













Python多進程并行編程實踐: mpi4py 的使用
前言
在高性能計算的項目中我們通常都會使用效率更高的編譯型的語言例如C、C++、Fortran等,但是由于Python的靈活性和易用性使得它在發展和驗證算法方面備受人們的青睞于是在高性能計算領域也經常能看到Python的身影了。本文簡單介紹在Python環境下使用MPI接口在集群上進行多進程并行計算的方法。
MPI(Message Passing Interface)
這里我先對MPI進行一下簡單的介紹,MPI的全稱是Message Passing Interface,即消息傳遞接口。
- 它并不是一門語言,而是一個庫,我們可以用Fortran、C、C++結合MPI提供的接口來將串行的程序進行并行化處理,也可以認為Fortran+MPI或者C+MPI是一種再原來串行語言的基礎上擴展出來的并行語言。
- 它是一種標準而不是特定的實現,具體的可以有很多不同的實現,例如MPICH、OpenMPI等。
- 它是一種消息傳遞編程模型,顧名思義,它就是專門服務于進程間通信的。
MPI的工作方式很好理解,我們可以同時啟動一組進程,在同一個通信域中不同的進程都有不同的編號,程序員可以利用MPI提供的接口來給不同編號的進程分配不同的任務和幫助進程相互交流最終完成同一個任務。就好比包工頭給工人們編上了工號然后指定一個方案來給不同編號的工人分配任務并讓工人相互溝通完成任務。
Python中的并行
由于CPython中的GIL的存在我們可以暫時不奢望能在CPython中使用多線程利用多核資源進行并行計算了,因此我們在Python中可以利用多進程的方式充分利用多核資源。
Python中我們可以使用很多方式進行多進程編程,例如os.fork()來創建進程或者通過multiprocessing模塊來更方便的創建進程和進程池等。在上一篇《Python多進程并行編程實踐-multiprocessing模塊》中我們使用進程池來方便的管理Python進程并且通過multiprocessing模塊中的Manager管理分布式進程實現了計算的多機分布式計算。
與多線程的共享式內存不同,由于各個進程都是相互獨立的,因此進程間通信再多進程中扮演這非常重要的角色,Python中我們可以使用multiprocessing模塊中的pipe、queue、Array、Value等等工具來實現進程間通訊和數據共享,但是在編寫起來仍然具有很大的不靈活性。而這一方面正是MPI所擅長的領域,因此如果能夠在Python中調用MPI的接口那真是太***了不是么。
MPI與mpi4py
mpi4py是一個構建在MPI之上的Python庫,主要使用Cython編寫。mpi4py使得Python的數據結構可以方便的在多進程中傳遞。
mpi4py是一個很強大的庫,它實現了很多MPI標準中的接口,包括點對點通信,組內集合通信、非阻塞通信、重復非阻塞通信、組間通信等,基本上我能想到用到的MPI接口mpi4py中都有相應的實現。不僅是Python對象,mpi4py對numpy也有很好的支持并且傳遞效率很高。同時它還提供了SWIG和F2PY的接口能夠讓我們將自己的Fortran或者C/C++程序在封裝成Python后仍然能夠使用mpi4py的對象和接口來進行并行處理。可見mpi4py的作者的功力的確是非常了得。
mpi4py
這里我開始對在Python環境中使用mpi4py的接口進行并行編程進行介紹。
MPI環境管理
mpi4py提供了相應的接口Init()和Finalize()來初始化和結束mpi環境。但是mpi4py通過在__init__.py中寫入了初始化的操作,因此在我們from mpi4py import MPI的時候就已經自動初始化mpi環境。
MPI_Finalize()被注冊到了Python的C接口Py_AtExit(),這樣在Python進程結束時候就會自動調用MPI_Finalize(), 因此不再需要我們顯式的去掉用Finalize()。
通信域(Communicator)
mpi4py直接提供了相應的通信域的Python類,其中Comm是通信域的基類,Intracomm和Intercomm是其派生類,這根MPI的C++實現中是相同的。
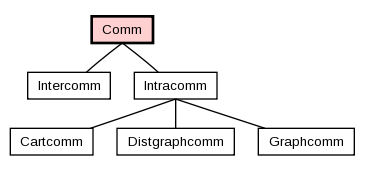
同時它也提供了兩個預定義的通信域對象:
- 包含所有進程的COMM_WORLD
- 只包含調用進程本身的COMM_SELF
- In [1]: from mpi4py import MPI
- In [2]: MPI.COMM_SELF
- Out[2]: <mpi4py.MPI.Intracomm at 0x7f2fa2fd59d0>
- In [3]: MPI.COMM_WORLD
- Out[3]: <mpi4py.MPI.Intracomm at 0x7f2fa2fd59f0>
通信域對象則提供了與通信域相關的接口,例如獲取當前進程號、獲取通信域內的進程數、獲取進程組、對進程組進行集合運算、分割合并等等。
