除了自然語言處理,你還可以用詞嵌入(Word2Vec)做這個
當使用機器學習方法來解決問題的時候,擁有合適的數據是非常關鍵的。不幸的是,通常情況下的原始數據是「不干凈」的,并且是非結構化的。自然語言處理(NLP)的從業者深諳此道,因為他們所用的數據都是文本的。由于大多數機器學習算法不接受原始的字符串作為輸入,所以在輸入到學習算法之前要使用詞嵌入的方法來對數據進行轉換。但這不僅僅存在于文本數據的場景,它也能夠以分類特征的形式存在于其他標準的非自然語言處理任務中。事實上,我們很多人都在苦苦研究這種分類特征過程,那么詞嵌入方法在這種場景中有什么作用呢?
這篇文章的目標是展示我們如何能夠使用一種詞嵌入方法,Word2Vec(2013,Mikolov 等),來把一個具有大量模態的分類特征轉換為一組較小的易于使用的數字特征。這些特征不僅易于使用,而且能夠成功學習到若干個模態之間的關系,這種關系與經典詞嵌入處理語言的方式很相似。
Word2Vec
觀其伴,知其意。(Firth, J. R. 1957.11)
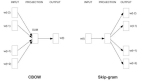
上述內容準確地描述了 Word2Vec 的目標:它嘗試通過分析一個詞的鄰詞(也稱作語境)來確定該詞的含義。這個方法有兩種不同風格的模型:CBOW 模型和 Skip-Gram 模型。在給定語料庫的情況下,模型在每個語句的詞上循環,要么根據當前單詞來預測其鄰詞(語境),要么根據當前的語境來預測當前的詞,前者所描述的方法被稱作「Skip-Gram」,后者被稱作「連續性詞包,continuous bag of words(CBOW)」。每個語境中單詞數目的極限是由一個叫做「窗大小,Window Size」的參數來決定的。
 代表的是當前單詞,w(t-2)..w(t+2) 代表的是語境單詞。(Mikolov 等人. 2013)")
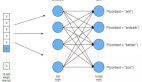
因此,如果你選擇了 Skip-Gram 方法,Word2Vec 就會使用一個淺層的神經網絡,也就是說,用一個只具有一個隱藏層的神經網絡來學習詞嵌入。網絡首先會隨機地初始化它的權重,然后使用單詞來預測它的語境,在最小化它所犯錯誤的訓練過程中去迭代調整這些權重。有望在一個比較成功的訓練過程之后,能夠通過網絡權重矩陣和單詞的 one-hot 向量的乘積來得到每一個單詞的詞向量。
注意:除了能夠允許將文本數據進行數字表征之外,結果性嵌入還學習到了單詞之間的而一些有趣的關系,可以被用來回答類似于下面的這種問題:國王之于王后,正如父親之于......?
