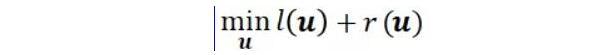無需大規模預訓練,清華提出高效NLP學習框架TLM
近期,來自清華大學的研究者們提出了一種簡單高效的 NLP 學習框架。不同于當下 NLP 社區主流的大規模預訓練 + 下游任務微調(pretraining-finetuning)的范式,這一框架無需進行大規模預訓練。相較于傳統的預訓練語言模型,該框架將訓練效率 (Training FLOPs) 提升了兩個數量級,并且在多個 NLP 任務上實現了比肩甚至超出預訓練模型的性能。這一研究結果對大規模預訓練語言模型的必要性提出了質疑:大規模預訓練對下游任務的貢獻究竟有多大?我們真的需要大規模預訓練來達到最好的效果嗎?

- 論文地址:https://arxiv.org/pdf/2111.04130.pdf
- 項目地址:https://github.com/yaoxingcheng/TLM
預訓練語言模型因其強大的性能被廣泛關注,基于預訓練 - 微調(pretraining-finetuning)的范式也已經成為許多 NLP 任務的標準方法。然而,當前通用語言模型的預訓練成本極其高昂,這使得只有少數資源充足的研究機構或者組織能夠對其展開探索。這種 「昂貴而集權」的研究模式限制了平民研究者們為 NLP 社區做出貢獻的邊界,甚至為該領域的長期發展帶來了障礙。
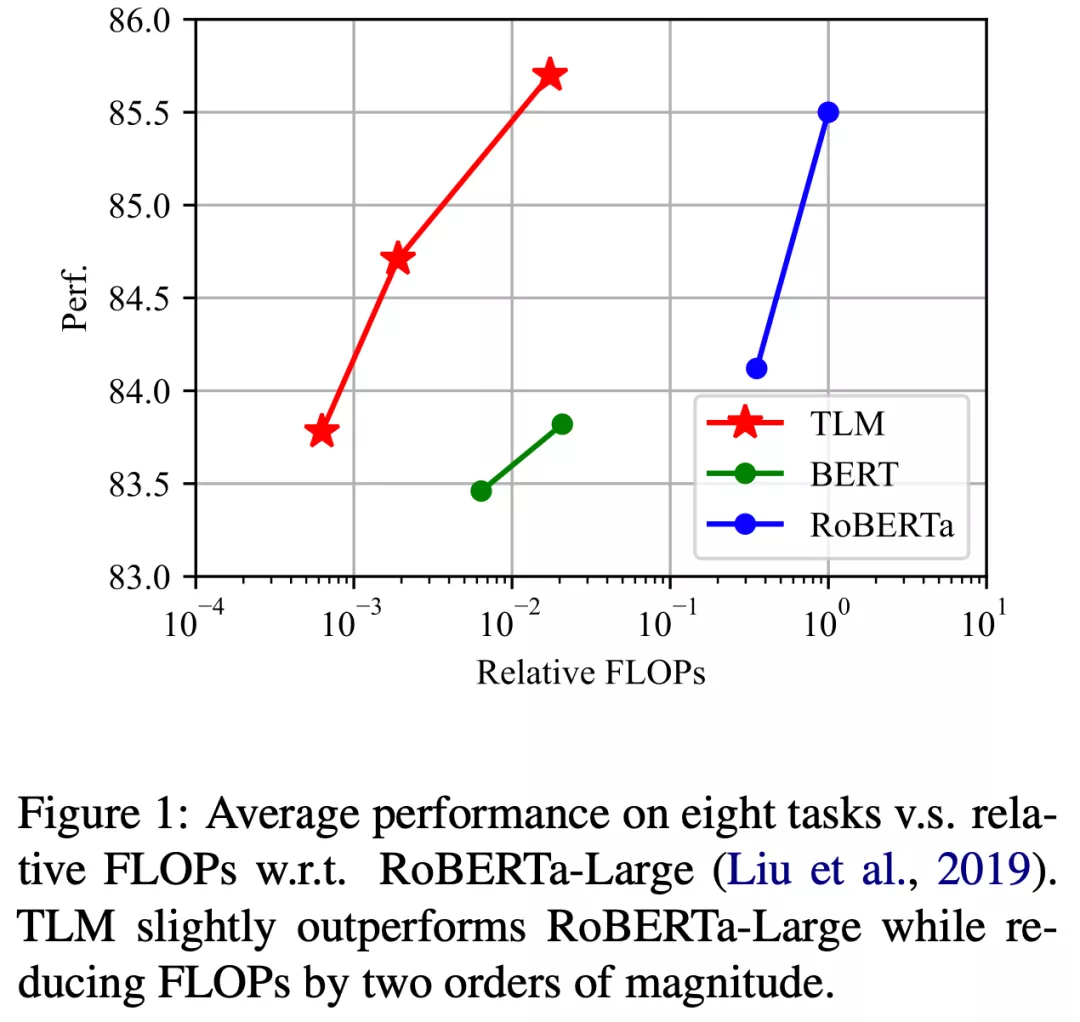
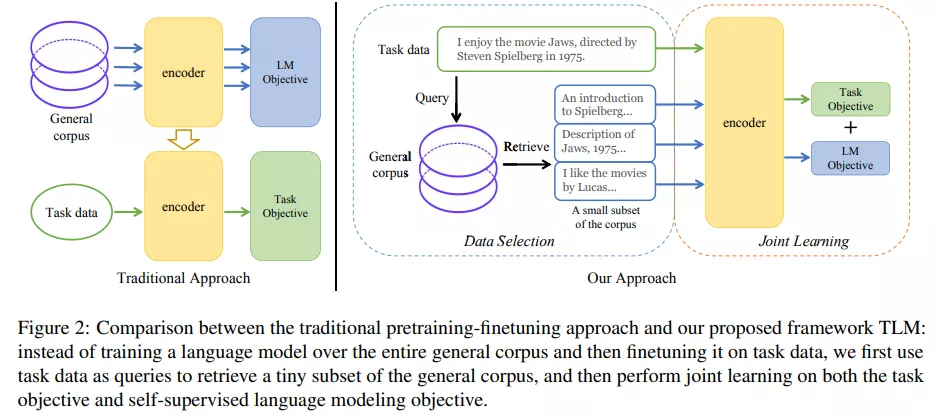
