【深度學(xué)習(xí)系列】卷積神經(jīng)網(wǎng)絡(luò)CNN原理詳解(一)——基本原理
上篇文章我們給出了用paddlepaddle來(lái)做手寫(xiě)數(shù)字識(shí)別的示例,并對(duì)網(wǎng)絡(luò)結(jié)構(gòu)進(jìn)行到了調(diào)整,提高了識(shí)別的精度。有的同學(xué)表示不是很理解原理,為什么傳統(tǒng)的機(jī)器學(xué)習(xí)算法,簡(jiǎn)單的神經(jīng)網(wǎng)絡(luò)(如多層感知機(jī))都可以識(shí)別手寫(xiě)數(shù)字,我們要采用卷積神經(jīng)網(wǎng)絡(luò)CNN來(lái)進(jìn)行別呢?CNN到底是怎么識(shí)別的?用CNN有哪些優(yōu)勢(shì)呢?我們下面就來(lái)簡(jiǎn)單分析一下。在講CNN之前,為避免完全零基礎(chǔ)的人看不懂后面的講解,我們先簡(jiǎn)單回顧一下傳統(tǒng)的神經(jīng)網(wǎng)絡(luò)的基本知識(shí)。
神經(jīng)網(wǎng)絡(luò)的預(yù)備知識(shí)
為什么要用神經(jīng)網(wǎng)絡(luò)?
- 特征提取的高效性。
大家可能會(huì)疑惑,對(duì)于同一個(gè)分類(lèi)任務(wù),我們可以用機(jī)器學(xué)習(xí)的算法來(lái)做,為什么要用神經(jīng)網(wǎng)絡(luò)呢?大家回顧一下,一個(gè)分類(lèi)任務(wù),我們?cè)谟脵C(jī)器學(xué)習(xí)算法來(lái)做時(shí),首先要明確feature和label,然后把這個(gè)數(shù)據(jù)"灌"到算法里去訓(xùn)練,最后保存模型,再來(lái)預(yù)測(cè)分類(lèi)的準(zhǔn)確性。但是這就有個(gè)問(wèn)題,即我們需要實(shí)現(xiàn)確定好特征,每一個(gè)特征即為一個(gè)維度,特征數(shù)目過(guò)少,我們可能無(wú)法精確的分類(lèi)出來(lái),即我們所說(shuō)的欠擬合,如果特征數(shù)目過(guò)多,可能會(huì)導(dǎo)致我們?cè)诜诸?lèi)過(guò)程中過(guò)于注重某個(gè)特征導(dǎo)致分類(lèi)錯(cuò)誤,即過(guò)擬合。
舉個(gè)簡(jiǎn)單的例子,現(xiàn)在有一堆數(shù)據(jù)集,讓我們分類(lèi)出西瓜和冬瓜,如果只有兩個(gè)特征:形狀和顏色,可能沒(méi)法分區(qū)來(lái);如果特征的維度有:形狀、顏色、瓜瓤顏色、瓜皮的花紋等等,可能很容易分類(lèi)出來(lái);如果我們的特征是:形狀、顏色、瓜瓤顏色、瓜皮花紋、瓜蒂、瓜籽的數(shù)量,瓜籽的顏色、瓜籽的大小、瓜籽的分布情況、瓜籽的XXX等等,很有可能會(huì)過(guò)擬合,譬如有的冬瓜的瓜籽數(shù)量和西瓜的類(lèi)似,模型訓(xùn)練后這類(lèi)特征的權(quán)重較高,就很容易分錯(cuò)。這就導(dǎo)致我們?cè)谔卣鞴こ躺闲枰ê芏鄷r(shí)間和精力,才能使模型訓(xùn)練得到一個(gè)好的效果。然而神經(jīng)網(wǎng)絡(luò)的出現(xiàn)使我們不需要做大量的特征工程,譬如提前設(shè)計(jì)好特征的內(nèi)容或者說(shuō)特征的數(shù)量等等,我們可以直接把數(shù)據(jù)灌進(jìn)去,讓它自己訓(xùn)練,自我“修正”,即可得到一個(gè)較好的效果。
- 數(shù)據(jù)格式的簡(jiǎn)易性
在一個(gè)傳統(tǒng)的機(jī)器學(xué)習(xí)分類(lèi)問(wèn)題中,我們“灌”進(jìn)去的數(shù)據(jù)是不能直接灌進(jìn)去的,需要對(duì)數(shù)據(jù)進(jìn)行一些處理,譬如量綱的歸一化,格式的轉(zhuǎn)化等等,不過(guò)在神經(jīng)網(wǎng)絡(luò)里我們不需要額外的對(duì)數(shù)據(jù)做過(guò)多的處理,具體原因可以看后面的詳細(xì)推導(dǎo)。
- 參數(shù)數(shù)目的少量性
在面對(duì)一個(gè)分類(lèi)問(wèn)題時(shí),如果用SVM來(lái)做,我們需要調(diào)整的參數(shù)需要調(diào)整核函數(shù),懲罰因子,松弛變量等等,不同的參數(shù)組合對(duì)于模型的效果也不一樣,想要迅速而又準(zhǔn)確的調(diào)到最適合模型的參數(shù)需要對(duì)背后理論知識(shí)的深入了解(當(dāng)然,如果你說(shuō)全部都試一遍也是可以的,但是花的時(shí)間可能會(huì)更多),對(duì)于一個(gè)基本的三層神經(jīng)網(wǎng)絡(luò)來(lái)說(shuō)(輸入-隱含-輸出),我們只需要初始化時(shí)給每一個(gè)神經(jīng)元上隨機(jī)的賦予一個(gè)權(quán)重w和偏置項(xiàng)b,在訓(xùn)練過(guò)程中,這兩個(gè)參數(shù)會(huì)不斷的修正,調(diào)整到最優(yōu)質(zhì),使模型的誤差最小。所以從這個(gè)角度來(lái)看,我們對(duì)于調(diào)參的背后理論知識(shí)并不需要過(guò)于精通(只不過(guò)做多了之后可能會(huì)有一些經(jīng)驗(yàn),在初始值時(shí)賦予的值更科學(xué),收斂的更快罷了)
有哪些應(yīng)用?