- In [4]: comm = MPI.COMM_WORLD
- In [5]: comm.Get_rank()
- Out[5]: 0
- In [6]: comm.Get_size()
- Out[6]: 1
- In [7]: comm.Get_group()
- Out[7]: <mpi4py.MPI.Group at 0x7f2fa40fec30>
- In [9]: comm.Split(0, 0)
- Out[9]: <mpi4py.MPI.Intracomm at 0x7f2fa2fd5bd0>
關于通信域與進程組的操作這里就不細講了,可以參考Introduction to Groups and Communicators
點對點通信
mpi4py提供了點對點通信的接口使得多個進程間能夠互相傳遞Python的內置對象(基于pickle序列化),同時也提供了直接的數組傳遞(numpy數組,接近C語言的效率)。
如果我們需要傳遞通用的Python對象,則需要使用通信域對象的方法中小寫的接口,例如send(),recv(),isend()等。
如果需要直接傳遞數據對象,則需要調用大寫的接口,例如Send(),Recv(),Isend()等,這與C++接口中的拼寫是一樣的。
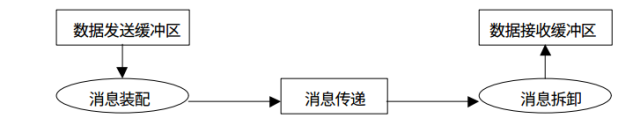
MPI中的點到點通信有很多中,其中包括標準通信,緩存通信,同步通信和就緒通信,同時上面這些通信又有非阻塞的異步版本等等。這些在mpi4py中都有相應的Python版本的接口來讓我們更靈活的處理進程間通信。這里我只用標準通信的阻塞和非阻塞版本來做個舉例:
阻塞標準通信
這里我嘗試使用mpi4py的接口在兩個進程中傳遞Python list對象。
- from mpi4py import MPI
- import numpy as np
- comm = MPI.COMM_WORLD
- rank = comm.Get_rank()
- size = comm.Get_size()
- if rank == 0:
- data = range(10)
- comm.send(data, dest=1, tag=11)
- print("process {} send {}...".format(rank, data))
- else:
- data = comm.recv(source=0, tag=11)
- print("process {} recv {}...".format(rank, data))
執行效果:
- zjshao@vaio:~/temp_codes/mpipy$ mpiexec -np 2 python temp.py
- process 0 send [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]...
- process 1 recv [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]...
非阻塞標準通信
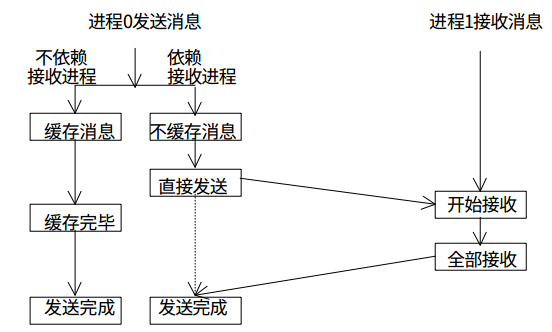
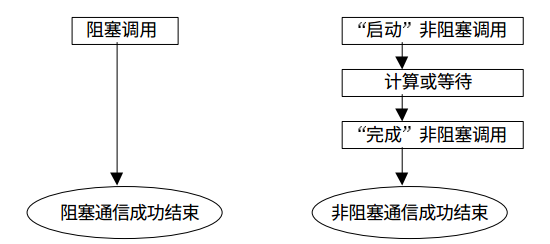
所有的阻塞通信mpi都提供了一個非阻塞的版本,類似與我們編寫異步程序不阻塞在耗時的IO上是一樣的,MPI的非阻塞通信也不會阻塞消息的傳遞過程中,這樣能夠充分利用處理器資源提升整個程序的效率。
來張圖看看阻塞通信與非阻塞通信的對比:
非阻塞通信的消息發送和接受:
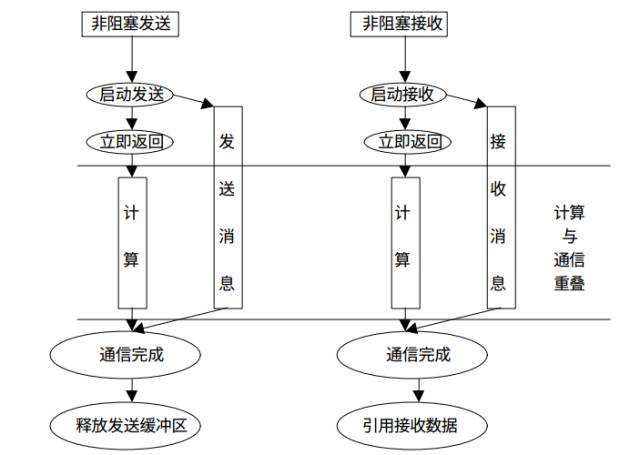
同樣的,我們也可以寫一個上面例子的非阻塞版本。
- from mpi4py import MPI
- import numpy as np
- comm = MPI.COMM_WORLD
- rank = comm.Get_rank()
- size = comm.Get_size()
- if rank == 0:
- data = range(10)
- comm.isend(data, dest=1, tag=11)
- print("process {} immediate send {}...".format(rank, data))
- else:
- data = comm.recv(source=0, tag=11)
- print("process {} recv {}...".format(rank, data))
執行結果,注意非阻塞發送也可以用阻塞接收來接收消息:
- zjshao@vaio:~/temp_codes/mpipy$ mpiexec -np 2 python temp.py
- process 0 immediate send [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]...