近期,為了緩解這一現狀,來自清華大學的研究者們提出的一種完全不需要預訓練語言模型的高效學習框架。這一框架從通用語料中篩選出與下游任務相關的子集,并將語言建模任務與下游任務進行聯合訓練。研究者們稱之為 TLM (Task-driven Language Modeling)。相較于傳統的預訓練模型(例如 RoBERTa),TLM 僅需要約 1% 的訓練時間與 1% 的語料,即可在眾多 NLP 任務上比肩甚至超出預訓練模型的性能(如圖 1 所示)。研究者們希望 TLM 的提出能夠引發更多對現有預訓練微調范式的思考,并推動 NLP 民主化的進程。
語言模型會「抱佛腳」嗎? 任務驅動的語言建模
TLM 提出的動機源于一個簡單的觀察:人類可以通過僅對關鍵信息的學習,以有限的時間和精力快速掌握某一任務技能。例如,在臨考抱佛腳時,焦慮的學生僅需要根據考綱復習瀏覽若干相關章節即可應對考試,而不必學習所有可能的知識點。類似地,我們也可以推測:預訓練語言模型在下游任務上的優良表現,絕大多數來源于語料中與下游任務相關的數據;僅利用下游任務相關數據,我們便可以取得與全量數據類似的結果。
為了從大規模通用語料中抽取關鍵數據,TLM 首先以任務數據作為查詢,對通用語料庫進行相似數據的召回。這里作者選用基于稀疏特征的 BM25 算法[2] 作為召回算法。之后,TLM 基于任務數據和召回數據,同時優化任務目標和語言建模目標 (如下圖公式所示),從零開始進行聯合訓練。
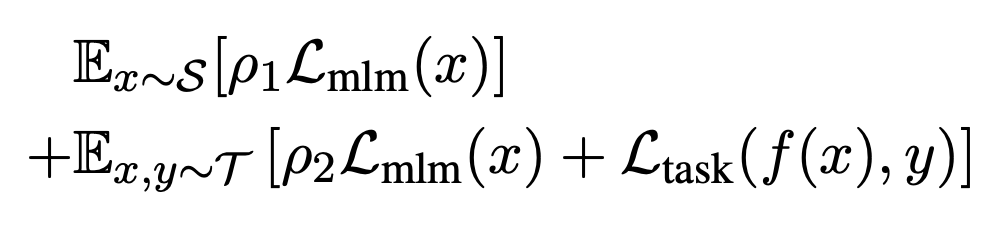
1% 的算力 + 1% 的語料即可比肩預訓練語言模型
為了測試 TLM 的性能,研究者們在 8 個 NLP 分類任務上從三個不同規模展開了對比實驗。