如果你想了解更多的關于 Word2Vec 的細節知識,你可以看一下斯坦福大學的課程(https://www.youtube.com/watch?v=ERibwqs9p38),或者 TensorFlow 的相關教程(https://www.tensorflow.org/tutorials/word2vec)。
應用
我們在 Kwyk 平臺上(https://www.kwyk.fr/)上提供在線的數學練習。老師給他們的學生布置作業,每次練習完成的時候都會有一些數據被存儲下來。然后,我們利用收集到的數據來評價每個學生的水平,并且給他們量身制作對應的復習來幫助他們進步。對于每一個被解答的練習作業,我們都保存了一系列的標識符來幫助我們區分以下信息:這是什么練習?作答的學生是誰?屬于哪一個章節?....... 除此之外,我們還會根據學生是否成功地解答了這個題目來保存一個分數,要么是 0,要么是 1。然后,為了評價學生的分數,我們必須預測這個分數,并且從我們的分類器中得到學生成功的概率。
正如你所看到的,我們的很多特征都是可以分類的。通常情況下,當模態的數目足夠小的時候,你可以簡單地將 n 模態的分類特征轉換為 n-1 維的啞變量,然后用它們去訓練。但是當模態是成千上萬級別的時候——就像在我們應用中的一些情況一樣——依靠啞變量就顯得沒有效率并且不切實際。
為了解決這個問題,我們通過一個小技巧采用 Word2Vec 把分類特征轉換為數量相當少的可用連續特征。為了闡述這個想法,我們以「exercise_id」為例來說明:exercise_id 是一個分類特征,它能夠告訴我們被解答過的練習題是哪一個。為了能夠使用 Word2Vec,我們提供一個語料庫,也就是將要輸入到我們的算法中的一系列句子。然而,原始的特征只是一個 ID 的列表而已,它本質上并不是語料庫:它的順序完全是隨機的,相近的 ID 也并沒有攜帶著其相鄰的 ID 任何信息。我們的技巧包括把某個老師布置的一次作業看做一個「句子」,也就是一連串的 exercise_id。結果就是,所有的 ID 會很自然地以等級、章節等標簽被收集在一起,然后 Word2Vec 可以直接在這些句子上面開始學習練習的嵌入(exercise embedding,對應于 Word embedding)。
事實上,正是由于這些人為的句子我們才得以使用 Word2Vec,并得到了很漂亮的結果:
(用 PCA 方法得到了 3 個主成分,就是圖中的 3 維空間);圖中的 6e, 5e, 4e, 3e, 2e, 1e 以及 tm 是法國學生的水平,與美國的 6th, 7th, 8th, 9th, 10th,11th 和 12th 等價。")
如我們所看到的的,結果性嵌入是有結構的。事實上,練習的 3D 投影云是螺旋形的,高級別的練習緊跟在較低級別的后面。這也意味著嵌入成功地學會了區分不同級別的練習題目,并且把練習題目重新分組,具有相似級別的被放在了一起。但是這還不是全部,使用非線性的降維技術之后,我們可以將整個嵌入降維成一個具有相同特征的實值變量。換句話說,我們得到了一個關于練習復雜度的特征,6 年級(6th)最小,隨著練習越來越復雜,這個變量越來越大,直到 12 年級達到該變量的***值。
更有甚者,正如 Mikolov 在英語單詞上做到的一樣,嵌入還習得了練習之間的關系:

上圖展示了我們的嵌入能夠學習到的關系的一些實例。所以當我們問「一個數字相加的練習之于一個數字相減的練習,正如一個時間相加的練習之于......?」之后,嵌入給出了如下的答案:「一個時間相減的練習」。具體而言,這意味著如果我們提出這個問題:嵌入 [減(數字)Substract(Numbers)] --嵌入 [加(數字),Add(Numbers)],并把它添加到學生練習的嵌入中,其中學生被要求來做時間的加法(例如,小時、分鐘等等),那么與之最接近的一個嵌入就是包含時間減法的練習。
結論
總之,詞嵌入技術在將文本數據轉換成便于機器學習算法直接使用的實值向量時是有用的,盡管詞嵌入技術主要用在自然語言處理的應用中,例如機器翻譯,但是我們通過給出特定的用在 Kwyk 中的例子展示了這些技術在分類特征處理中也有用武之地。然而,為了使用諸如 Word2Vec 這樣的技術,你必須建立一個語料庫——也就是說,一組句子,其中的標簽已經被排列好了,所以其語境也是已經隱式創建好了。上述實例中,我們使用在網站上給出的作業來創建練習的「句子」,并且學習練習嵌入。結果就是,我們能夠得到新的數字特征,這些特征能夠成功地學習練習之間的關系,比它們被打上的那組原始標簽更加有用。
向 Christophe Gabar 致謝,他是我們 Kwyk 的開發人員之一,他提出了把 word2vec 用在分類特征上的思想。
原文鏈接:https://medium.com/towards-data-science/a-non-nlp-application-of-word2vec-c637e35d3668