- process 1 recv [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]...
支持Numpy數組
mpi4py的一個很好的特點就是他對Numpy數組有很好的支持,我們可以通過其提供的接口來直接傳遞數據對象,這種方式具有很高的效率,基本上和C/Fortran直接調用MPI接口差不多(方式和效果)
例如我想傳遞長度為10的int數組,MPI的C++接口是:
- void Comm::Send(const void * buf, int count, const Datatype & datatype, int dest, int tag) const
在mpi4py的接口中也及其類似, Comm.Send()中需要接收一個Python list作為參數,其中包含所傳數據的地址,長度和類型。
來個阻塞標準通信的例子:
- from mpi4py import MPI
- import numpy as np
- comm = MPI.COMM_WORLD
- rank = comm.Get_rank()
- size = comm.Get_size()
- if rank == 0:
- data = np.arange(10, dtype='i')
- comm.Send([data, MPI.INT], dest=1, tag=11)
- print("process {} Send buffer-like array {}...".format(rank, data))
- else:
- data = np.empty(10, dtype='i')
- comm.Recv([data, MPI.INT], source=0, tag=11)
- print("process {} recv buffer-like array {}...".format(rank, data))
執行效果:
- zjshao@vaio:~/temp_codes/mpipy$ /usr/bin/mpiexec -np 2 python temp.py
- process 0 Send buffer-like array [0 1 2 3 4 5 6 7 8 9]...
- process 1 recv buffer-like array [0 1 2 3 4 5 6 7 8 9]...
組通信
MPI組通信和點到點通信的一個重要區別就是,在某個進程組內所有的進程同時參加通信,mpi4py提供了方便的接口讓我們完成Python中的組內集合通信,方便編程同時提高程序的可讀性和可移植性。
下面就幾個常用的集合通信來小試牛刀吧。
廣播
廣播操作是典型的一對多通信,將跟進程的數據復制到同組內其他所有進程中。
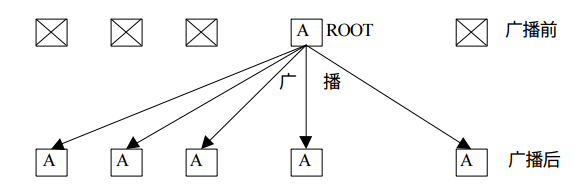
在Python中我想將一個列表廣播到其他進程中:
- from mpi4py import MPI
- comm = MPI.COMM_WORLD
- rank = comm.Get_rank()
- size = comm.Get_size()
- if rank == 0:
- data = range(10)
- print("process {} bcast data {} to other processes".format(rank, data))
- else:
- data = None
- data = comm.bcast(data, root=0)
- print("process {} recv data {}...".format(rank, data))
執行結果:
- zjshao@vaio:~/temp_codes/mpipy$ /usr/bin/mpiexec -np 5 python temp.py
- process 0 bcast data [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] to other processes
- process 0 recv data [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]...
- process 1 recv data [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]...
- process 3 recv data [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]...
- process 2 recv data [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]...
- process 4 recv data [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]...