這 8 個任務涵蓋了計算機科學、生物醫藥、新聞、評論等 4 個領域,包括了訓練樣本數量小于 5000 的低資源任務(Hyperpartisan News, ACL-ARC, SciERC, Chemprot)和訓練樣本數量大于 20000 的高資源任務(IMDB, AGNews, Helpfulness, RCT),覆蓋了話題分類,情感分類,實體關系抽取等任務類型。從實驗結果可以看出,和對應預訓練 - 微調基準相比,TLM 實現了相當甚至更優的性能。平均而言,TLM 減少了兩個數量級規模的訓練計算量 (Training FLOPs) 以及訓練語料的規模。
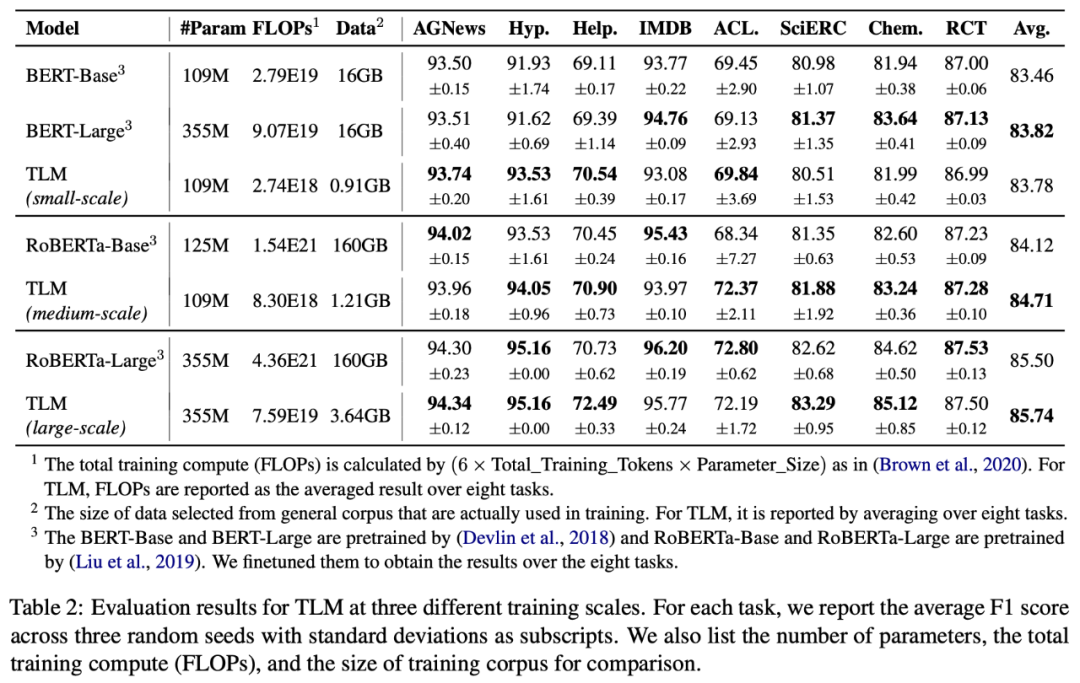
任務驅動的語言建模(TLM) vs 預訓練語言模型(PLMs)
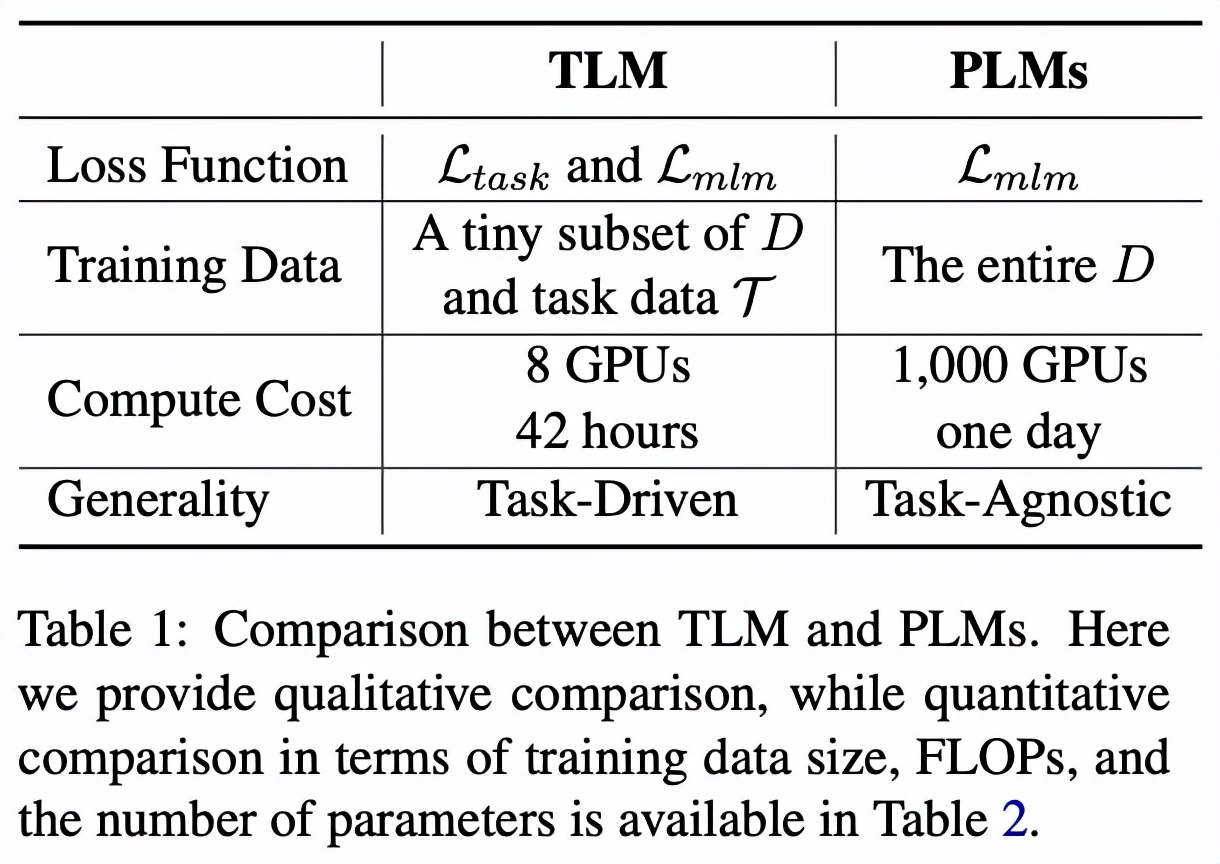
表格 1 直接對比了 TLM 和 PLM。整體來說,PLM 以極高的成本學習盡可能多的任務無關的知識,而 TLM 以非常低的成本針對每個任務學習相關知識。對比 TLM 和 PLM 有如下幾個方面特點。
1.推動 NLP 研究公平化和民主化(Democratization)
預訓練本身嚴重依賴大量的計算資源,這一限制使得大多數 NLP 研究者專項對微調算法的研究。然而微調性能上限很大程度上受預訓練模型性能的約束。而 TLM 使得大多數研究人員可以以較低的代價和較高的效率,基于最先進的解決方案對模型架構、損失函數、算法等方面進一步自由探索。
2. 高效性(Efficiency)
TLM 在平均每個任務的 FLOPs 消耗方面顯著優于 PLM。當我們有少數目標任務需要解決的時候(例如研究人員希望對少量幾個數據集進行研究),TLM 會是非常高效的;然而當需要一次性解決大量任務時(例如工業界構建一個 NLP 平臺為多方提供相似的服務),PLM 仍然具有優勢。
