個商品的評價態度時就可以使用snowNLP。但是由于老薛的評論中涉及到三個人,他自己,李雨桐,高磊鑫,算法無法判斷評論是關于誰的情感值,又因為微博評論可以粉絲之間互相回復,這讓判斷評論的主體是誰更加撲朔迷離(機器表示我學習不能啊…)。
這好像代表了,本次分析的結果將…并沒有什么卵用。發生這種事情,米醬也不想的…做人呢…最重要的是要開心…米醬不會寫算法啊,米醬語文也不好啊,米醬真的做不到啊(๑°⌓°๑)…
5.分析結果
本次分析的目的愉快的從分析粉絲們對待薛之謙事件的情緒變成了單純分析粉絲們的情緒(●—●)。
- plt.hist(sentimentslist,bins=np.arange(0,1,0.02))
- plt.show()
對上節經過處理得到的情感值列表進行統計,并生成分布圖。下圖數據采集時間9月27日19時,采集評論2w條。
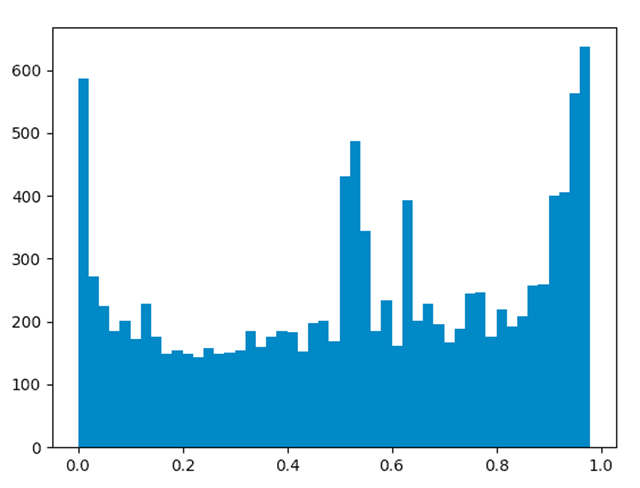
我還順便(真的是順便,正經臉)爬了李雨桐將網友轉賬捐款的微博的2w條評論。
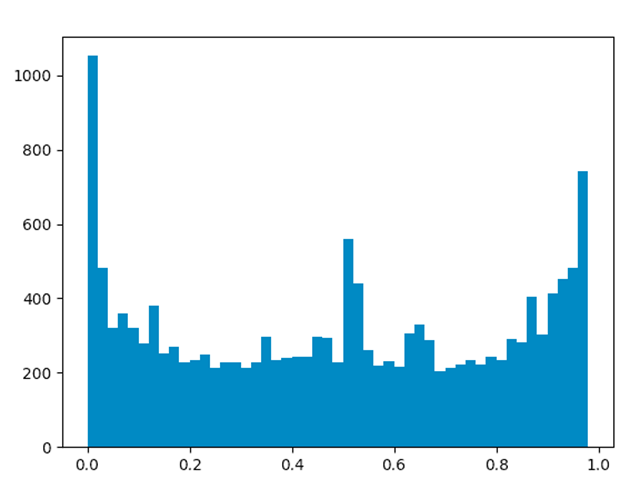
我又順順便(真的順便,看我真誠的眼神)爬了陳赫出軌時發表我錯了博文的微博評論。
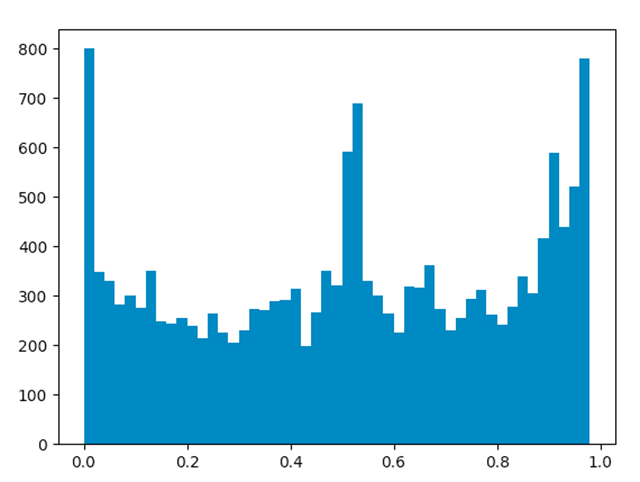
根據這三張圖,可以看到情感值在接近0、1兩端以及0.5左右位置頻率較高,說明粉絲們對于此類事件的情緒無論是積極還是消極都是比較明顯的。但也可以從圖片中看到一些微妙的差別,老薛的微博中情感值接近1的數量高于接近0的數量,但都沒有超過700,李雨桐微博中情感值接近1的數量遠低于接近0的數量,甚至接近0的數目到達了1000以上,但二者都超過了700,而陳赫的微博分析結果,倆者則都接近800。由于算法存在一定誤差,不代表真實評論結果,我就不再多分析了(你們懂的)。
6.彩蛋
由于本次分析結果十分的……蒼白(我真的…盡力了…_(:зゝ∠)_
我又對評論中出現的微博表情進行了統計。
- #薛微博評論表情統計
- Counter({'[加油]': 128, '[哆啦A夢開心]': 28, '[哆啦A夢親親]': 17, '[哆啦A夢美味]': 12, '[em]': 4, '[/em]': 4, '[愛你]': 4, '[攤手]': 3, '[怒罵]': 3, '[好棒]': 3, '[轉發]': 2, '[可愛]': 1, '[太開心]': 1, '[/cp]': 1, '[呵呵]': 1, '[xkl轉圈]': 1, '[溫暖帽子]': 1, '[ok]': 1})
- #李微博評論表情統計
- Counter({'[攤手]': 13, '[加油]': 10, '[ok]': 8, '[皺眉]': 6, '[怒罵]': 4, '[太開心]': 3, '[左哼哼]': 3, '[饞嘴]': 2, '[擠眼]': 2, '[呵呵]': 2, '[嘿哈]': 2, '[機智]': 2, '[/cp]': 1, '[抱抱_舊]': 1, '[笑而不語]': 1, '[費解]': 1, '[cp]': 1})
- #陳微博評論表情統計
- Counter({'[呵呵]': 238, '[挖鼻屎]': 77, '[微風]': 45, '[好棒]': 26, '[打哈氣]': 21, '[ok]': 12, '[左哼哼]': 12, '[羊年大吉]': 12, '[懶得理你]': 11, '[崩潰]': 10, '[花心]': 9, '[困死了]': 8, '[淚]': 8, '[玫瑰]': 8, '[睡覺]': 6, '[雷鋒]': 5, '[炸雞和啤酒]': 5, '[帶著微博去旅行]': 4, '[有鴨梨]': 3, '[發紅包啦]': 3, '[馬到成功]': 