深度學習入門課程學習筆記03 損失函數
前向傳播之-損失函數

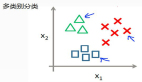
損失函數:在前面一節咱們介紹了得分函數,就是給定一個輸入,對于所有類別都要給出這個輸入屬于該類別的一個分值,如上圖所示,對于每一個輸入咱們都有了它屬于三個類別的得分,但是咱們光有這個得分卻不知道如何來評判現在的一個分類效果,這節課咱們就要用損失函數來評估分類效果的好壞,而且不光是好壞還要表現出來有多好有多壞!

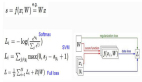
我們接下來就拿SVM的損失函數來說事吧。什么?你不知道SVM是啥?沒關系,我會用很簡單的語言來說這個損失函數的。對于SVM來說它的損失函數如上圖的公式所示,我們要算的就是對于一個輸入樣本,這個樣本的正確分類的分值和其他所有錯誤分類的分值的差值,再把這些所有的差值進行求和。我們拿這個小貓來舉例吧,就是用它正確分類的分3.2與其它錯誤分類的得分5.1和-1.7求差值,再把求得的差值和0進行對比,如果大于0就加在最終的LOSS值上。細心的同學可能發現了上面的公式還加了一個數值1,那么這個數值代表著什么呢?它的意思啊就是說咱們求出的得分差異值還要去和咱們的滿意程度進行比較,這個1就代表了咱們的滿意程度有多大,這個值越大呢就說明咱們的要求越高。

圖中紅色的區域就是咱們的滿意程度,一旦錯誤分類的得分(綠色區域)超過了紅色值,就是說沒達到咱們設定的滿意程度值,LOSS值就要開始增加了。
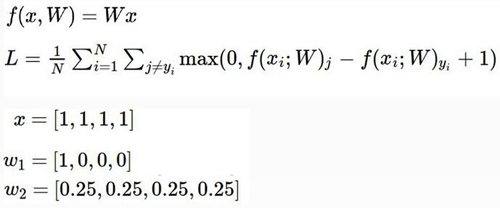
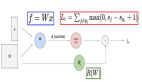
正則化:假設有一個樣本x=[1,1,1,1],現在咱們有兩組權重參數W1和W2如上圖所示,這樣對于得分值WX,兩組權重參數得出的結果都一樣,但是分值一樣能說明這兩個參數模型的分類效果一模一樣嗎?接下來就引入了咱們的正則化項來解決這個問題,正則化就是對權重參數進行懲罰,目的就是找到一組更平滑的參數項。正則化項的結果就是對于不同權重參數W進行不同力度的懲罰,懲罰也就是增加其LOSS值。正則化對于整個分類模型來說非常重要,可以很有效的抑制了過擬合現象。
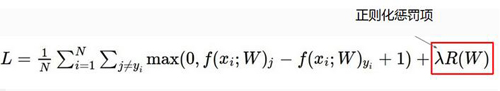
LOSS***版:由LOSS最終版的公式可以看到。LOSS是由兩部分組成的,一部分是得分函數對應的LOSS值另一個部分是正則化懲罰項的LOSS值。