Nervana技術深度解讀:使用Neon的端到端語音識別是如何實現的
語音是一種固有的即時信號。語音中所承載的信息元素在多個時間尺度上演變。在空氣壓強的影響下,同一個聲源的頻率只會發生幾百上千赫茲的變化,所以我們可以利用聲音去判斷一個聲源的位置,并把它與周圍嘈雜的環境區分開來以獲得傳遞的信息。語音的功率譜中的緩慢變化的部分就是音素(phoneme)的生成序列,其中音素是構成我們所說的詞的最小單位。除此之外,其中由單詞組成的序列的變化更緩慢,這些詞就組成了短語和敘事的結構。然而,這些元素在時間尺度上沒有嚴格的區分界限。相反,各種尺度的元素都混合在了一起,所以時間上下文是十分重要的,其中較為稀少的停頓就可以作為元素之間區分的界限。自動語音識別(ASR)系統就必須弄明白這種噪聲多尺度數據流,將其轉換為準確的單詞序列。
在撰寫本文時,當下最流行和成功的語音識別引擎采用了一種混合系統來構建。即同時將深度神經網絡(DNN)與隱藏馬爾科夫模型(HMMs),上下文相關電話模型(context-dependent phone models),n-gram 語言模型(n-gram language models),和一種維特比搜索算法(Viterbi search algorithms)的復雜變體進行混合使用。這個模型相當的復雜,需要一套精致的訓練方法,以及相當多的專業知識來幫助搭建模型。如果說深度學習的成功能教會我們什么東西,那就是我們可以經常用一種通用的神經網絡來替代復雜的,多維度的機器學習方法,這些神經網絡經過訓練以后可以用來優化可微分的代價函數(cost function)。這種方法(我們暫且把這種方法稱為「純正」的 DNN 方法),已經在語音識別上取得了巨大的成功。現在,一旦我們有了相當多的訓練數據和足夠的計算資源,我們就可以更加輕松地構建一個高水準的大詞匯量連續語音識別(Large Vocabulary Continuous Speech Recognition (LVCSR))系統。
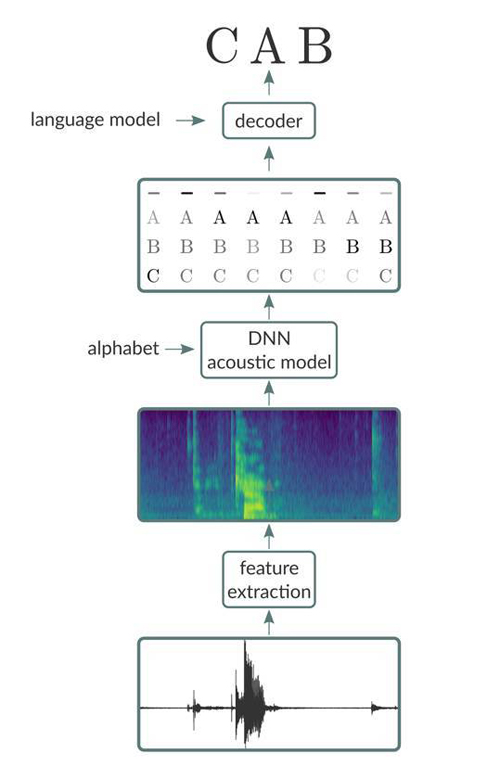
本文的目的是為了對如何使用 Neon 來建立一個使用「純正」DNN 方法的語音識別系統提供一種簡單的指導介紹,其中 DNN 遵循了 Graves 和 他協作者所倡導的方法,同時,百度的人工智能研究人員對其進行了進一步的開發,讓其成為了一種完整的端到端的 ASR 管道(end-to-end ASR pipeline)。同時,作為對本博文的補充,我們將會開源我們實現的這個端到端的音識別引擎(end-to-end speech recognition engine)的代碼。在其最初始形式中,系統使用雙向循環神經網絡(BiRNN)來訓練模型以直接從頻譜圖產生轉錄,而不必顯示地將音頻幀與轉錄對齊。與之取代的是一種隱式對齊,我們采用了 Graves 的連接體時間分類(CTC)算法(Connectionist Temporal Classification ,CTC)來實現。