3, '[丘比特]': 3, '[最右]': 3, '[花]': 3, '[打臉]': 3, '[別煩我]': 2, '[推薦]': 2, '[摳鼻屎]': 2, '[傷心]': 2, '[xkl轉圈]': 2, '[霹靂]': 2, '[em]': 2, '[/em]': 2, '[悲催]': 2, '[不要]': 2, '[ali轉圈哭]': 2, '[xkl糖豆]': 1, '[江南style]': 1, '[芒果萌萌噠]': 1, '[給勁]': 1, '[歪果仁夏克立]': 1, '[搶到啦]': 1, '[萌娃大竣]': 1, '[電影]': 1, '[憤怒]': 1, '[夏天公主]': 1, '[飛個吻]': 1, '[父親節]': 1, '[強]': 1, '[得瑟]': 1, '[被電]': 1, '[拜 拜]': 1, '[蠟燭]': 1, '[奧特曼]': 1, '[lt嚇]': 1, '[甩甩手]': 1, '[轉發]': 1, '[xkl頂]': 1, '[贊]': 1, '[愉快]': 1, '[糾結]': 1, '[/cp]': 1, '[bm贊]': 1, '[巨汗]': 1, '[最差]': 1, '[害怕]': 1, '[豬頭]': 1, '[bm哭泣]': 1, '[lt淚目]': 1, '[瞧瞧]': 1, '[打哈欠]': 1, '[xkl親親]': 1, '[bm會心笑]': 1, '[bm調皮]': 1})
李相比于倆位當時正當紅的明星,粉絲們使用表情的數目也是天壤之別啊。網友們對陳赫評論最多的表情是[呵呵],沒有一個[加油](也有可能當時沒有[加油]這個表情?),對老薛用了128次[加油],李雨桐10次,而評論李雨桐微博最多的表情也只有13個。果然是人紅熱點多,連表情包也多啊!
我還對參與評論的粉絲進行了統計,并提取了2w條微博評論里參與評論最多的前20位粉絲。
- #薛微博評論粉絲統計
- [('方鹿亓', 150), ('用戶5238901365', 60), ('野百合xy', 57), ('憶盲i', 46), ('哎喲瑪', 44), ('學霸吖', 43), ('炒股屌絲', 42), ('賭神美好如初52', 38), ('梅蘭竹菊-世外桃源', 37), ('罌粟七年前', 36), ('陽光音樂i', 33), ('用戶5909206841', 33), ('林xiu霞', 32), ('醫鬧薛之謙', 32), ('wyx518052', 31), ('午后陽光喵喵', 29), ('藍天太陽我喜他', 29), ('不死就作的sr', 29), ('李遇可愛啵', 29), ('家駒一生所愛', 28)]
- #李微博評論粉絲統計
- [('方鹿亓', 139), ('0o夜雨狂瀾o0', 120), ('藍魅丶影', 98), ('mingyuanmumei', 76), ('曉清Z', 75), ('謙謙家的暴發戶', 65), ('一個玥寶貝兒', 64), ('qinglongzhilian', 62), ('出門左轉滾', 60), ('用戶5909206841', 58), ('水里的魚188啊', 56), ('story他說', 53), ('C平民', 52), ('斷斷續續的思考', 50), ('鏗客HXRK', 48), ('我的網名只有8個字', 48), ('愛吃魚的貓妮', 47), ('唯ai薛之謙', 46), ('用戶6213147659', 45), ('洛杉磯的咖喱雞', 44)]
emmmmmm,這個我就不分析了,大家寄幾理解吧。那個叫方鹿亓的,你出來,你說說,你咋那么閑呢?(逃
_(┐「ε:)_終于編…哦不…寫完了,大家慢慢消化,源碼已上傳至gayhub。