發散
與廣播不同,發散可以向不同的進程發送不同的數據,而不是完全復制。
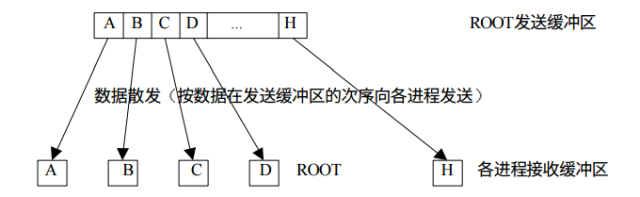
例如我想將0-9發送到不同的進程中:
- from mpi4py import MPI
- import numpy as np
- comm = MPI.COMM_WORLD
- rank = comm.Get_rank()
- size = comm.Get_size()
- recv_data = None
- if rank == 0:
- send_data = range(10)
- print("process {} scatter data {} to other processes".format(rank, send_data))
- else:
- send_data = None
- recv_data = comm.scatter(send_data, root=0)
- print("process {} recv data {}...".format(rank, recv_data))
發散結果:
- zjshao@vaio:~/temp_codes/mpipy$ /usr/bin/mpiexec -np 10 python temp.py
- process 0 scatter data [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] to other processes
- process 0 recv data 0...
- process 3 recv data 3...
- process 5 recv data 5...
- process 8 recv data 8...
- process 2 recv data 2...
- process 7 recv data 7...
- process 4 recv data 4...
- process 1 recv data 1...
- process 9 recv data 9...
- process 6 recv data 6...
收集
收集過程是發散過程的逆過程,每個進程將發送緩沖區的消息發送給根進程,根進程根據發送進程的進程號將各自的消息存放到自己的消息緩沖區中。
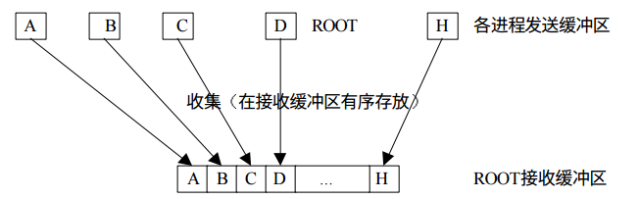
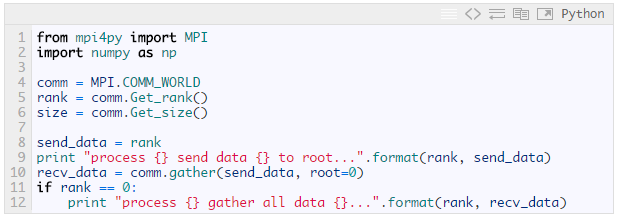
收集結果:
- zjshao@vaio:~/temp_codes/mpipy$ /usr/bin/mpiexec -np 5 python temp.py
- process 2 send data 2 to root...
- process 3 send data 3 to root...
- process 0 send data 0 to root...
- process 4 send data 4 to root...
- process 1 send data 1 to root...
- process 0 gather all data [0, 1, 2, 3, 4]...
其他的組內通信還有歸約操作等等由于篇幅限制就不多講了,有興趣的可以去看看MPI的官方文檔和相應的教材。
mpi4py并行編程實踐
這里我就上篇《Python 多進程并行編程實踐: multiprocessing 模塊》中的二重循環繪制map的例子來使用mpi4py進行并行加速處理。
我打算同時啟動10個進程來將每個0軸需要計算和繪制的數據發送到不同的進程進行并行計算。
因此我需要將pO2s數組發散到10個進程中:
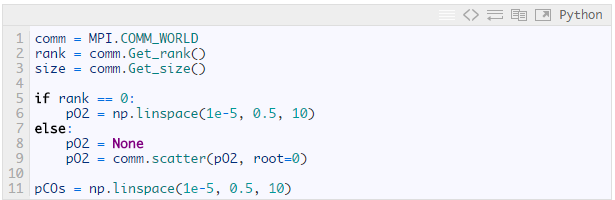
之后我需要在每個進程中根據接受到的pO2s的數據再進行一次pCOs循環來進行計算。
最終將每個進程計算的結果(TOF)進行收集操作:
- comm.gather(tofs_1d, root=0)
由于代碼都是涉及的專業相關的東西我就不全列出來了,將mpi4py改過的并行版本放到10個進程中執行可見:


效率提升了10倍左右。
總結
本文簡單介紹了mpi4py的接口在python中進行多進程編程的方法,MPI的接口非常龐大,相應的mpi4py也非常龐大,mpi4py還有實現了相應的SWIG和F2PY的封裝文件和類型映射,能夠幫助我們將Python同真正的C/C++以及Fortran程序在消息傳遞上實現統一。有興趣的同學可以進一步研究一下,歡迎交流。
參考
- MPI for Python 2.0.0 documentation
- MPI Tutorial
- A Python Introduction to Parallel Programming with MPI
- 《高性能計算并行編程技術-MPI并行程序設計》
- 《MPI并行程序設計實例教程》





