雖然「純正」DNN 方法現在允許使用具有最先進性能的 LVCSR 系統進行訓練,但是顯式的解碼步驟 : 將模型輸出轉換為單詞的可感知序列,在評估期間仍然是十分關鍵的。解碼的技術是多種多樣的,我們通常同時使用加權有限狀態傳感器(weighted finite state transducers)和神經網絡語言模型(neural network language models)。如果想要了解相關的內容,那么需要一篇更加深入的文章來進行介紹,而本文主要限于 ASR 管道的訓練部分。如果需要的話,我們為讀者提供一些額外的參考知識來以填補空缺,希望能給讀者傳達構建端到端語音識別引擎的完整視圖。
簡單扼要的說,端到端語音識別流水線由三個主要部分組成:
1. 特征提取階段,其將原始音頻信號(例如,來自 wav 文件)作為輸入,并產生特征向量序列,其中有一個給定音頻輸入幀的特征向量。特征提取級的輸出的示例包括原始波形,頻譜圖和同樣流行的梅爾頻率倒頻譜系數(mel-frequency cepstral coefficients,MFCCs)的切片。
2. 將特征向量序列作為輸入并產生以特征向量輸入為條件的字符或音素序列的概率的聲學模型。
3. 采用兩個輸入(聲學模型的輸出以及語言模型)的解碼器并且在受到語言模型中編碼的語言規則約束的聲學模型生成的序列的情況下搜索最可能的轉錄。
處理數據
當構建端到端語音識別系統時,一套有效的加載數據的機制是十分關鍵的。我們將充分利用 Neon 1.7 版本中新添加的功能:Aeon,一個能夠支持圖像,音頻和視頻數據的高級數據加載工具。使用 Aeon 大大簡化了我們的工作,因為它允許我們直接使用原始音頻文件訓練聲學模型,而不必困擾于對數據顯示地預處理過程。此外,Aeon 能讓我們更加容易的指定我們希望在訓練期間使用的光譜特征的類型。
提取數據
通常,語音數據以一些標準音頻格式的原始音頻文件和一些包含相應轉錄的一系列文本文件的形式被分發。在許多情況下,轉錄文件將包含形如:<音頻文件的路徑>,<音頻文件中的語音的轉錄>的行的形式。這表示所列出的路徑指向包含轉錄的音頻文件。但是,在許多情況下,轉錄文件中列出的路徑不是絕對路徑,而是相對于某些假定目錄結構的路徑。為了處理不同數據打包情況,Aeon 要求用戶生成包含絕對路徑對的「清單文件」(manifest file),其中一個路徑指向音頻文件,另一個路徑指向相應的轉錄。我們將為讀者介紹 Neon 的演講示例(包括鏈接)和 Aeon 文檔以獲取更多詳細信息。
除了清單文件,Aeon 還要求用戶提供數據集中最長的話語的長度以及最長的轉錄的長度。這些長度可以在生成清單文件時被提取。比如可以使用當下流行的 SoX 程序去提取音頻文件的時長。
我們通過訓練由卷積(Conv)層,雙向復現(bi-directional recurrent (BiRNN))層和完全連接(FC)層(基本上遵循「Deep Speech 2」,如示意圖所示)組成的深層神經網絡來建立我們的聲學模型。
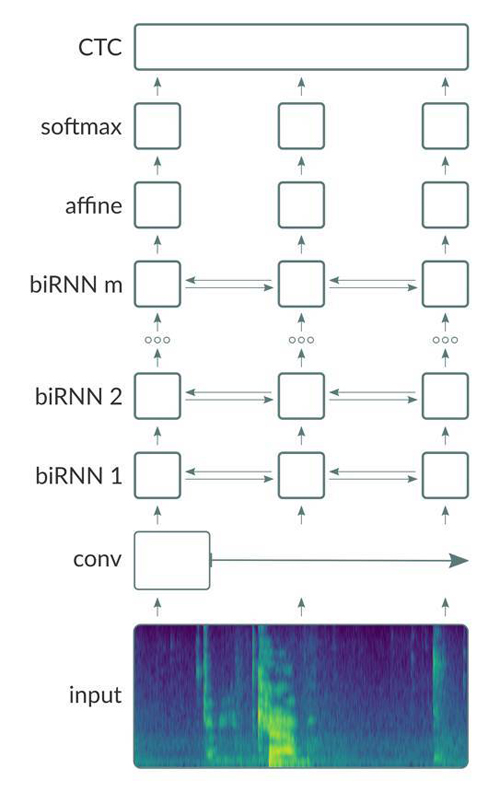
除了在輸出層使用 softmax 激活函數,我們在其它層都采用 ReLU 激活函數。
