達(dá)觀數(shù)據(jù)漫談Word2vec之skip-gram模型應(yīng)用
word2vec是Google研究團(tuán)隊(duì)的成果之一,它作為一種主流的獲取分布式詞向量的工具,在自然語(yǔ)言處理、數(shù)據(jù)挖掘等領(lǐng)域有著廣泛的應(yīng)用。達(dá)觀數(shù)據(jù)的文本挖掘業(yè)務(wù)有些地方就使用了該項(xiàng)技術(shù)。本文從以下幾個(gè)方面簡(jiǎn)要介紹Word2vec的skip-gram模型:***部分對(duì)比word2vec詞向量和one-hot詞向量,引出word2vec詞向量的優(yōu)勢(shì)所在;第二部分給出skip-gram模型的相關(guān)內(nèi)容;第三部分簡(jiǎn)單介紹模型求解時(shí)優(yōu)化方面的內(nèi)容;第四部分通過例子簡(jiǎn)單給出詞向量模型的效果;第五部分作出總結(jié)。
1. 優(yōu)勢(shì)
word2vec詞向量與傳統(tǒng)的one-hot詞向量相比,主要有以下兩個(gè)優(yōu)勢(shì)。
1.1低維稠密
一般來說分布式詞向量的維度設(shè)置成100-500就足夠使用,而one-hot類型的詞向量維度與詞表的大小成正比,是一種高維稀疏的表示方法,這種表示方法導(dǎo)致其在計(jì)算上具有比較低效率。

Fig.1. one-hot詞向量
1.2蘊(yùn)含語(yǔ)義信息
one-hot這種表示方式使得每一個(gè)詞映射到高維空間中都是互相正交的,也就是說one-hot向量空間中詞與詞之間沒有任何關(guān)聯(lián)關(guān)系,這顯然與實(shí)際情況不符合,因?yàn)閷?shí)際中詞與詞之間有近義、反義等多種關(guān)系。Word2vec雖然學(xué)習(xí)不到反義這種高層次語(yǔ)義信息,但它巧妙的運(yùn)用了一種思想:“具有相同上下文的詞語(yǔ)包含相似的語(yǔ)義”,使得語(yǔ)義相近的詞在映射到歐式空間后,具有較高的余弦相似度。
- simapple,banana=vecapple∙vecbananavecapple∙vecbanana

Fig.2. word2vec詞向量
2. skip-gram模型
2.1 訓(xùn)練樣本
怎么把“具有相同上下文的詞語(yǔ)包含相似的語(yǔ)義”這種思想融入模型是很關(guān)鍵的一步,在模型中,兩個(gè)詞是否出現(xiàn)在一起是通過判斷這兩個(gè)詞在上下文中是否出現(xiàn)在一個(gè)窗口內(nèi)。例如,原始樣本“達(dá)觀數(shù)據(jù)是一家做人工智能的公司”在送入模型前會(huì)經(jīng)過圖3所示處理(這里為了繪圖簡(jiǎn)單假設(shè)窗口為2,一般窗口是設(shè)置成5)。
如圖3所示,skip-gram模型的輸入是當(dāng)前詞,輸出是當(dāng)前詞的上下文,雖然我們訓(xùn)練模型的時(shí)候喂的是一個(gè)個(gè)分詞好的句子,但內(nèi)部其實(shí)是使用一個(gè)個(gè)word pair來訓(xùn)練。同樣是之前的case“達(dá)觀數(shù)據(jù)是一家做人工智能的公司”,假如窗口改為5,則(達(dá)觀數(shù)據(jù),人工智能)這個(gè)word pair會(huì)成為一個(gè)訓(xùn)練樣本。假如再過來一個(gè)case“Google是一家人工智能公司”,則(Google,人工智能)也會(huì)成為一個(gè)訓(xùn)練樣本。如果用來訓(xùn)練的語(yǔ)料庫(kù)中會(huì)產(chǎn)生多個(gè)(達(dá)觀數(shù)據(jù),人工智能)、(Google,人工智能)這種的訓(xùn)練樣本,則可以推測(cè)“達(dá)觀數(shù)據(jù)”和“Google”會(huì)有較高的相似度,因?yàn)樵谟?xùn)練樣本中這兩個(gè)詞具有相同的輸出,推而廣之,也就是說這兩個(gè)詞具有相同的上下文。一言以蔽之“假如兩個(gè)詞具有相同的輸出,則可反推出作為輸入的兩個(gè)詞之間具有較高相似性”,接下來就是如何使用模型來實(shí)現(xiàn)上述目標(biāo)。
