日均萬條數據丟失,一個隱式騷操作導致的奇葩事故!
主從復制作為 MySQL 的精髓,有兩大困難:主從數據的延時與數據的不一致性。針對數據不一致的排查處理,相信各位大佬們都有豐富的處理經驗,我就不多說了。
本文主要是給大家分享一個工作中遇到的奇葩事例:由于一個極隱式的騷操作,導致從庫丟失數據(數據丟失量在每天將近萬條記錄)!
環境描述
業務環境:短時間內(幾個月的時間),業務蓬勃發展,客戶量從一兩萬一下增加到幾十萬用戶。
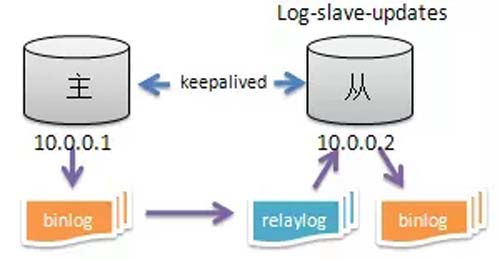
數據庫環境,如下圖:
問題描述
某天,主庫 10.0.0.1 的 CPU 使用率突然升高,均值達到 80%+,導致 Keepalived 的 VIP 漂移至從庫 10.0.0.2。
理論上丟失的是切換過程中的幾秒鐘數據,業務側對丟失的這幾秒數據表示沒關系,那么這個事件到此應該就結束了。
然而當天晚上,業務打電話過來說:丟失了部分用戶信息,導致用戶登入不了,要求幫忙恢復數據并查找數據丟失的原因。
本文對數據恢復這塊就不具體展開了,稍微提一下,這邊因為新主 10.0.0.2 已經有數據寫入,只能對比用戶表數據把新主少的數據導入進去。
初步排查
對于主從復制丟失數據,解決方法沒有捷徑,只能老老實實地跟蹤數據復制過程,查看是哪里出了問題。
選擇丟失數據中時間比較近的,時間為 2017-06-09 13:36:01,ID為 849791 這條數據,來跟蹤整個復制過程,因為日志只保留 14 天的。
分析主庫 binlog 日志,binlog 日志中是有這條記錄的。
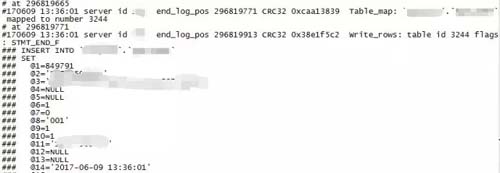
分析從庫日志:因為數據庫配置了 relay_log_purge 與 log-slave-updates,所以中繼日志已經找不到這個時間點了,只能查看從庫 binlog 日志。
然而在從庫的 binlog 日志中并未找到這條記錄,說明這條數據是未執行,排除后期人為刪除的,那么數據為何不被執行呢?或者說數據是在執行過程中丟失的?
數據分析
無可用的中繼日志怎么辦?難道沒辦法查了?于是我決定觀察和對比一下丟失的數據,看看其中是否含有什么規律,是不定時丟失數據,還是會在某些特定時刻丟失數據。
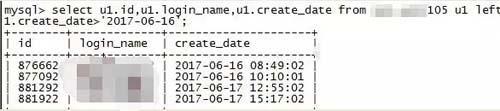
整理了一下某表丟失的數據,通過觀察、分析丟失數據的屬性(下圖是我截取的部分列,***一列的時間是創建時間,也就是寫表時間):
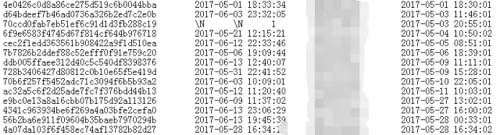
從圖中可以看出,丟失的數據的插表時間都是在每分鐘的前 2 秒。這不由地讓人思考,為何丟失的數據是每分鐘前 2 秒的呢?
而且數據丟失的時間間隔也不是很長,基本隔幾天就肯定有數據丟失。經過這樣分析,事情似乎就變得簡單了。
深入調查
首先,關閉 log-slave-updates、relay_log_purge 等一切影響判斷的額外參數設置,等待一段時間后,再來對比某表新數據丟失情況。
可以看到又有新數據丟失,根據這些丟失數據再來排查問題。
首先先查主庫,查看主庫的 binlog 日志狀體信息狀態。
就以 2017-6-17 15:17:02 ***丟失的這條數據來跟蹤,查看主庫 10.0.0.2 上的 binlog 日志中是否存在這條數據:
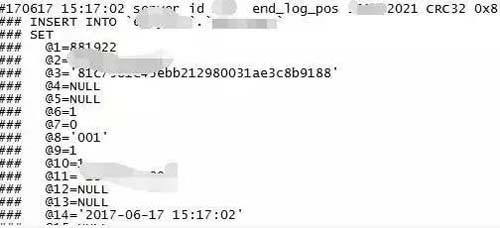
結果顯示主庫是存在這條數據的
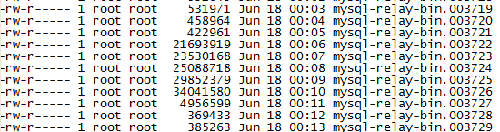
在登入從庫查看 relay-log 日志情況,發現 relay-log 日志生成太頻繁,每分鐘生成 1 個 relay-log 日志,而且有些文件大小又不一致。
那么這套主從集群,業務肯定部署過分割 relay-log 日志的腳本,而且應該是 flush 來強制刷新的。如圖:
我們先來看從庫 relay-log 日志中是否存在這條數據,查找17分生成的relay日志,提取前 2 秒能匹配的插入情況。