如圖所示,網絡采用光譜特征向量作為輸入。利用 Aeon dataloader,Neon 可以支持四種類型的輸入特性:原始波形,頻譜圖,mel 頻率譜系數(mel-frequency spectral coefficients (MFCSs))和 mel 頻率倒頻譜系數(mel-frequency cepstral coefficients (MFCCs))。MFSCs 和 MFCCs 是從頻譜圖中導出的,它們基本上將頻譜圖的每個列轉換為相對較小數量的與人耳的感知頻率范圍更相近的獨立系數。在我們的實驗中,我們還觀察到,在所有其他條件相等的情況下,用 mel 特征訓練的模型作為輸入執行效果略好于用頻譜圖訓練的模型。
光譜輸入被傳送到了 Conv 層。通常,可以考慮具有采用 1D 或 2D 卷積的多個 Conv 層的架構。我們將利用可以允許網絡在輸入的「更廣泛的上下文」(wider contexts)上操作的 strided convolution 層。Strided convolution 層還減少序列的總長度,這又顯著減小了存儲器的占用量和由網絡執行的計算量。這允許我們訓練甚至更深層次的模型,這種情況下我們不用增加太多的計算資源就可以讓性能得到較大的改進。
Conv 層的輸出被送到 BiRNN 層的棧中。每個 BiRNN 層由串聯運行的一對 RNN 組成,輸入序列在如圖所示的相反方向上呈現。
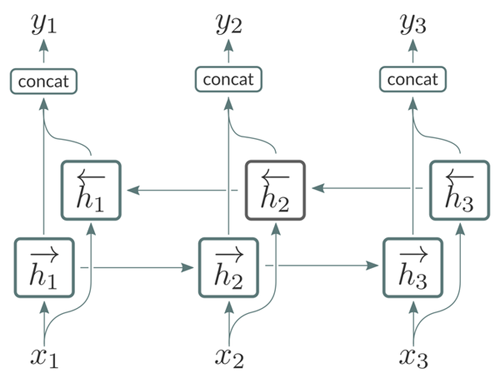
來自這對 RNN 的輸出將被串接起來如圖所示。BiRNN 層特別適合于處理語音信號,因為它們允許網絡訪問輸入序列 [1] 的每個給定點處的將來和過去的上下文。當訓練基于 CTC 的聲學模型時,我們發現使用「vanilla」RNN 而不是其門控變體(GRU 或 LSTM)是有好處的。這主要是因為后者具有顯著的計算開銷。如 [2] 所講,我們還對 BiRNN 層應用批次歸一化(batch normalization),以減少整體訓練時間,同時對總體字錯誤率(WER)測量的模型的精度幾乎沒有影響。
在每次迭代中,BiRNN 層的輸出先傳遞給一個全連接層,然后轉而將信息傳遞給 softmax 層。在 softmax 層中的每個單元都對應著字母表中描述目標詞匯表中的單個字符。例如,如果訓練數據來自英語語料庫,那么字母表通常將包括 A 到 Z 的所有字符和任何相關的標點符號,也包括用于分離文本中單詞的空格字符。基于 CTC 的模型通常還需要包括特殊的「空白」字符的字母表。這些空白字符促使模型可以可靠地預測連續的重復符號以及語音信號中的人為部分,例如,暫停,背景噪聲和其他「非語音」情況。
因此,對于給定話語的幀序列,該模型要為每幀生成一個在字母表上的概率分布。在數據訓練期間,softmax 的輸出會被傳輸到 CTC 代價函數(后文將詳細論述),其采用真實的文本來(i)對模型的預測值進行打分,以及(ii)生成用以量化模型預測值的準確性的誤差信號。總體目標是訓練模型來提升在真實場景下的預測表現。
訓練數據
根據經驗,我們發現使用隨機梯度下降法和動量與梯度限制配對法會訓練出最優性能的模型。更深層的網絡(7 層或更多)在大體上也有同樣的效果。
