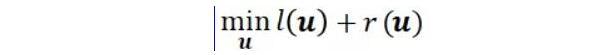輕量級(jí)大規(guī)模機(jī)器學(xué)習(xí)算法庫(kù)Fregata開(kāi)源:快速,無(wú)需調(diào)參
一. 大規(guī)模機(jī)器學(xué)習(xí)的挑戰(zhàn)
隨著互聯(lián)網(wǎng),移動(dòng)互聯(lián)網(wǎng)的興起,可以獲取的數(shù)據(jù)變得越來(lái)越多,也越來(lái)越豐富。數(shù)據(jù)資源的豐富,給機(jī)器學(xué)習(xí)帶來(lái)了越來(lái)越多,越來(lái)越大創(chuàng)造價(jià)值的機(jī)會(huì)。 機(jī)器學(xué)習(xí)在計(jì)算廣告,推薦系統(tǒng)這些價(jià)值上千億美元的應(yīng)用中起到的作用越來(lái)越大,創(chuàng)造的價(jià)值也越來(lái)越大。但是越來(lái)越大的數(shù)據(jù)規(guī)模也給機(jī)器學(xué)習(xí)帶來(lái)了很多挑戰(zhàn)。
最大的挑戰(zhàn)就是龐大的數(shù)據(jù)量使得對(duì)計(jì)算資源的需求也急劇增長(zhǎng)。首先經(jīng)典的機(jī)器學(xué)習(xí)算法其計(jì)算量基本上都是與訓(xùn)練數(shù)據(jù)條數(shù)或者特征數(shù)量呈二次方甚至是三次方關(guān)系的[1]。即是說(shuō)數(shù)據(jù)量或者特征數(shù)每翻一倍,則計(jì)算量就要增加到原來(lái)的四倍,甚至是八倍。這樣的計(jì)算量增長(zhǎng)是十分可怕的,即使是采用可擴(kuò)展的計(jì)算機(jī)集群一難以滿(mǎn)足這樣的計(jì)算量增長(zhǎng)。好在對(duì)于很多依賴(lài)于凸優(yōu)化方法的算法,可以采用隨機(jī)梯度下降方法,將計(jì)算量的增長(zhǎng)降到基本與數(shù)據(jù)量和特征數(shù)呈線(xiàn)性關(guān)系。但是,大規(guī)模機(jī)器學(xué)習(xí)在計(jì)算上依然有三個(gè)比較大的困難。
第一,因?yàn)閹缀跛械臋C(jī)器學(xué)習(xí)算法都需要多次掃描數(shù)據(jù),對(duì)于大規(guī)模數(shù)據(jù)無(wú)論在什么平臺(tái)上,如果不能全部存儲(chǔ)在內(nèi)存中,就需要反復(fù)從磁盤(pán)存儲(chǔ)系統(tǒng)中讀取數(shù)據(jù),帶來(lái)巨大的IO開(kāi)銷(xiāo)。在很多情況下,IO開(kāi)銷(xiāo)占到整個(gè)訓(xùn)練時(shí)間的90%以上。
第二,即使有足夠的資源將所有數(shù)據(jù)都放到內(nèi)存中處理,對(duì)于分布式的計(jì)算系統(tǒng),模型訓(xùn)練過(guò)程中對(duì)模型更新需要大量的網(wǎng)絡(luò)通信開(kāi)銷(xiāo)。無(wú)論是同步更新還是異步更新,龐大的數(shù)據(jù)量和特征數(shù)都足以使得通信量爆炸,這是大規(guī)模機(jī)器學(xué)習(xí)的另外一個(gè)瓶頸。
第三,大規(guī)模的模型使得無(wú)法在一個(gè)節(jié)點(diǎn)上存儲(chǔ)整個(gè)模型,如何將模型進(jìn)行分布式的管理也是一個(gè)比較大的挑戰(zhàn)。
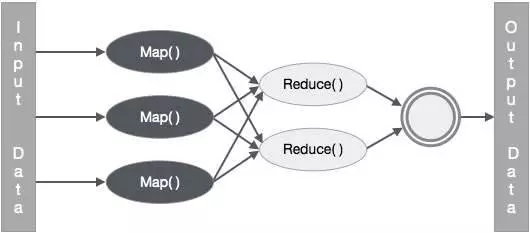
圖 1
目前的主流大數(shù)據(jù)處理技術(shù)都是以Map Reduce計(jì)算模式為核心的(包括Hadoop和Spark)。而Map Reduce計(jì)算模式下對(duì)第一個(gè)問(wèn)題只能通過(guò)增加內(nèi)存,SSD存儲(chǔ)來(lái)解決或者緩解,但同時(shí)也需要付出高昂的成本。對(duì)于第二,和第三個(gè)個(gè)問(wèn)題,Map Reduce模式的局限是很難克服這兩個(gè)問(wèn)題的。