應(yīng)用非常廣,不過(guò)大家注意一點(diǎn),我們現(xiàn)在所說(shuō)的神經(jīng)網(wǎng)絡(luò),并不能稱(chēng)之為深度學(xué)習(xí),神經(jīng)網(wǎng)絡(luò)很早就出現(xiàn)了,只不過(guò)現(xiàn)在因?yàn)椴粩嗟募由盍司W(wǎng)絡(luò)層,復(fù)雜化了網(wǎng)絡(luò)結(jié)構(gòu),才成為深度學(xué)習(xí),并在圖像識(shí)別、圖像檢測(cè)、語(yǔ)音識(shí)別等等方面取得了不錯(cuò)的效果。
基本網(wǎng)絡(luò)結(jié)構(gòu)
一個(gè)神經(jīng)網(wǎng)絡(luò)最簡(jiǎn)單的結(jié)構(gòu)包括輸入層、隱含層和輸出層,每一層網(wǎng)絡(luò)有多個(gè)神經(jīng)元,上一層的神經(jīng)元通過(guò)激活函數(shù)映射到下一層神經(jīng)元,每個(gè)神經(jīng)元之間有相對(duì)應(yīng)的權(quán)值,輸出即為我們的分類(lèi)類(lèi)別。
詳細(xì)數(shù)學(xué)推導(dǎo)
去年中旬我參考吳恩達(dá)的UFLDL和mattmazur的博客寫(xiě)了篇文章詳細(xì)講解了一個(gè)最簡(jiǎn)單的神經(jīng)網(wǎng)絡(luò)從前向傳播到反向傳播的直觀推導(dǎo),大家可以先看看這篇文章--一文弄懂神經(jīng)網(wǎng)絡(luò)中的反向傳播法--BackPropagation。
優(yōu)缺點(diǎn)
前面說(shuō)了很多優(yōu)點(diǎn),這里就不多說(shuō)了,簡(jiǎn)單說(shuō)說(shuō)缺點(diǎn)吧。我們?cè)囅胍幌氯绻由钗覀兊木W(wǎng)絡(luò)層,每一個(gè)網(wǎng)絡(luò)層增加神經(jīng)元的數(shù)量,那么參數(shù)的個(gè)數(shù)將是M*N(m為網(wǎng)絡(luò)層數(shù),N為每層神經(jīng)元個(gè)數(shù)),所需的參數(shù)會(huì)非常多,參數(shù)一多,模型就復(fù)雜了,越是復(fù)雜的模型就越不好調(diào)參,也越容易過(guò)擬合。此外我們從神經(jīng)網(wǎng)絡(luò)的反向傳播的過(guò)程來(lái)看,梯度在反向傳播時(shí),不斷的迭代會(huì)導(dǎo)致梯度越來(lái)越小,即梯度消失的情況,梯度一旦趨于0,那么權(quán)值就無(wú)法更新,這個(gè)神經(jīng)元相當(dāng)于是不起作用了,也就很難導(dǎo)致收斂。尤其是在圖像領(lǐng)域,用最基本的神經(jīng)網(wǎng)絡(luò),是不太合適的。后面我們會(huì)詳細(xì)講講為啥不合適。
為什么要用卷積神經(jīng)網(wǎng)絡(luò)?
傳統(tǒng)神經(jīng)網(wǎng)絡(luò)的劣勢(shì)
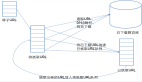
前面說(shuō)到在圖像領(lǐng)域,用傳統(tǒng)的神經(jīng)網(wǎng)絡(luò)并不合適。我們知道,圖像是由一個(gè)個(gè)像素點(diǎn)構(gòu)成,每個(gè)像素點(diǎn)有三個(gè)通道,分別代表RGB顏色,那么,如果一個(gè)圖像的尺寸是(28,28,1),即代表這個(gè)圖像的是一個(gè)長(zhǎng)寬均為28,channel為1的圖像(channel也叫depth,此處1代表灰色圖像)。如果使用全連接的網(wǎng)絡(luò)結(jié)構(gòu),即,網(wǎng)絡(luò)中的神經(jīng)與與相鄰層上的每個(gè)神經(jīng)元均連接,那就意味著我們的網(wǎng)絡(luò)有28 * 28 =784個(gè)神經(jīng)元,hidden層采用了15個(gè)神經(jīng)元,那么簡(jiǎn)單計(jì)算一下,我們需要的參數(shù)個(gè)數(shù)(w和b)就有:784*15*10+15+10=117625個(gè),這個(gè)參數(shù)太多了,隨便進(jìn)行一次反向傳播計(jì)算量都是巨大的,從計(jì)算資源和調(diào)參的角度都不建議用傳統(tǒng)的神經(jīng)網(wǎng)絡(luò)。