3. 靈活性(Flexibility)
TLM 是任務驅動的,所以可以給研究人員更大的自由度,從而自定義策略進行標記、序列長度、數據表示、超參數的調整等等,從而達到提高性能和效率的目的。
4. 通用性(Generality)
PLM 學習與任務無關的一般性表示,可用于小樣本和零樣本學習,而 TLM 通過學習任務相關的表示一定程度犧牲通用型換取效率。從這個意義上,TLM 需要在通用型方面進一步提升。此外也可以 PLM 和 TLM 結合從而在通用性和效率之間實現更好的權衡。
深入觀察 TLM:讓更多參數為下游任務服務

為了深入了解 TLM 的工作機制,研究人員對模型每個注意力頭所輸出的注意力分數進行了可視化。可以觀察到,TLM 的注意力模式中包含了更多的「對角線」模式(圖 3 紅框),也即大多 token 都將注意力分數集中賦予了其鄰近 token,這種模式已在前人的工作 [1] 中被證明對模型的最終預測有著重要貢獻。而預訓練模型(BERT, RoBERTa)中則包含了大量「垂直」模式的注意力頭(圖 3 灰色區域),也即大多 token 都將注意力分數集中賦予了 [CLS],[SEP] 或者句號這種毫無語義或者句法信息的詞匯上。這一現象表明 TLM 中參數利用率要顯著高于預訓練語言模型,TLM 或許針對下游任務學習到了更加富有語義信息的表示。
總結
TLM 的提出讓 NLP 研究跳脫出預訓練微調范式成為了可能,這使得 NLP 研究者們可以更為自由地探索新興的模型結構與訓練框架,而不拘泥于大規模預訓練模型。在未來,更多有趣的研究可以在 TLM 的基礎上展開,例如:如何經濟地達到更大規模預訓練模型的表現效果;如何提升 TLM 的通用性與可遷移性;可否利用 TLM 進行小樣本或零樣本學習等等。