而Parameter Server[2]作為目前最新的大規(guī)模機(jī)器學(xué)習(xí)系統(tǒng)設(shè)計(jì)模式,主要解決的其實(shí)是第三個(gè)問(wèn)題,通過(guò)參數(shù)服務(wù)器以及模型參數(shù)的分布式管理來(lái)實(shí)現(xiàn)對(duì)超大規(guī)模模型的支持。同時(shí)在模型更新過(guò)程中的通信模式可以采用異步更新模式,來(lái)減小數(shù)據(jù)同步的開(kāi)銷(xiāo),提高通信效率,但是Parameter Server模式下模型的更新量計(jì)算和模型的更新是分離的,其龐大的通信開(kāi)銷(xiāo)在原理上就是不可避免的。幸運(yùn)的是,常見(jiàn)的大規(guī)模機(jī)器學(xué)習(xí)問(wèn)題,都是高維稀疏問(wèn)題,在很大程度上緩解了通信開(kāi)銷(xiāo)的問(wèn)題,而Parameter Server突破了模型規(guī)模限制的優(yōu)點(diǎn)是Map Reduce模式無(wú)法取代的,所以Parameter Server成為了目前大規(guī)模機(jī)器學(xué)習(xí)最先進(jìn),最受認(rèn)可的模式。
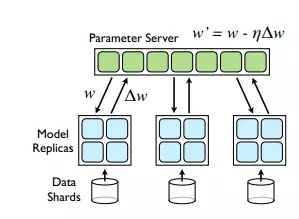
圖 2
雖然Parameter Server解決了模型分布式管理的瓶頸,異步通信模式和問(wèn)題本身的稀疏性大大降低了通信的壓力。 但是機(jī)器學(xué)習(xí)算法本身對(duì)數(shù)據(jù)的多次掃描帶來(lái)的計(jì)算和通信開(kāi)銷(xiāo)依然是大規(guī)模機(jī)器學(xué)習(xí)效率的很大瓶頸。
除此之外還有一個(gè)很大的挑戰(zhàn)就是算法的調(diào)參工作, 一般機(jī)器學(xué)習(xí)算法都會(huì)依賴(lài)一個(gè)或者多個(gè)參數(shù),對(duì)于同一問(wèn)題,不同的參數(shù)設(shè)定對(duì)模型精度的影響是很大的,而同一參數(shù)設(shè)定在不同的問(wèn)題上的效果也有很大的不同。對(duì)于從事機(jī)器學(xué)習(xí)工作的人來(lái)說(shuō),調(diào)參始終是一個(gè)令人的頭疼的問(wèn)題。知乎上有個(gè)問(wèn)題是“調(diào)參這事兒,為什么越干越覺(jué)得像老中醫(yī)看病?”[3],里面有不少關(guān)于機(jī)器學(xué)習(xí)調(diào)參的經(jīng)驗(yàn),心得,吐槽和抖機(jī)靈。
對(duì)于大規(guī)模機(jī)器學(xué)習(xí)問(wèn)題,調(diào)參的難度顯然是更大的:
首先,一次訓(xùn)練和測(cè)試過(guò)程的時(shí)間和計(jì)算資源開(kāi)銷(xiāo)都是龐大的,不管采用什么調(diào)參方法,多次實(shí)驗(yàn)都會(huì)帶來(lái)很大的時(shí)間和計(jì)算資源消耗。
其次,大規(guī)模機(jī)器學(xué)習(xí)問(wèn)題通常都是數(shù)據(jù)變化很快的問(wèn)題,如計(jì)算廣告和推薦系統(tǒng),之前確定好的參數(shù)在隨著數(shù)據(jù)的變化,也有劣化的風(fēng)險(xiǎn)。