(評(píng)論中有同學(xué)對(duì)這個(gè)參數(shù)計(jì)算不太理解,我簡(jiǎn)單說(shuō)一下:圖片是由像素點(diǎn)組成的,用矩陣表示的,28*28的矩陣,肯定是沒(méi)法直接放到神經(jīng)元里的,我們得把它“拍平”,變成一個(gè)28*28=784 的一列向量,這一列向量和隱含層的15個(gè)神經(jīng)元連接,就有784*15=11760個(gè)權(quán)重w,隱含層和最后的輸出層的10個(gè)神經(jīng)元連接,就有11760*10=117600個(gè)權(quán)重w,再加上隱含層的偏置項(xiàng)15個(gè)和輸出層的偏置項(xiàng)10個(gè),就是:117625個(gè)參數(shù)了)
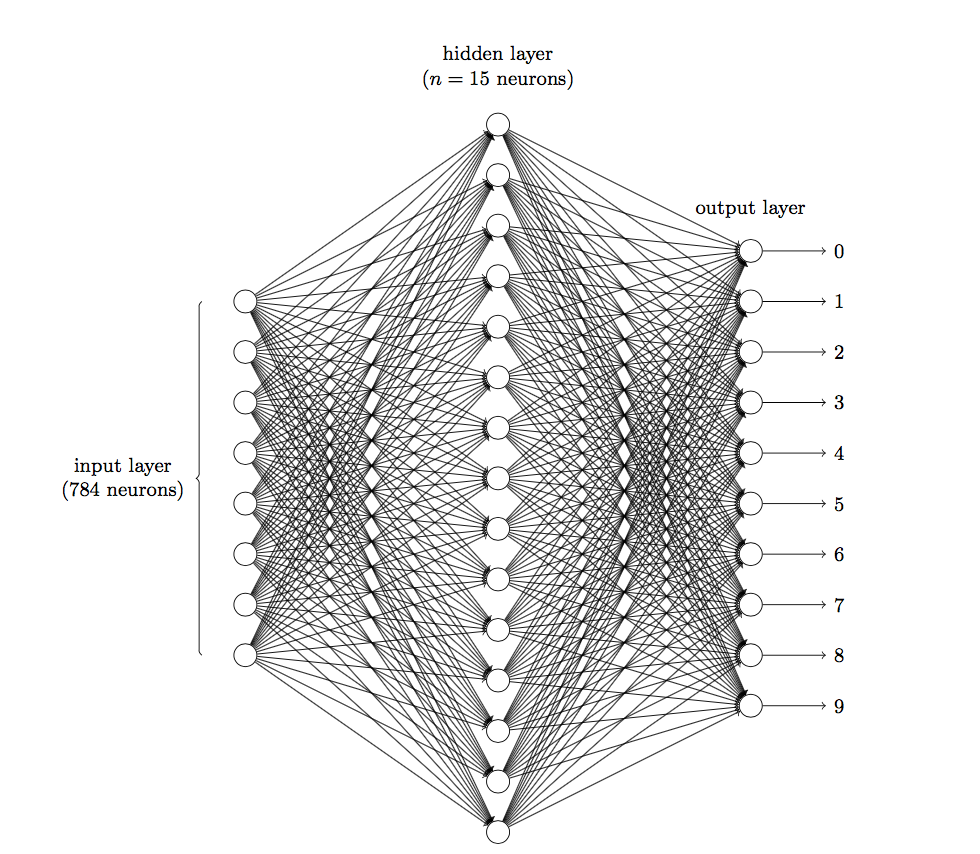
圖1 三層神經(jīng)網(wǎng)絡(luò)識(shí)別手寫(xiě)數(shù)字
卷積神經(jīng)網(wǎng)絡(luò)是什么?
三個(gè)基本層
- 卷積層(Convolutional Layer)
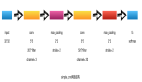
上文提到我們用傳統(tǒng)的三層神經(jīng)網(wǎng)絡(luò)需要大量的參數(shù),原因在于每個(gè)神經(jīng)元都和相鄰層的神經(jīng)元相連接,但是思考一下,這種連接方式是必須的嗎?全連接層的方式對(duì)于圖像數(shù)據(jù)來(lái)說(shuō)似乎顯得不這么友好,因?yàn)閳D像本身具有“二維空間特征”,通俗點(diǎn)說(shuō)就是局部特性。譬如我們看一張貓的圖片,可能看到貓的眼鏡或者嘴巴就知道這是張貓片,而不需要說(shuō)每個(gè)部分都看完了才知道,啊,原來(lái)這個(gè)是貓啊。所以如果我們可以用某種方式對(duì)一張圖片的某個(gè)典型特征識(shí)別,那么這張圖片的類(lèi)別也就知道了。這個(gè)時(shí)候就產(chǎn)生了卷積的概念。舉個(gè)例子,現(xiàn)在有一個(gè)4*4的圖像,我們?cè)O(shè)計(jì)兩個(gè)卷積核,看看運(yùn)用卷積核后圖片會(huì)變成什么樣。
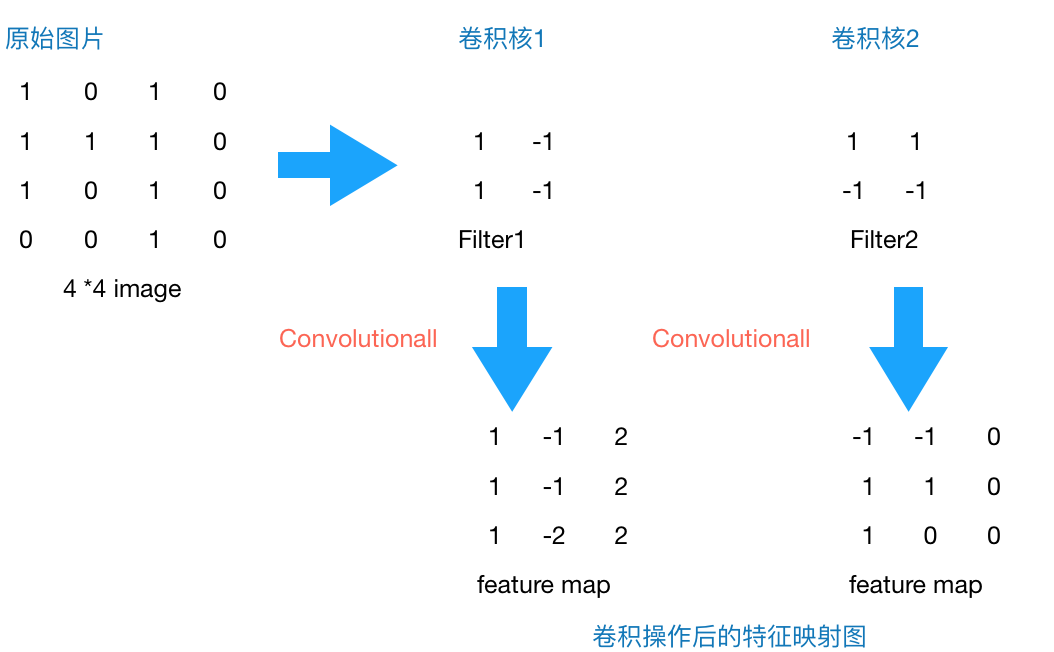
圖2 4*4 image與兩個(gè)2*2的卷積核操作結(jié)果
由上圖可以看到,原始圖片是一張灰度圖片,每個(gè)位置表示的是像素值,0表示白色,1表示黑色,(0,1)區(qū)間的數(shù)值表示灰色。對(duì)于這個(gè)4*4的圖像,我們采用兩個(gè)2*2的卷積核來(lái)計(jì)算。設(shè)定步長(zhǎng)為1,即每次以2*2的固定窗口往右滑動(dòng)一個(gè)單位。以第一個(gè)卷積核filter1為例,計(jì)算過(guò)程如下:
1 feature_map1(1,1) = 1*1 + 0*(-1) + 1*1 + 1*(-1) = 1 2 feature_map1(1,2) = 0*1 + 1*(-1) + 1*1 + 1*(-1) = -1 3 ``` 4 feature_map1(3,3) = 1*1 + 0*(-1) + 1*1 + 0*(-1) = 2
可以看到這就是最簡(jiǎn)單的內(nèi)積公式。feature_map1(1,1)表示在通過(guò)第一個(gè)卷積核計(jì)算完后得到的feature_map的第一行第一列的值,隨著卷積核的窗口不斷的滑動(dòng),我們可以計(jì)算出一個(gè)3*3的feature_map1;同理可以計(jì)算通過(guò)第二個(gè)卷積核進(jìn)行卷積運(yùn)算后的feature_map2,那么這一層卷積操作就完成了。feature_map尺寸計(jì)算公式:[ (原圖片尺寸 -卷積核尺寸)/ 步長(zhǎng) ] + 1。這一層我們?cè)O(shè)定了兩個(gè)2*2的卷積核,在paddlepaddle里是這樣定義的:
1 conv_pool_1 = paddle.networks.simple_img_conv_pool( 2 input=img, 3 filter_size=3, 4 num_filters=2, 5 num_channel=1, 6 pool_stride=1, 7 act=paddle.activation.Relu())