練樣本")
Fig.3. 訓(xùn)練樣本
2.2 skip-gram模型
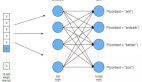
skip-gram模型與自編碼器(Autoencoder)類似,唯一的區(qū)別在于自編碼器的輸出等于輸入,而skip-gram模型的輸出是輸入的上下文。那么,作為訓(xùn)練樣本的word pair應(yīng)該以什么樣的方式輸入給模型? 答案是one-hot向量,為了得到one-hot向量,必須首先知道訓(xùn)練語(yǔ)料中包含了多少詞。因此,在訓(xùn)練之前會(huì)首先對(duì)語(yǔ)料進(jìn)行統(tǒng)計(jì),得到詞表。假設(shè)詞表長(zhǎng)度為10000,詞向量為300維,則skip-gram模型可表示為圖4。

Fig.4. skip-gram 模型
如圖4所示,假設(shè)輸入的word pair為(ants, able),則模型擬合的目標(biāo)是Max Pableants ,同時(shí)也需要滿足Min Pother wordsants,這里利用的是對(duì)數(shù)似然函數(shù)作為目標(biāo)函數(shù)。上述表述中Pableants可表示為:
- Pableants= softmax( Xants 1×10000∙W10000×300)
- softmaxX= exp(X1×300∙W300×1)i=110000exp(X1×300i∙W300×1)
根據(jù)Pableants和 Pother wordsants,可構(gòu)建似然函數(shù):
- LW= Pableantsy=able∙ Pother wordsantsy=other words
則:
- logLW =y=target wordlogPableants+logPother wordsants
- =i10000y=target wordlogP(wordi|ants)
將P(wordi|ants)代入有:
- logLW= i10000y=target wordlogexp(X1×300∙W300×1)i=110000exp(X1×300i∙W300×1)
式中*表示如果表達(dá)式*為true,則*=1,否則*=0。接下來要做的是***化似然函數(shù),也即:
- Max logLW
要實(shí)現(xiàn)上述目標(biāo),可利用梯度上升法,首先對(duì)參數(shù)求偏導(dǎo):
- ∂logLW∂wi=xiy=target word-P(target word|xi;W)
接下來根據(jù)學(xué)習(xí)率對(duì)wi進(jìn)行更新:
- wi= wi+ η∙∂logLW∂wi
現(xiàn)在問題來了,模型訓(xùn)練完成后,詞向量在哪呢?隱藏層的參數(shù)矩陣W10000×300就包含了所有詞的詞向量,該矩陣的行為詞表長(zhǎng)度,列為詞向量維度,矩陣中的每一行表示一個(gè)詞的詞向量。由于輸入層Xants 1×10000是one-hot向量,與隱藏層W10000×300點(diǎn)乘后是選中了該矩陣中的一行,如圖5所示,這一行表示的是ants的詞向量,而輸出層是以ants的詞向量為特征,以ants的上下文詞作為類別來訓(xùn)練softmax分類器。
乘隱藏層權(quán)值矩陣得到該詞的詞向量")
Fig.5.詞的one-hot向量點(diǎn)乘隱藏層權(quán)值矩陣得到該詞的詞向量