目前來(lái)說(shuō)大規(guī)模機(jī)器學(xué)習(xí)存在的主要挑戰(zhàn)是兩個(gè):第一是計(jì)算資源的消耗比較大,訓(xùn)練時(shí)間較長(zhǎng)的問(wèn)題,第二是調(diào)參比較困難,效率較低。TalkingData在大規(guī)模機(jī)器學(xué)習(xí)的實(shí)踐中也深受這兩個(gè)問(wèn)題的困然,特別是公司在早起階段硬件資源十分有限,這兩個(gè)問(wèn)題特別突出。我們?yōu)榱私鉀Q這個(gè)問(wèn)題,做了很多努力和嘗試。TalkingData最近開(kāi)源的Fregata項(xiàng)目[4],就是我們?cè)谶@方面取得的一些成果的總結(jié)。
二. Fregata的優(yōu)點(diǎn)
Fregata是TalkingData開(kāi)源的大規(guī)模機(jī)器學(xué)習(xí)算法庫(kù),基于Spark,目前支持Spark 1.6.x, 很快會(huì)支持Spark 2.0。目前Fregata包括了Logistic Regression, Softmax, 和Random Decision Trees三中算法。
三種算法中Logistic Regression, Softmax可以看作一類(lèi)廣義線(xiàn)性的參數(shù)方法,其訓(xùn)練過(guò)程都依賴(lài)于凸優(yōu)化方法。我們提出了Greedy Step Averaging[5]優(yōu)化方法,在SGD優(yōu)化方法基礎(chǔ)上實(shí)現(xiàn)了學(xué)習(xí)率的自動(dòng)調(diào)整,免去了調(diào)參的困擾,大量的實(shí)驗(yàn)證明采用GSA 優(yōu)化方法的Logstic Regression和Softmax算法的收斂速度和穩(wěn)定性都是非常不錯(cuò)的,在不同數(shù)據(jù)規(guī)模,不同維度規(guī)模和不同稀疏度的問(wèn)題上都能取得很好的精度和收斂速度。
基于GSA優(yōu)化方法,我們?cè)赟park上實(shí)現(xiàn)了并行的Logistic Regression和Softmax算法,我們測(cè)試了很多公開(kāi)數(shù)據(jù)集和我們自己的數(shù)據(jù),發(fā)現(xiàn)在絕大部分?jǐn)?shù)據(jù)上都能夠掃描一遍數(shù)據(jù)即收斂。這就大大降低了IO開(kāi)銷(xiāo)和通信開(kāi)銷(xiāo)。
其中Logsitic Regression算法還有一個(gè)支持多組特征交叉的變種版本,其不同點(diǎn)是在訓(xùn)練過(guò)程中完成維度交叉,這樣就不需要在數(shù)據(jù)準(zhǔn)備過(guò)程中將多組特征維度預(yù)先交叉準(zhǔn)備好,通常這意味著數(shù)據(jù)量級(jí)上的數(shù)據(jù)量膨脹,給數(shù)據(jù)存儲(chǔ)和IO帶來(lái)極大壓力。而這種多組特征交叉的需求在計(jì)算廣告和推薦系統(tǒng)中又是非常常見(jiàn)的,因此我們對(duì)此做了特別的支持。
而Random Decision Trees[6][7]算法是高效的非參數(shù)學(xué)習(xí)方法,可以處理分類(lèi),多標(biāo)簽分類(lèi),回歸和多目標(biāo)回歸等問(wèn)題。而且調(diào)參相對(duì)也是比較簡(jiǎn)單的。但是由于樹(shù)結(jié)構(gòu)本身比較復(fù)雜而龐大,使得并行比較困難,我們采用了一些Hash Trick使得對(duì)于二值特征的數(shù)據(jù)可以做到掃描一遍即完成訓(xùn)練,并且在訓(xùn)練過(guò)程中對(duì)內(nèi)存消耗很少。
總結(jié)起來(lái),F(xiàn)regata的優(yōu)點(diǎn)就兩個(gè),第一是速度快,第二是算法無(wú)需調(diào)參或者調(diào)參相對(duì)簡(jiǎn)單。這兩個(gè)優(yōu)點(diǎn)降低了減少了計(jì)算資源的消耗,提高了效率,同時(shí)也降低了對(duì)機(jī)器學(xué)習(xí)工程師的要求,提高了他們的工作效率。