發現并沒有這條 insert 操作,難道數據未寫入 relay 日志,刷新日志時導致事務丟失? 把查詢時間拉長至 50 秒。

發現也沒有這條數據,并且數據跟前面 2 秒的一致,那么其它數據呢?會不會在下一個日志中?
趕緊去 18 分生成的 relay 日志查看,發現這條數據在 15:18 分這個 relay 日志中的***個事務的位置。
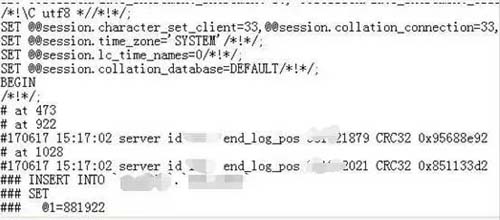
那么是沒有執行,還是執行過程丟失?仔細觀察主庫 binlog 與從 relay-log 日志的記錄,也沒能看出什么名堂,從事務開始到 commit,都一樣。
問題定位
如果一條數據無法比較,那就再隨機拿出幾條丟失的數據來跟蹤。發現情況都一樣,數據都已經復制到 relay 日志中,而且內容根本看不出為何不能執行。
唯一有疑點的是這些事務都在日志的***個事務中。頓時,我有種想法,會不會強制刷新 relay 日志,造成日志的***個事務有時不執行,或執行過程中丟失?
如果是腳本引起的,那么除去這些事務未執行外,肯定還有其它事務也未執行。那么,我就隨機選擇幾個 relay-log 日志,找到***個事務。
具體分析如下:

再登入從庫查詢結果:
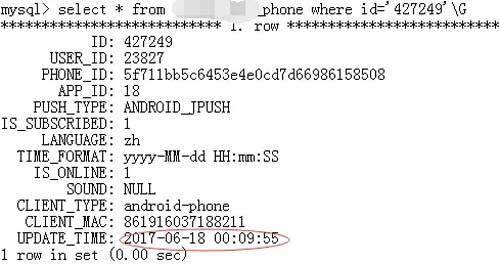
可以看出從庫數據并未更新。隨后,隨機分析了幾個 relay 日志,發現***個事務都未被執行。而且操作的表都是有不同的,操作也是有不同,有 insert、update 等等,頓時感覺事情大條了。
如果每個日志的***個事務都未執行,那么從庫要缺少多少條數據?不敢想象,現在業務還在上升期,不久業務量會是現在的幾倍,甚至更多,到那時就不是用戶投訴那么簡單了。
又抓取了部分 relay 日志情況,***個事務也都未被執行。我可以肯定了,是所有 relay 日志的***個事務都未被執行。
這個問題也可以是由于分割 relay 日志的腳本造成的。一般強制刷新日志是用 flush 命令來操作的,flush 命令一般不會造成數據丟失,當然像他們這樣頻繁的操作,我是不知道會不會造成 Bug,導致丟數據。
還有在 flush relay logs 的時候有沒有用到其他的什么操作呢?我決定抓一把數據庫中操作過的命令。
抓取命令,問題解決
想到就做,登上從庫主機、登入數據庫,開啟 general_log 日志。坐等 5 分鐘,打開日志,尋找每分鐘前幾秒的記錄。
哇!哇!哇!
你們猜我看到了什么? 我從未見過如此騷的操作!上圖,以表我的震驚。
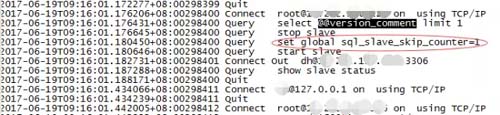
為什么要跳過事務?你用 stop slave 與 Start slave 來刷新 relay 日志,已經刷新了我的三觀,那,有必要跳過事務?這就解釋得通了,為何 relay 日志***個事務全都丟失。
至此!問題已經清晰,是由于開發設置的分割 relay 日志的腳本,使用了非常規命令及 sql_slave_skip_counter 跳過事務命令來分隔 relay-log 日志,導致事務大量丟失。
所以,創新是好事,但要打好基本功,別搞些騷操作。
洪凌
新炬網絡資深 MySQL 工程師
超過 7 年 MySQL 數據庫運維經驗,擅長數據庫運維體系、集群架構建設,熟悉 MySQL 性能優化,對數據庫監控系統也有著獨特的理解。