這里調(diào)用了networks里simple_img_conv_pool函數(shù),激活函數(shù)是Relu(修正線(xiàn)性單元),我們來(lái)看一看源碼里外層接口是如何定義的:
我們?cè)?span id="owocgsc" class="repo-root js-repo-root">Paddle/python/paddle/v2/framework/nets.py 里可以看到simple_img_conv_pool這個(gè)函數(shù)的定義:
1 def simple_img_conv_pool(input, 2 num_filters, 3 filter_size, 4 pool_size, 5 pool_stride, 6 act, 7 pool_type='max', 8 main_program=None, 9 startup_program=None): 10 conv_out = layers.conv2d( 11 input=input, 12 num_filters=num_filters, 13 filter_size=filter_size, 14 act=act, 15 main_program=main_program, 16 startup_program=startup_program) 17 18 pool_out = layers.pool2d( 19 input=conv_out, 20 pool_size=pool_size, 21 pool_type=pool_type, 22 pool_stride=pool_stride, 23 main_program=main_program, 24 startup_program=startup_program) 25 return pool_out
可以看到這里面有兩個(gè)輸出,conv_out是卷積輸出值,pool_out是池化輸出值,最后只返回池化輸出的值。conv_out和pool_out分別又調(diào)用了layers.py的conv2d和pool2d,去layers.py里我們可以看到conv2d和pool2d是如何實(shí)現(xiàn)的:
conv2d:
pool2d:
大家可以看到,具體的實(shí)現(xiàn)方式還調(diào)用了layers_helper.py:
詳細(xì)的源碼細(xì)節(jié)我們下一節(jié)會(huì)講這里指寫(xiě)一下實(shí)現(xiàn)的方式和調(diào)用的函數(shù)。
所以這個(gè)卷積過(guò)程就完成了。從上文的計(jì)算中我們可以看到,同一層的神經(jīng)元可以共享卷積核,那么對(duì)于高位數(shù)據(jù)的處理將會(huì)變得非常簡(jiǎn)單。并且使用卷積核后圖片的尺寸變小,方便后續(xù)計(jì)算,并且我們不需要手動(dòng)去選取特征,只用設(shè)計(jì)好卷積核的尺寸,數(shù)量和滑動(dòng)的步長(zhǎng)就可以讓它自己去訓(xùn)練了,省時(shí)又省力啊。
為什么卷積核有效?
那么問(wèn)題來(lái)了,雖然我們知道了卷積核是如何計(jì)算的,但是為什么使用卷積核計(jì)算后分類(lèi)效果要由于普通的神經(jīng)網(wǎng)絡(luò)呢?我們仔細(xì)來(lái)看一下上面計(jì)算的結(jié)果。通過(guò)第一個(gè)卷積核計(jì)算后的feature_map是一個(gè)三維數(shù)據(jù),在第三列的絕對(duì)值最大,說(shuō)明原始圖片上對(duì)應(yīng)的地方有一條垂直方向的特征,即像素?cái)?shù)值變化較大;而通過(guò)第二個(gè)卷積核計(jì)算后,第三列的數(shù)值為0,第二行的數(shù)值絕對(duì)值最大,說(shuō)明原始圖片上對(duì)應(yīng)的地方有一條水平方向的特征。
仔細(xì)思考一下,這個(gè)時(shí)候,我們?cè)O(shè)計(jì)的兩個(gè)卷積核分別能夠提取,或者說(shuō)檢測(cè)出原始圖片的特定的特征。此時(shí)我們其實(shí)就可以把卷積核就理解為特征提取器啊!現(xiàn)在就明白了,為什么我們只需要把圖片數(shù)據(jù)灌進(jìn)去,設(shè)計(jì)好卷積核的尺寸、數(shù)量和滑動(dòng)的步長(zhǎng)就可以讓自動(dòng)提取出圖片的某些特征,從而達(dá)到分類(lèi)的效果啊!