我們采用 Sutskever 等人實現的 Nesterov 的加速梯度下降法去訓練模型。大多數模型的超參數,例如:網絡的深度,給定層中的單元數量,學習速率,退火速率,動量等等,是基于現有的開發數據集根據經驗選擇出來的。我們使用「Xavier」初始化方法來為我們的模型中的每一層進行初始化,雖然我們還沒有系統地調查過是否通過使用其他可取代的初始化方案,來比較實驗的結果是否有所優化。
我們所有的模型都使用 CTC 損失標準進行訓練,對 CTC 計算法內部過程的詳細解釋超出了本博客的范圍。我們將在這里提出一個簡要概述,為了獲得更深的理解,建議讀者去閱讀 Graves 的論文。
CTC 計算法以「折疊」函數的動作為核心,該函數采用一系列字符作為輸入,并通過首先去除輸入字符串中的所有重復字符,然后刪除所有「空白」符號來產生輸出序列。比如說,如果我們使用「_」表示空白符號,然后
![]()
給定一個長度為 T 的話語和其對應的「ground truth」的轉錄,CTC 算法會構建「轉置」的折疊函數,其定義為所有可能的長度為 T 的,折疊到「ground truth」轉錄上的字符序列。
任意序列出現在該「轉置」集合中的概率是可以直接從神經網絡中的 softmax 輸出計算出來的。然后將 CTC 成本定義為序列的概率和的對數函數,它存在于「轉置」集合中。該函數對于 softmax 的輸出是可區分的,這是反向傳播中所要計算的誤差梯度。
以一個簡單示例來做說明,假設輸入話語有三個幀,并且相應的轉錄本是單詞「OX」。同樣,使用「_」表示空白符號,折疊為 OX 的三字符序列集包含 _OX,O_X,OOX,OXX 和 OX_。CTC 算法設置
![]()
P(abc) = p(a,1)p(b,2)p(c,3),其中 p(u,t) 表示單元「u」, 時間 t(幀)時 softmax 模型的輸出值。因此 CTC 算法需要枚舉固定長度的所有序列,其折疊到給定的目標序列。當處理非常長的序列時,通過前向 -后向算法,枚舉組合可以被有效的執行,這就非常接近采用 HMMs 方法的處理問題的思想。
評價
一旦模型訓練完成,我們可以通過預測一段系統從未聽過的語音來評估它的性能。由于模型生成概率向量序列作為輸出,因此我們需要構建一個解碼器(decoder)來將模型的輸出轉換成單詞序列(word sequence)。
解碼器的工作是搜索模型的輸出并生成最有可能的序列作為轉錄(tranion)。最簡單的方法是計算
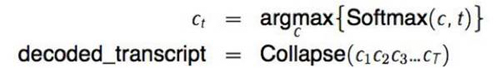
其中 Collapse(...)是上面定義的映射(mapping)。
盡管用字符序列訓練模型,我們的模型仍然能夠學習隱式語言模型(implicit language model),并已經能夠非常熟練地用語音拼寫出詞語(見表 1)。通常在字符級別用 Levenshtein 距離計算的字符錯誤率(CERs)來測量模型的拼寫性能。我們已經觀察到,模型預測的很多誤差是沒有在訓練集中出現過的單詞。因此,可以合理地預計,隨著訓練集規模的增加,總的 CER 數值將繼續改進。這個預期在深度語音 2(Deep Speech 2)的結果中得到證實,它的訓練集包括超過 12000 小時的語音數據。

表 1:模型對華爾街日報評估數據集的預測樣本。我們故意選擇了模型難以判斷的例子。如圖所示,加入語言模型約束后基本上消除了在沒有語言模型的情況下產生的所有「拼寫錯誤」。