三. GSA算法介紹
GSA算法是我們最近提出的梯度型隨機(jī)優(yōu)化算法,是Fregata采用的核心優(yōu)化方法。它是基于隨機(jī)梯度下降法(SGD)的一種改進(jìn):保持了SGD易于實(shí)現(xiàn),內(nèi)存開(kāi)銷(xiāo)小,便于處理大規(guī)模訓(xùn)練樣本的優(yōu)勢(shì),同時(shí)免去了SGD不得不人為調(diào)整學(xué)習(xí)率參數(shù)的麻煩。
事實(shí)上,最近幾年關(guān)于SGD算法的步長(zhǎng)選取問(wèn)題也有一些相關(guān)工作,像Adagrad, Adadelta, Adam等。但這些方法所聲稱(chēng)的自適應(yīng)步長(zhǎng)策略其實(shí)是把算法對(duì)學(xué)習(xí)率的敏感轉(zhuǎn)移到了其他參數(shù)上面,并未從本質(zhì)上解決調(diào)參的問(wèn)題,而且他們也引入了額外的存儲(chǔ)開(kāi)銷(xiāo)。GSA和這些算法相比更加輕量級(jí),易于實(shí)現(xiàn)且易于并行,比起SGD沒(méi)有額外的內(nèi)存開(kāi)銷(xiāo),而且真正做到了不依賴(lài)任何參數(shù)。
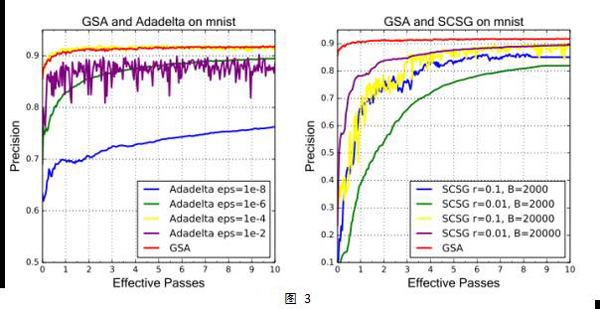
我們把GSA算法應(yīng)用于Logistic回歸和Softmax回歸,對(duì)libsvm上16個(gè)不同類(lèi)型規(guī)模不等的數(shù)據(jù)集,和SGD,Adadelta,SCSG(SVRG的變種)這些目前流行的隨機(jī)優(yōu)化算法做了對(duì)比實(shí)驗(yàn)。結(jié)果顯示,GSA算法在無(wú)需調(diào)任何參數(shù)的情況下,和其他算法做參數(shù)調(diào)優(yōu)后的最佳表現(xiàn)不相上下。此外,GSA比起這些流行的方法在計(jì)算速度和內(nèi)存開(kāi)銷(xiāo)方面也有一定的優(yōu)勢(shì)。
GSA算法的核心原理非常簡(jiǎn)單:在迭代的每一步對(duì)單個(gè)樣本的損失函數(shù)做線(xiàn)搜索。具體來(lái)說(shuō),我們對(duì)邏輯回歸和softmax回歸的交叉熵?fù)p失函數(shù),推導(dǎo)出了一套僅用當(dāng)前樣本點(diǎn)的梯度信息來(lái)計(jì)算精確線(xiàn)搜索步長(zhǎng)的近似公式。我們把利用這套近似公式得到的步長(zhǎng)做時(shí)間平均來(lái)計(jì)算當(dāng)前迭代步的學(xué)習(xí)率。這樣做有兩方面的好處:基于精確線(xiàn)搜索得到的步長(zhǎng)包含了當(dāng)前迭代點(diǎn)到全局極小的距離信息——接近收斂時(shí)步長(zhǎng)比較小,反之則更大,因而保證收斂速度;另一方面平均策略使算法對(duì)離群點(diǎn)更魯棒,損失下降曲線(xiàn)不至劇烈抖動(dòng),為算法帶來(lái)了額外的穩(wěn)定性。
四. GSA算法Spark上的并行化實(shí)現(xiàn)
GSA算法是基本的優(yōu)化方法,在Spark上還需要考慮算法并行化的問(wèn)題。機(jī)器學(xué)習(xí)算法的并行化有兩種方式,一種是數(shù)據(jù)并行,另一種是模型并行。但是Spark只能支持?jǐn)?shù)據(jù)并行,因?yàn)槟P筒⑿袝?huì)產(chǎn)生大量細(xì)粒度的節(jié)點(diǎn)間通信開(kāi)銷(xiāo),這是Spark采用的BSP同步模式無(wú)法高效處理的。