注:1.此處的卷積運(yùn)算是兩個(gè)卷積核大小的矩陣的內(nèi)積運(yùn)算,不是矩陣乘法。即相同位置的數(shù)字相乘再相加求和。不要弄混淆了。
2.卷積核的公式有很多,這只是最簡(jiǎn)單的一種。我們所說(shuō)的卷積核在數(shù)字信號(hào)處理里也叫濾波器,那濾波器的種類(lèi)就多了,均值濾波器,高斯濾波器,拉普拉斯濾波器等等,不過(guò),不管是什么濾波器,都只是一種數(shù)學(xué)運(yùn)算,無(wú)非就是計(jì)算更復(fù)雜一點(diǎn)。
3.每一層的卷積核大小和個(gè)數(shù)可以自己定義,不過(guò)一般情況下,根據(jù)實(shí)驗(yàn)得到的經(jīng)驗(yàn)來(lái)看,會(huì)在越靠近輸入層的卷積層設(shè)定少量的卷積核,越往后,卷積層設(shè)定的卷積核數(shù)目就越多。具體原因大家可以先思考一下,小結(jié)里會(huì)解釋原因。
- 池化層(Pooling Layer)
通過(guò)上一層2*2的卷積核操作后,我們將原始圖像由4*4的尺寸變?yōu)榱?*3的一個(gè)新的圖片。池化層的主要目的是通過(guò)降采樣的方式,在不影響圖像質(zhì)量的情況下,壓縮圖片,減少參數(shù)。簡(jiǎn)單來(lái)說(shuō),假設(shè)現(xiàn)在設(shè)定池化層采用MaxPooling,大小為2*2,步長(zhǎng)為1,取每個(gè)窗口最大的數(shù)值重新,那么圖片的尺寸就會(huì)由3*3變?yōu)?*2:(3-2)+1=2。從上例來(lái)看,會(huì)有如下變換:
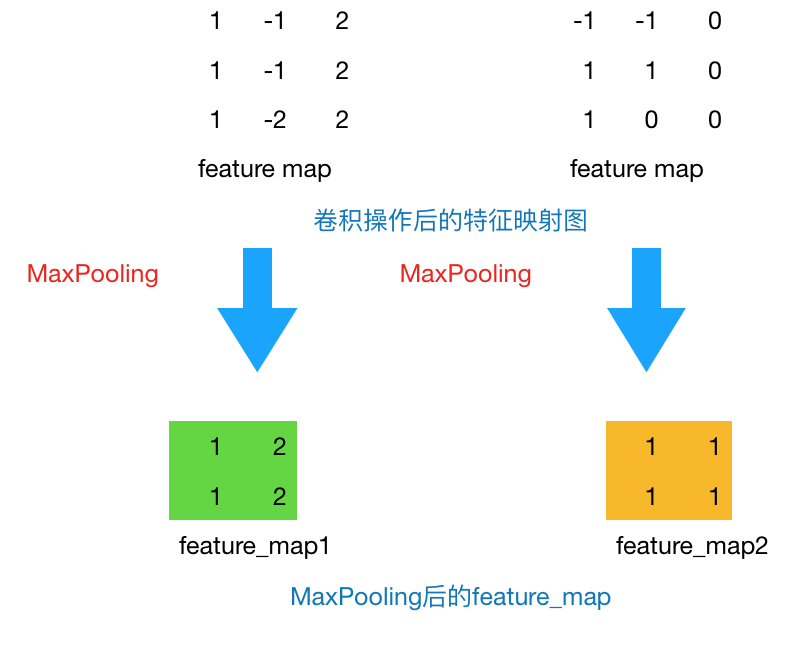
圖3 Max Pooling結(jié)果
通常來(lái)說(shuō),池化方法一般有一下兩種:
- MaxPooling:取滑動(dòng)窗口里最大的值
- AveragePooling:取滑動(dòng)窗口內(nèi)所有值的平均值
為什么采用Max Pooling?
從計(jì)算方式來(lái)看,算是最簡(jiǎn)單的一種了,取max即可,但是這也引發(fā)一個(gè)思考,為什么需要Max Pooling,意義在哪里?如果我們只取最大值,那其他的值被舍棄難道就沒(méi)有影響嗎?不會(huì)損失這部分信息嗎?如果認(rèn)為這些信息是可損失的,那么是否意味著我們?cè)谶M(jìn)行卷積操作后仍然產(chǎn)生了一些不必要的冗余信息呢?
其實(shí)從上文分析卷積核為什么有效的原因來(lái)看,每一個(gè)卷積核可以看做一個(gè)特征提取器,不同的卷積核負(fù)責(zé)提取不同的特征,我們例子中設(shè)計(jì)的第一個(gè)卷積核能夠提取出“垂直”方向的特征,第二個(gè)卷積核能夠提取出“水平”方向的特征,那么我們對(duì)其進(jìn)行Max Pooling操作后,提取出的是真正能夠識(shí)別特征的數(shù)值,其余被舍棄的數(shù)值,對(duì)于我提取特定的特征并沒(méi)有特別大的幫助。那么在進(jìn)行后續(xù)計(jì)算使,減小了feature map的尺寸,從而減少參數(shù),達(dá)到減小計(jì)算量,缺不損失效果的情況。