回到上文,為什么說(達(dá)觀數(shù)據(jù),人工智能)、(Google,人工智能)這種樣本多了之后會(huì)得出達(dá)觀數(shù)據(jù)和Google的相似度會(huì)比較高?當(dāng)時(shí)解釋的是因?yàn)檫@兩個(gè)詞有相同的輸出,更深一步講是因?yàn)檩敵鰧訁?shù)矩陣W300×10000是所有詞向量共享的。具體來說,模型訓(xùn)練完成后會(huì)達(dá)到類似下面的效果: wv達(dá)觀數(shù)據(jù)1×300∙ W300×10000≈wvGoogle1×300∙ W300×10000≈人工智能
由上面可直接看出來wv(達(dá)觀數(shù)據(jù)) ≈wv(Google),其中wv(*)表示*的詞向量,約等于是指兩個(gè)向量所指的方向在空間中比較接近。
3. 模型優(yōu)化
3.1 欠采樣 subsample
圖3中的例子中“是”、“的”這種詞在任何場(chǎng)景中都可能出現(xiàn),它們并不包含多少語(yǔ)義,而且出現(xiàn)的頻率特別高,如果不加處理會(huì)影響詞向量的效果。欠采樣就是為了應(yīng)對(duì)這種現(xiàn)象,它的主要思想是對(duì)每個(gè)詞都計(jì)算一個(gè)采樣概率,根據(jù)概率值來判斷一個(gè)詞是否應(yīng)該保留。概率計(jì)算方法為:
- Pword=f(word)0.001+1∙0.001f(word)
其中f(*)表示*出現(xiàn)的概率,0.001為默認(rèn)值,具體函數(shù)走勢(shì)如圖6所示,可以看出,詞語(yǔ)出現(xiàn)的概率越高,其被采樣到的概率就越低。這里有一點(diǎn)IDF的味道,不同的是IDF是為了降低詞的特征權(quán)重,欠采樣是為了降低詞的采樣概率。
")
Fig.6. 欠采樣函數(shù)
3.2 負(fù)采樣 negative sample
以圖4所示的模型為例,對(duì)每一個(gè)訓(xùn)練樣本需要更新的參數(shù)個(gè)數(shù)有三百萬(wàn)(準(zhǔn)確的說是三百萬(wàn)零三百,由于輸入是one-hot,隱藏層每次只需要更新輸入詞語(yǔ)的詞向量),這還是假設(shè)詞表只有一萬(wàn)的情況下,實(shí)際情況會(huì)有五十萬(wàn)甚至更多,這時(shí)候參數(shù)就達(dá)到了億級(jí)。訓(xùn)練過程中要對(duì)每個(gè)參數(shù)計(jì)算偏導(dǎo),然后進(jìn)行更新,這需要很大的計(jì)算資源。
負(fù)采樣是加快訓(xùn)練速度的一種方法,這里的負(fù)可以理解為負(fù)樣本。針對(duì)訓(xùn)練樣本(ants, able),able這個(gè)詞是正樣本,詞表中除able外的所有詞都是負(fù)樣本。負(fù)采樣是對(duì)負(fù)樣本進(jìn)行采樣,不進(jìn)行負(fù)采樣時(shí),對(duì)每一個(gè)訓(xùn)練樣本模型需要擬合一個(gè)正樣本和九千九百九十九個(gè)負(fù)樣本。加入負(fù)采樣后,只需要從這九千九百九十九個(gè)負(fù)樣本中挑出來幾個(gè)進(jìn)行擬合,大大節(jié)省了計(jì)算資源。那么應(yīng)該挑幾個(gè)負(fù)樣本,根據(jù)什么進(jìn)行挑呢?Google給出的建議是挑5-20個(gè),怎么挑是根據(jù)詞在語(yǔ)料中出現(xiàn)的概率,概率越大越有可能被選中,具體計(jì)算公式為:
- Pword=f(word)34i=110000f(wordi)34
其中f(*)表示*出現(xiàn)的概率。
3.3 層次softmax