數(shù)據(jù)并行模式下進(jìn)行機(jī)器學(xué)習(xí)算法的并行化又有三種方法,分別是梯度平均,模型平均,以及結(jié)果平均。梯度平均是在各個(gè)數(shù)據(jù)分片上計(jì)算當(dāng)前的梯度更新量然后匯總平均各分片上的梯度更新量總體更新模型。模型平均是各分片訓(xùn)練自己的模型,然后再將模型匯總平均獲得一個(gè)總體的模型。而結(jié)果平均實(shí)際上就是Ensemble Learning, 在大規(guī)模問(wèn)題上因?yàn)槟P鸵?guī)模的問(wèn)題,并不是一個(gè)好的選擇。
實(shí)際上是目前采用得最多的是梯度平均,當(dāng)前Parameter Server各種實(shí)現(xiàn)上主要還是用來(lái)支持這種方式,Spark MLLib的算法實(shí)現(xiàn)也是采用的該方式。但是在Spark上采用梯度平均在效率上也有比較大的瓶頸,因該方法計(jì)算當(dāng)前的梯度更新量是要依賴(lài)于當(dāng)前的最新模型的,這就帶來(lái)了在各數(shù)據(jù)分片之間頻繁的模型同步開(kāi)銷(xiāo),這對(duì)Map Reuce計(jì)算模式的壓力是較大的。
模型平均一直被認(rèn)為其收斂性在理論上是沒(méi)有保證的,但是最近Rosenblatt[8]等人證明了模型平均的收斂性。而我們?cè)诖罅康臏y(cè)試中,也發(fā)現(xiàn)模型平均通常能取得非常好的模型精度。考慮到模型平均的計(jì)算模式更適合Map Reduce計(jì)算模型,我們?cè)贔regata中對(duì)于GSA算法的并行方法采用的就是模型平均方法。模型平均的并行方法中,每個(gè)數(shù)據(jù)分片在Map階段訓(xùn)練自己的模型,最后通過(guò)Reduce操作對(duì)各個(gè)分片上的模型進(jìn)行平均,掃描一次數(shù)據(jù)僅需要做一次模型同步。而且在大量的實(shí)驗(yàn)中,該方法在掃描一次數(shù)據(jù)后,模型的精度就可達(dá)到很高的水平,基本接近于更多次迭代后的最好結(jié)果。
五. Fregata與MLLib對(duì)比
Fregata是基于Spark的機(jī)器學(xué)習(xí)算法庫(kù),因此與Spark內(nèi)置算法庫(kù)MLLib具有很高的可比性。我們這里簡(jiǎn)要介紹了三個(gè)數(shù)據(jù)集,兩種算法(Logistic Regression和Softmax)上的精度和訓(xùn)練時(shí)間對(duì)比。精度指標(biāo)我們采用的是測(cè)試集的AUC。對(duì)于精度和訓(xùn)練時(shí)間,算法每掃描完一次數(shù)據(jù)記錄一次。
Fregata的算法不需要調(diào)參,因此我們都只做了一次實(shí)驗(yàn)。而對(duì)于MLLib上的算法,我們?cè)诟鞣N參數(shù)組合(包括優(yōu)化方法的選擇)中進(jìn)行了網(wǎng)格搜索,選取了測(cè)試集AUC能達(dá)到最高的那組參數(shù)作為對(duì)比結(jié)果。
Lookalike是一個(gè)基于Fregata平臺(tái)運(yùn)用比較成熟的服務(wù),其目標(biāo)在于根據(jù)種子人群進(jìn)行人群放大以尋找潛在客戶(hù)。我們將Lookalike作為二分類(lèi)問(wèn)題來(lái)處理,因此可以采用Logistic Regression算法來(lái)處理。在訓(xùn)練模型時(shí)以種子人群為正樣本,其他為負(fù)樣本,通常種子人群的數(shù)量不會(huì)很多,因此Lookalike通常是正樣本比例非常少的class imblance問(wèn)題。 在一個(gè)大規(guī)模數(shù)據(jù)集(4億樣本,2千萬(wàn)個(gè)特征)上的Lookalike問(wèn)題的模型訓(xùn)練中,我們對(duì)比了Fregata LR和MLLib LR的性能。
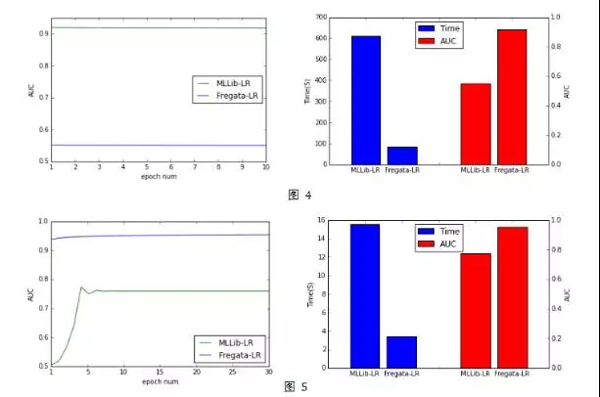