不過(guò)并不是所有情況Max Pooling的效果都很好,有時(shí)候有些周邊信息也會(huì)對(duì)某個(gè)特定特征的識(shí)別產(chǎn)生一定效果,那么這個(gè)時(shí)候舍棄這部分“不重要”的信息,就不劃算了。所以具體情況得具體分析,如果加了Max Pooling后效果反而變差了,不如把卷積后不加Max Pooling的結(jié)果與卷積后加了Max Pooling的結(jié)果輸出對(duì)比一下,看看Max Pooling是否對(duì)卷積核提取特征起了反效果。
Zero Padding
所以到現(xiàn)在為止,我們的圖片由4*4,通過(guò)卷積層變?yōu)?*3,再通過(guò)池化層變化2*2,如果我們?cè)偬砑訉樱敲磮D片豈不是會(huì)越變?cè)叫。窟@個(gè)時(shí)候我們就會(huì)引出“Zero Padding”(補(bǔ)零),它可以幫助我們保證每次經(jīng)過(guò)卷積或池化輸出后圖片的大小不變,如,上述例子我們?nèi)绻尤隯ero Padding,再采用3*3的卷積核,那么變換后的圖片尺寸與原圖片尺寸相同,如下圖所示:
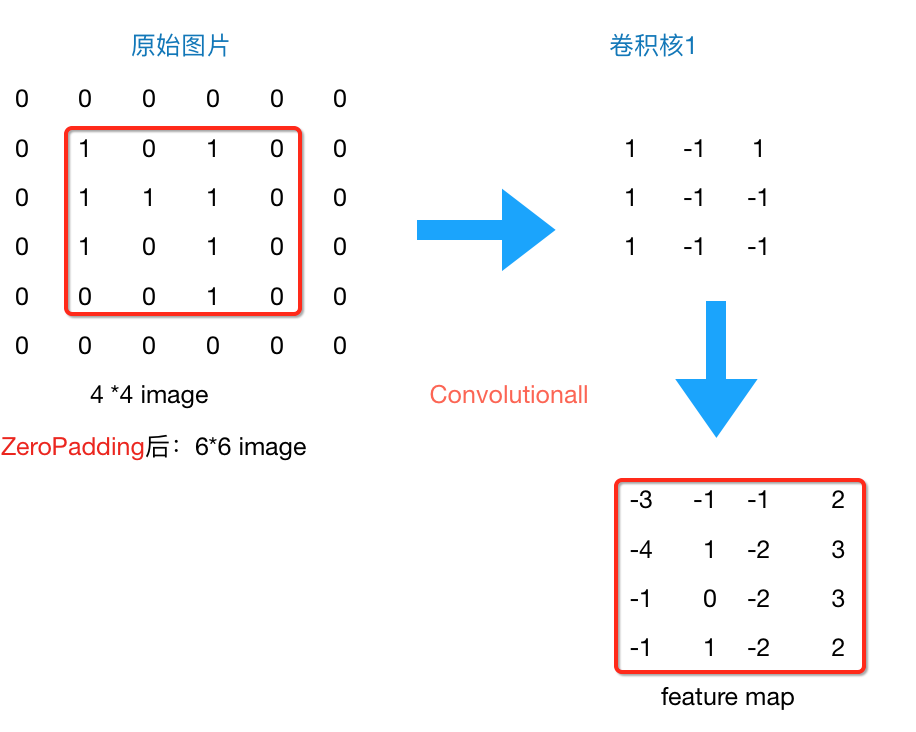
圖4 zero padding結(jié)果
通常情況下,我們希望圖片做完卷積操作后保持圖片大小不變,所以我們一般會(huì)選擇尺寸為3*3的卷積核和1的zero padding,或者5*5的卷積核與2的zero padding,這樣通過(guò)計(jì)算后,可以保留圖片的原始尺寸。那么加入zero padding后的feature_map尺寸 =( width + 2 * padding_size - filter_size )/stride + 1
注:這里的width也可換成height,此處是默認(rèn)正方形的卷積核,weight = height,如果兩者不相等,可以分開(kāi)計(jì)算,分別補(bǔ)零。
- Flatten層 & Fully Connected Layer
到這一步,其實(shí)我們的一個(gè)完整的“卷積部分”就算完成了,如果想要疊加層數(shù),一般也是疊加“Conv-MaxPooing",通過(guò)不斷的設(shè)計(jì)卷積核的尺寸,數(shù)量,提取更多的特征,最后識(shí)別不同類(lèi)別的物體。做完Max Pooling后,我們就會(huì)把這些數(shù)據(jù)“拍平”,丟到Flatten層,然后把Flatten層的output放到full connected Layer里,采用softmax對(duì)其進(jìn)行分類(lèi)。
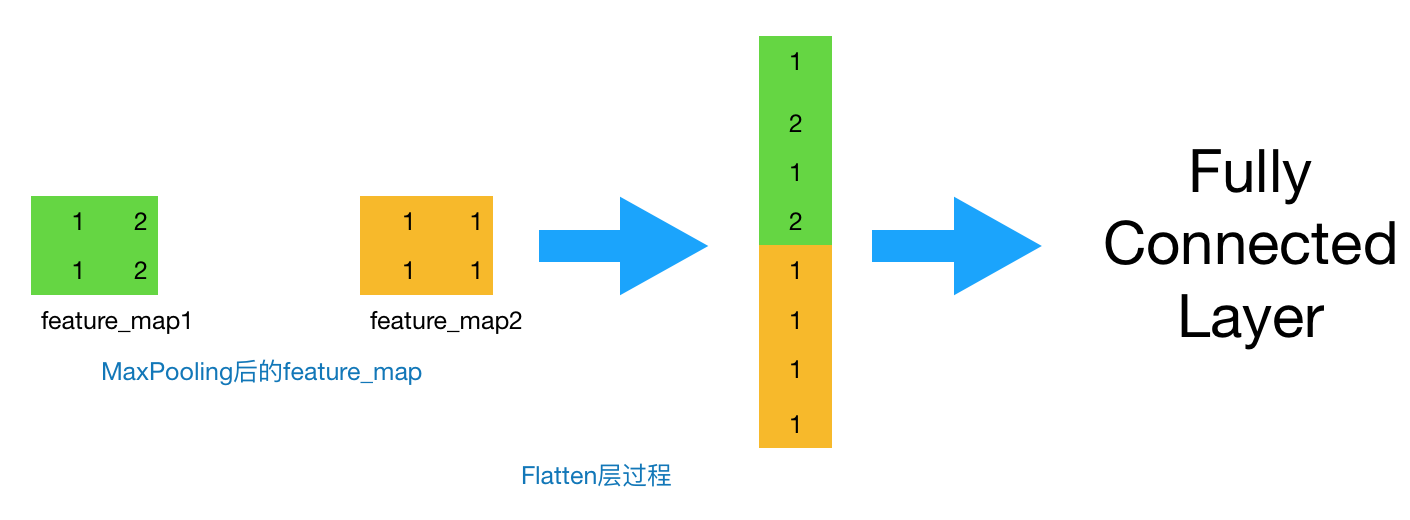
圖5 Flatten過(guò)程
- 小結(jié)
這一節(jié)我們介紹了最基本的卷積神經(jīng)網(wǎng)絡(luò)的基本層的定義,計(jì)算方式和起的作用。有幾個(gè)小問(wèn)題可以供大家思考一下:
1.卷積核的尺寸必須為正方形嗎?可以為長(zhǎng)方形嗎?如果是長(zhǎng)方形應(yīng)該怎么計(jì)算?
2.卷積核的個(gè)數(shù)如何確定?每一層的卷積核的個(gè)數(shù)都是相同的嗎?