雖然我們的模型顯示了非常好的 CER 結果,模型的讀出單詞拼寫(spell out words phonetically)的傾向導致了相對較高的單詞錯誤率。我們可以通過加入從外部詞典和語言模型得到的解碼器來約束模型,以此改進模型的性能(WER)。根據 [3,4],我們發現使用加權有限狀態傳感器(WFST)是一個特別有效的完成這項任務的方法。我們觀察到 WER 數值在 WSJ 和 Librispeech 數據集上相對提高了 25%。
表 2 列出了使用華爾街日報(WSJ)語料庫訓練的各種端到端語音識別系統。為了測試「蘋果」(公司)與「蘋果」(水果)的識別結果,我們選擇僅用 WSJ 數據集訓練和評估的系統的公開數據進行系統間的比較。然而,結果顯示在同一數據集上訓練和評估的混合 DNN-HMM 系統比使用純深神經網絡架構的系統表現更好 [6]。另一方面,結果顯示當訓練集的數據量更大時,純深度神經網絡架構能夠實現與混合 DNN-HMM 系統相同的性能 [引用 DS2]。
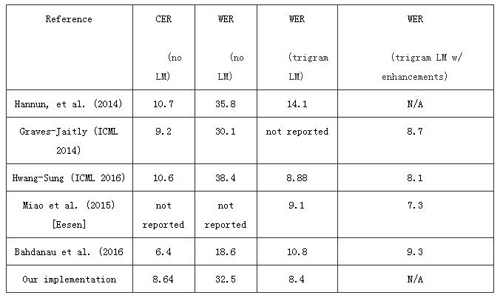
表 2:我們只使用華爾街日報數據集來訓練和評估各種端到端的語音識別系統的性能。CER(character error rate)指的是比較由模型得到的字符序列與實際轉錄的字符序列的字符錯誤率。LM 指的是語言模型。最后一列指的是使用附加技術(如重新評分、模型聚合等)解碼的例子。
未來的工作
將 CTC 目標函數嵌入神經網絡模型的語音識別模型,讓我們初次看到了這種 純正 DNN 模型的能力。不過,最近,所謂的基于注意機制(attention mechanism)增強的編-解碼器(encoder-decoder)的 RNN 模型正在興起,并作為用一種使用 CTC 標準 [4,5] 訓練的 RNN 模型的可行的替代方案。基于注意機制的編-解碼器模型與基于 CTC 標準的模型,都是被訓練用于將聲音輸入序列(acoustic input)映射(map)到字符/音位(character/phoneme)序列上。正如上面所討論的,基于 CTC 標準的模型被訓練用于預測語音輸入的每個幀對應的字符,并在逐幀的預測與目標序列序列之間搜索可能的匹配。與之相反,基于注意機制的編-解碼器模型會在預測輸出序列之前首先讀取整個輸入序列。
該方法概念上的優點是,我們不必假設輸出序列中的預測字符是相互獨立的。CTC 的算法基于這個假設,而該假設是毫無根據的——因為字符序列出現的順序是與比之之前較早出現的字符序列是高度條件相關的。最近的研究工作顯示,LVCSR 系統的基于注意機制的編-解碼器模型相對于基于 CTC 標準的模型在字符出錯率上有明顯的改善 [4]。在我們這兩種方法被整入語言模型之前進行評估,得出的評斷是正確的,這也支持了基于注意機制的模型是比基于 CTC 標準的模型更好的聲學模型的論斷。然而,值得指出的是,當語言模型被用來確定單詞錯誤率時,這種性能上的差異就消失了。
我們正致力于建立 ASR 系統的基于注意機制的編-解碼器網絡的 Neon,竭誠歡迎各類參與。代碼可以參見https://github.com/NervanaSystems/deepspeech.git.