從圖4中可以看到Fregata的LR算法掃描一次數(shù)據(jù)即收斂達(dá)到AUC(測(cè)試集上)的最高值0.93。在這個(gè)數(shù)據(jù)樣本中 而MLLib的LR算法,即使我們通過(guò)調(diào)參選取了最好的AUC結(jié)果,其AUC也僅為0.55左右。模型預(yù)測(cè)精度差別非常大。另外,MLLib的訓(xùn)練時(shí)間(達(dá)到最高精度的時(shí)間)也是Fregata大的6倍以上。
在公開(kāi)數(shù)據(jù)集eplison[9]上(40萬(wàn)訓(xùn)練集,2000特征), Fregata LR無(wú)論從收斂速度還是模型效果與MLLib LR相比也有較大的優(yōu)勢(shì)。從圖5中可以看到,在這個(gè)數(shù)據(jù)集上Fregata LR在迭代一次以后就在測(cè)試集上非常接近最好的結(jié)果了,而MLLib LR需要5次迭代而且最高的精度比Fregata LR相差很大,而訓(xùn)練時(shí)間MLLib LR也是Fregata LR的5倍以上。
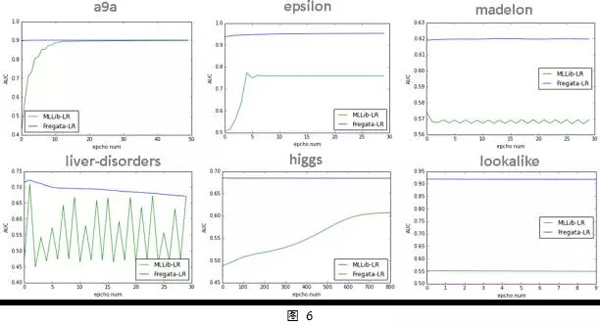
另外圖6展示了Fregata LR與MLLib LR在6個(gè)不同問(wèn)題上的測(cè)試集AUC曲線(xiàn),可以看到Fregata LR算法在不同問(wèn)題上收斂速度和穩(wěn)定性相較于MLLib LR都是有較大的優(yōu)勢(shì)。Fregata LR在第一次迭代后,AUC就已經(jīng)基本收斂,即使與最高值還有一些差距,但是也是非常接近了。
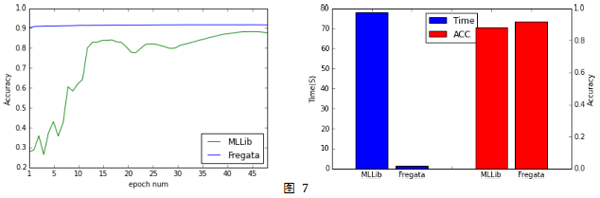
我們也在公開(kāi)數(shù)據(jù)集MNIST上測(cè)試了Softmax算法。 從圖7中可以看到, Fregata Softmax也是一次掃描數(shù)據(jù)后在測(cè)試集上的AUC就非常接近最好的結(jié)果, 而MLLib Softmax需要掃描數(shù)據(jù)多達(dá)40多次以后才接近Fregata Softmax一次掃描數(shù)據(jù)的結(jié)果。對(duì)比兩個(gè)算法在達(dá)到各自最優(yōu)結(jié)果所花的時(shí)間,MLLib Softmax是Fregata Softmax的50倍以上。
六. Fregata的使用簡(jiǎn)介
前面簡(jiǎn)要介紹了Fregata算法庫(kù)涉及到的一些技術(shù)原理和性能對(duì)比,我們?cè)賮?lái)看看Fregata的使用方式。可以通過(guò)3種不同的方式來(lái)獲取Fregata如果使用Maven來(lái)管理工程,則可以通過(guò)添加如下代碼在pom.xml中進(jìn)行引入,
- <dependency>
- <groupId>com.talkingdata.fregata</groupId>
- <artifactId>core</artifactId>
- <version>0.0.1</version>
- </dependency>
- <dependency>
- <groupId>com.talkingdata.fregata</groupId>
- <artifactId>spark</artifactId>
- <version>0.0.1</version>
- </dependency>
如果使用SBT來(lái)管理工程,則可以通過(guò)如下代碼在build.sbt中進(jìn)行引入,
- // 如果手動(dòng)部署到本地maven倉(cāng)庫(kù),請(qǐng)將下行注釋打開(kāi)
- // resolvers += Resolver.mavenLocal
- libraryDependencies += "com.talkingdata.fregata" % "core" % "0.0.1"