3.步長(zhǎng)的向右和向下移動(dòng)的幅度必須是一樣的嗎?
如果對(duì)上面的講解真的弄懂了的話(huà),其實(shí)這幾個(gè)問(wèn)題并不難回答。下面給出我的想法,可以作為參考:
1.卷積核的尺寸不一定非得為正方形。長(zhǎng)方形也可以,只不過(guò)通常情況下為正方形。如果要設(shè)置為長(zhǎng)方形,那么首先得保證這層的輸出形狀是整數(shù),不能是小數(shù)。如果你的圖像是邊長(zhǎng)為 28 的正方形。那么卷積層的輸出就滿(mǎn)足 [ (28 - kernel_size)/ stride ] + 1 ,這個(gè)數(shù)值得是整數(shù)才行,否則沒(méi)有物理意義。譬如,你算得一個(gè)邊長(zhǎng)為 3.6 的 feature map 是沒(méi)有物理意義的。 pooling 層同理。FC 層的輸出形狀總是滿(mǎn)足整數(shù),其唯一的要求就是整個(gè)訓(xùn)練過(guò)程中 FC 層的輸入得是定長(zhǎng)的。如果你的圖像不是正方形。那么在制作數(shù)據(jù)時(shí),可以縮放到統(tǒng)一大小(非正方形),再使用非正方形的 kernel_size 來(lái)使得卷積層的輸出依然是整數(shù)。總之,撇開(kāi)網(wǎng)絡(luò)結(jié)果設(shè)定的好壞不談,其本質(zhì)上就是在做算術(shù)應(yīng)用題:如何使得各層的輸出是整數(shù)。
2.由經(jīng)驗(yàn)確定。通常情況下,靠近輸入的卷積層,譬如第一層卷積層,會(huì)找出一些共性的特征,如手寫(xiě)數(shù)字識(shí)別中第一層我們?cè)O(shè)定卷積核個(gè)數(shù)為5個(gè),一般是找出諸如"橫線(xiàn)"、“豎線(xiàn)”、“斜線(xiàn)”等共性特征,我們稱(chēng)之為basic feature,經(jīng)過(guò)max pooling后,在第二層卷積層,設(shè)定卷積核個(gè)數(shù)為20個(gè),可以找出一些相對(duì)復(fù)雜的特征,如“橫折”、“左半圓”、“右半圓”等特征,越往后,卷積核設(shè)定的數(shù)目越多,越能體現(xiàn)label的特征就越細(xì)致,就越容易分類(lèi)出來(lái),打個(gè)比方,如果你想分類(lèi)出“0”的數(shù)字,你看到這個(gè)特征,能推測(cè)是什么數(shù)字呢?只有越往后,檢測(cè)識(shí)別的特征越多,試過(guò)能識(shí)別這幾個(gè)特征,那么我就能夠確定這個(gè)數(shù)字是“0”。
3.有stride_w和stride_h,后者表示的就是上下步長(zhǎng)。如果用stride,則表示stride_h=stride_w=stride。
手寫(xiě)數(shù)字識(shí)別的CNN網(wǎng)絡(luò)結(jié)構(gòu)
上面我們了解了卷積神經(jīng)網(wǎng)絡(luò)的基本結(jié)構(gòu)后,現(xiàn)在來(lái)具體看一下在實(shí)際數(shù)據(jù)---手寫(xiě)數(shù)字識(shí)別中是如何操作的。上文中我定義了一個(gè)最基本的CNN網(wǎng)絡(luò)。如下(代碼詳見(jiàn)github):
1 def convolutional_neural_network_org(img): 2 # first conv layer 3 conv_pool_1 = paddle.networks.simple_img_conv_pool( 4 input=img, 5 filter_size=3, 6 num_filters=20, 7 num_channel=1, 8 pool_size=2, 9 pool_stride=2, 10 act=paddle.activation.Relu()) 11 # second conv layer 12 conv_pool_2 = paddle.networks.simple_img_conv_pool( 13 input=conv_pool_1, 14 filter_size=5, 15 num_filters=50, 16 num_channel=20, 17 pool_size=2, 18 pool_stride=2, 19 act=paddle.activation.Relu()) 20 # fully-connected layer 21 predict = paddle.layer.fc( 22 input=conv_pool_2, size=10, act=paddle.activation.Softmax()) 23 return predict
那么它的網(wǎng)絡(luò)結(jié)構(gòu)是:
conv1----> conv2---->fully Connected layer