- libraryDependencies += "com.talkingdata.fregata" % "spark" % "0.0.1"
如果希望手動(dòng)部署到本地maven倉(cāng)庫(kù),可以通過(guò)在命令中執(zhí)行如下命令來(lái)完成:
- git clone https://github.com/TalkingData/Fregata.git
- cd Fregata
- mvn clean package install
接下來(lái),讓我們以L(fǎng)ogistic Regression為例來(lái)看看如何快速使用Fregata完成分類(lèi)任務(wù):
1.引入所需包
- import fregata.spark.data.LibSvmReader
- import fregata.spark.metrics.classification.{AreaUnderRoc, Accuracy}
- import fregata.spark.model.classification.LogisticRegression
- import org.apache.spark.{SparkConf, SparkContext}
2. 通過(guò)Fregata的LibSvmReader接口加載訓(xùn)練及測(cè)試數(shù)據(jù)集,訓(xùn)練及測(cè)試數(shù)據(jù)集為標(biāo)準(zhǔn)LibSvm格式,可參照[10]
- val (_, trainData) = LibSvmReader.read(sc, trainPath, numFeatures.toInt)
- val (_, testData) = LibSvmReader.read(sc, testPath, numFeatures.toInt)
3. 針對(duì)訓(xùn)練樣本訓(xùn)練Logsitic Regression 模型
- val model = LogisticRegression.run(trainData)
4. 基于已經(jīng)訓(xùn)練完畢的模型對(duì)測(cè)試樣本進(jìn)行預(yù)測(cè)
- val pd = model.classPredict(testData)
5. 通過(guò)Fregata內(nèi)置指標(biāo)評(píng)價(jià)模型效果
- val auc = AreaUnderRoc.of( pd.map{
- case ((x,l),(p,c)) =>
- p -> l
- })
在Fregata中,使用breeze.linalg.Vector[Double]來(lái)存儲(chǔ)一個(gè)樣本的特征,如果數(shù)據(jù)格式已經(jīng)是LibSvm,則只需通過(guò)Fregata內(nèi)部的接口LibSvmReader.read(…)來(lái)加載即可。否則,可以采用如下的方法將代表實(shí)例的一組數(shù)據(jù)封裝成breeze.linalg.Vector[Double]即可放入模型中進(jìn)行訓(xùn)練及測(cè)試。
- // indices Array類(lèi)型,下標(biāo)從0開(kāi)始,保存不為0的數(shù)據(jù)下標(biāo)
- // values Array類(lèi)型, 保存相應(yīng)于indices中對(duì)應(yīng)下標(biāo)的數(shù)據(jù)值
- // length Int類(lèi)型,為樣本總特征數(shù)
- // label Double類(lèi)型,為樣本的標(biāo)簽。如果是測(cè)試數(shù)據(jù),則不需該字段
- sc.textFile(input).map{
- val indicies = ...
- val values = ...
- val label = ...
- ...