非常簡(jiǎn)單的網(wǎng)絡(luò)結(jié)構(gòu)。第一層我們采取的是3*3的正方形卷積核,個(gè)數(shù)為20個(gè),深度為1,stride為2,pooling尺寸為2*2,激活函數(shù)采取的為RELU;第二層只對(duì)卷積核的尺寸、個(gè)數(shù)和深度做了些變化,分別為5*5,50個(gè)和20;最后鏈接一層全連接,設(shè)定10個(gè)label作為輸出,采用Softmax函數(shù)作為分類(lèi)器,輸出每個(gè)label的概率。
那么這個(gè)時(shí)候我考慮的問(wèn)題是,既然上面我們已經(jīng)了解了卷積核,改變卷積核的大小是否會(huì)對(duì)我的結(jié)果造成影響?增多卷積核的數(shù)目能夠提高準(zhǔn)確率?于是我做了個(gè)實(shí)驗(yàn):
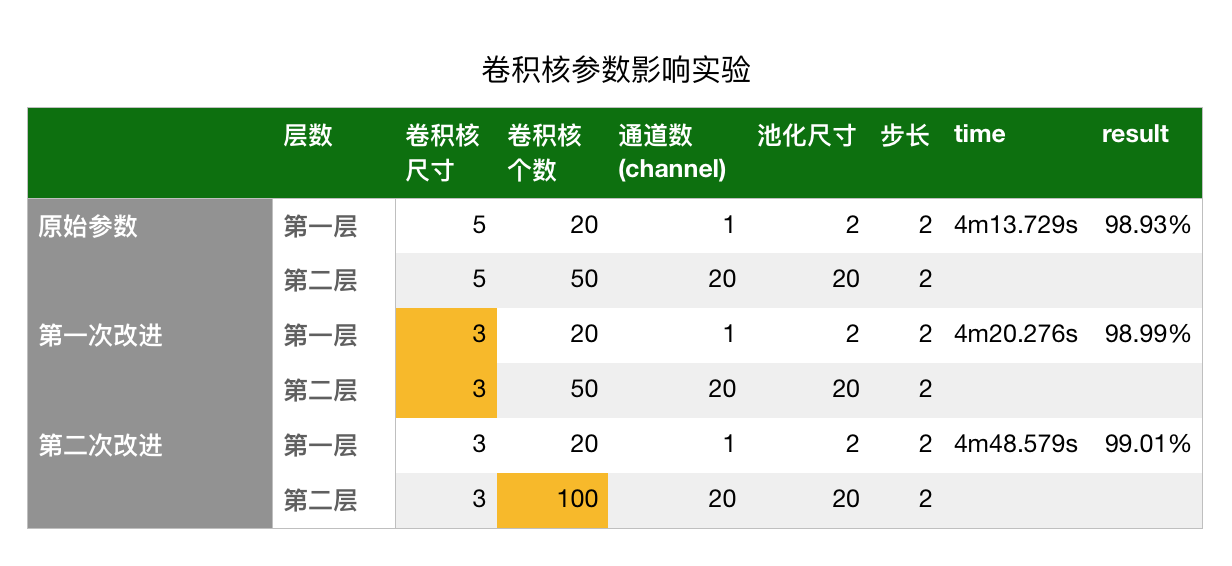
- 第一次改進(jìn):僅改變第一層與第二層的卷積核數(shù)目的大小,其他保持不變。可以看到結(jié)果提升了0.06%
- 第二次改進(jìn):保持3*3的卷積核大小,僅改變第二層的卷積核數(shù)目,其他保持不變,可以看到結(jié)果相較于原始參數(shù)提升了0.08%
由以上結(jié)果可以看出,改變卷積核的大小與卷積核的數(shù)目會(huì)對(duì)結(jié)果產(chǎn)生一定影響,在目前手寫(xiě)數(shù)字識(shí)別的項(xiàng)目中,縮小卷積核尺寸,增加卷積核數(shù)目都會(huì)提高準(zhǔn)確率。不過(guò)以上實(shí)驗(yàn)只是一個(gè)小測(cè)試,有興趣的同學(xué)可以多做幾次實(shí)驗(yàn),看看參數(shù)帶來(lái)的具體影響,下篇文章我們會(huì)著重分析參數(shù)的影響。
這篇文章主要介紹了神經(jīng)網(wǎng)絡(luò)的預(yù)備知識(shí),卷積神經(jīng)網(wǎng)絡(luò)的常見(jiàn)的層及基本的計(jì)算過(guò)程,看完后希望大家明白以下幾個(gè)知識(shí)點(diǎn):
- 為什么卷積神經(jīng)網(wǎng)絡(luò)更適合于圖像分類(lèi)?相比于傳統(tǒng)的神經(jīng)網(wǎng)絡(luò)優(yōu)勢(shì)在哪里?
- 卷積層中的卷積過(guò)程是如何計(jì)算的?為什么卷積核是有效的?
- 卷積核的個(gè)數(shù)如何確定?應(yīng)該選擇多大的卷積核對(duì)于模型來(lái)說(shuō)才是有效的?尺寸必須為正方形嗎?如果是長(zhǎng)方形因該怎么做?
- 步長(zhǎng)的大小會(huì)對(duì)模型的效果產(chǎn)生什么樣的影響?垂直方向和水平方向的步長(zhǎng)是否得設(shè)定為相同的?
- 為什么要采用池化層,Max Pooling有什么好處?
- Zero Padding有什么作用?如果已知一個(gè)feature map的尺寸,如何確定zero padding的數(shù)目?
上面的問(wèn)題,有些在文章中已經(jīng)詳細(xì)講過(guò),有些大家可以根據(jù)文章的內(nèi)容多思考一下。最后給大家留幾個(gè)問(wèn)題思考一下:
- 為什么改變卷積核的大小能夠提高結(jié)果的準(zhǔn)確率?卷積核大小對(duì)于分類(lèi)結(jié)果是如何影響的?
- 卷積核的參數(shù)是怎么求的?一開(kāi)始隨機(jī)定義一個(gè),那么后來(lái)是如何訓(xùn)練才能使這個(gè)卷積核識(shí)別某些特定的特征呢?
- 1*1的卷積核有意義嗎?為什么有些網(wǎng)絡(luò)層結(jié)構(gòu)里會(huì)采用1*1的卷積核?
下篇文章我們會(huì)著重講解以下幾點(diǎn):
- 卷積核的參數(shù)如何確定?隨機(jī)初始化一個(gè)數(shù)值后,是如何訓(xùn)練得到一個(gè)能夠識(shí)別某些特征的卷積核的?
- CNN是如何進(jìn)行反向傳播的?
- 如何調(diào)整CNN里的參數(shù)?
- 如何設(shè)計(jì)最適合的CNN網(wǎng)絡(luò)結(jié)構(gòu)?
- 能夠不用調(diào)用框架的api,手寫(xiě)一個(gè)CNN,并和paddlepaddle里的實(shí)現(xiàn)過(guò)程做對(duì)比,看看有哪些可以改進(jìn)的?
ps:本篇文章是基于個(gè)人對(duì)CNN的理解來(lái)寫(xiě)的,本人能力有限,有些地方可能寫(xiě)的不是很?chē)?yán)謹(jǐn),如有錯(cuò)誤或疏漏之處,請(qǐng)留言給我,我一定會(huì)仔細(xì)核實(shí)并修改的^_^!不接受無(wú)腦噴哦~此外,文中的圖表結(jié)構(gòu)均為自己所做,希望不要被人隨意抄襲,可以進(jìn)行非商業(yè)性質(zhì)的轉(zhuǎn)載,需要轉(zhuǎn)載留言或發(fā)郵件即可,希望能夠尊重勞動(dòng)成果,謝謝!有不懂的也請(qǐng)留言給我,我會(huì)盡力解答的哈~