- (new SparseVector(indices, values, length).asInstanceOf[Vector], asNum(label))
- }
七. Freagata的發(fā)展目標(biāo)
Fregata目前集成的算法還不多,未來(lái)還會(huì)繼續(xù)擴(kuò)充更多的高效的大規(guī)模機(jī)器學(xué)習(xí)算法。Fregata項(xiàng)目追求的目標(biāo)有3個(gè):輕量級(jí),高性能,易使用。
輕量級(jí)是指Fregata將盡可能在標(biāo)準(zhǔn)Spark版本上實(shí)現(xiàn)算法,不另外搭建計(jì)算系統(tǒng),使得Fregata能夠非常容易的在標(biāo)準(zhǔn)Spark版本上使用。雖然Spark有一些固有的限制,比如對(duì)模型規(guī)模的限制,但是作為目前大數(shù)據(jù)處理的基礎(chǔ)工具,F(xiàn)regata對(duì)其的支持能夠大大降低大規(guī)模機(jī)器學(xué)習(xí)的應(yīng)用門(mén)檻。畢竟另外搭建一套專(zhuān)用大規(guī)模機(jī)器學(xué)習(xí)計(jì)算平臺(tái),并整合到整個(gè)大數(shù)據(jù)處理平臺(tái)和流程中,其成本和復(fù)雜性也是不可忽視的。
高性能就是堅(jiān)持高精度和高效率并舉的目標(biāo),盡可能從算法上和工程實(shí)現(xiàn)上將算法的精度和效率推到極致,使得大規(guī)模機(jī)器學(xué)習(xí)算法從笨重的牛刀變成輕快的匕首。目前對(duì)Fregata一個(gè)比較大的限制就是模型規(guī)模的問(wèn)題,這是基于Spark天生帶來(lái)的劣勢(shì)。未來(lái)會(huì)采用一些模型壓縮的方法來(lái)緩解這個(gè)問(wèn)題。
易使用也是Fregata追求的一個(gè)目標(biāo),其中最重要的一點(diǎn)就是降低調(diào)參的難度。目前的三個(gè)算法中有兩個(gè)是免調(diào)參的,另一個(gè)也是相對(duì)來(lái)說(shuō)調(diào)參比較友好的算法。降低了調(diào)參的難度,甚至是免去了調(diào)參的問(wèn)題,將大大降低模型應(yīng)用的難度和成本,提高工作效率。
另一方面我們也會(huì)考慮某些常用場(chǎng)景下的特殊需求,比如LR算法的特征交叉需求。雖然通用的LR算法效率已經(jīng)很高,但是對(duì)于特征交叉這種常見(jiàn)需求,如果不把特征交叉這個(gè)過(guò)程耦合到算法中去,就需要預(yù)先將特征交叉好,這會(huì)帶來(lái)巨大的IO開(kāi)銷(xiāo)。而算法實(shí)現(xiàn)了對(duì)特征交叉的支持,就規(guī)避了這個(gè)效率瓶頸。未來(lái)在集成更多的算法的同時(shí),也會(huì)考慮各種常用的場(chǎng)景需要特殊處理的方式。
Fregata項(xiàng)目名稱(chēng)的中文是軍艦鳥(niǎo),TalkingData的開(kāi)源項(xiàng)目命名都是用的鳥(niǎo)名,而軍艦鳥(niǎo)是世界上飛得最快的鳥(niǎo),最高時(shí)速達(dá)到418km/小時(shí),體重最大1.5公斤,而翼展能夠達(dá)到2.3米,在全球分布也很廣泛。我們希望Fregata項(xiàng)目能夠像軍艦鳥(niǎo)一樣,體量輕盈,但是能夠支持大規(guī)模,高效的機(jī)器學(xué)習(xí),而且具有很強(qiáng)的適用性。目前Fregata還是只雛鳥(niǎo), 期望未來(lái)能夠成長(zhǎng)為一只展翅翱翔的猛禽。
引用
[1] Cheng T. Chu, Sang K. Kim, Yi A. Lin, Yuanyuan Yu, Gary R. Bradski, Andrew Y. Ng, Kunle Olukotun, Map-Reduce for Machine Learning on Multicore, NIPS, 2006.
[2]
[3] https://www.zhihu.com/question/48282030
[4] https://github.com/TalkingData/Fregata
[5] http://arxiv.org/abs/1611.03608
[6] http://www.ibm.com/developerworks/cn/analytics/library/ba-1603-random-decisiontree-algorithm-1/index.html
[7] http://www.ibm.com/developerworks/cn/analytics/library/ba-1603-random-decisiontree-algorithm-2/index.html
[8] Rosenblatt J D, Nadler B. On the optimality of averaging in distributed statistical learning[J]. Information and Inference, 2016: iaw013 MLA
[9] https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary.html#epsilon
[10] https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/
作者介紹
張夏天:TalkingData首席數(shù)據(jù)科學(xué)家,12年大規(guī)模機(jī)器學(xué)習(xí)和數(shù)據(jù)挖掘經(jīng)驗(yàn),對(duì)推薦系統(tǒng)、計(jì)算廣告、大規(guī)模機(jī)器學(xué)習(xí)算法并行化、流式機(jī)器學(xué)習(xí)算法有很深的造詣;在國(guó)際頂級(jí)會(huì)議和期刊上發(fā)表論文12篇,申請(qǐng)專(zhuān)利9項(xiàng);前IBM CRL、騰訊、華為諾亞方舟實(shí)驗(yàn)室數(shù)據(jù)科學(xué)家;KDD2015、DSS2016國(guó)際會(huì)議主題演講;機(jī)器學(xué)習(xí)開(kāi)源項(xiàng)目Dice創(chuàng)始人。