層次softmax的目的和負(fù)采樣一樣,也是為了加快訓(xùn)練速度,但它相對(duì)復(fù)雜,沒有負(fù)采樣這種來的簡(jiǎn)單粗暴。具體來說,使用層次softmax時(shí)圖4中的模型輸出層不再是使用one-hot加softmax回歸,而是使用Huffman樹加softmax回歸。在模型訓(xùn)練的時(shí)候首先統(tǒng)計(jì)語(yǔ)料中詞語(yǔ)的詞頻,然后根據(jù)詞頻來構(gòu)建Huffman樹,如圖7所示,樹的根節(jié)點(diǎn)可理解為輸入詞的詞向量,葉子節(jié)點(diǎn)表示詞表中的詞,其它節(jié)點(diǎn)沒有什么實(shí)際含義,僅起到輔助作用。

Fig.7. Huffman樹
為什么使用Huffman樹可以加快訓(xùn)練速度?答案是輸出層不使用one-hot來表示,softmax回歸就不需要對(duì)那么多0(也即負(fù)樣本)進(jìn)行擬合,僅僅只需要擬合輸出值在Huffman樹中的一條路徑。假設(shè)詞表大小為N,一條路徑上節(jié)點(diǎn)的個(gè)數(shù)可以用log(N)來估計(jì),就是說只需要擬合log(N)次,這給計(jì)算量帶來了指數(shù)級(jí)的減少。此外,由于Huffman編碼是不等長(zhǎng)編碼,頻率越高的詞越接近根節(jié)點(diǎn),這也使計(jì)算量有所降低。
怎么對(duì)樹中的節(jié)點(diǎn)進(jìn)行擬合呢?如圖7所示,假設(shè)訓(xùn)練樣本的輸出詞是w2,則從根節(jié)點(diǎn)走到w2經(jīng)過了nw2,2, n(w2,3)這兩個(gè)節(jié)點(diǎn)。由于Huffman樹是二叉樹,這意味著只需要判斷向左還是向右就可以從根節(jié)點(diǎn)走到w2,判斷向左還是向右其實(shí)就是進(jìn)行二分類。圖7中的例子,“root(input)->left->left->right(w2)”這條路徑的概率可表示為:
- Pw2input=Pleftinput∙Pleftinput∙Prightinput
- =logistic(θ1∙Xinput)∙logistic(θ2∙Xinput)∙1-logistic(θ3∙Xinput)
- logisticx= 11+e-x
其中θi表示路徑中第i個(gè)節(jié)點(diǎn)的權(quán)值向量。注意一點(diǎn),softmax regression 做二分類的時(shí)候就退化為了logistic regression,因此雖然叫層次softmax但公式中其實(shí)用的是logistic function。根據(jù)上述公式就可構(gòu)建根據(jù)Huffman樹來進(jìn)行softmax回歸的cost function,進(jìn)而根據(jù)梯度下降對(duì)模型進(jìn)行訓(xùn)練求解。
4. word2vec應(yīng)用
Google開源了word2vec源碼,可以很方便的訓(xùn)練詞向量,這里不再贅述。簡(jiǎn)單看個(gè)例子:

可以看出,當(dāng)輸入北京這個(gè)詞時(shí),與之相似的詞語(yǔ)有“上海、廣州、杭州、深圳…”,模型幾乎學(xué)習(xí)到了一線城市的概念,效果還是可以的。
4.1 達(dá)觀應(yīng)用案例
特征降維:特征維度過高的時(shí)候,很容易出現(xiàn)特征之間具有較高的相關(guān)性。這種情況下可以利用詞向量工具對(duì)特征進(jìn)行聚類,將相關(guān)的特征歸到一個(gè)維度里面。
特征擴(kuò)展:針對(duì)短文本處理時(shí),一個(gè)case往往提不出很多表意較強(qiáng)的特征,導(dǎo)致類別間區(qū)分度不強(qiáng)。這種情況下可以利用詞向量工具對(duì)主要特征進(jìn)行擴(kuò)展,在不損失精度的前提下提高召回。
5. 總結(jié)
本文從例子出發(fā),簡(jiǎn)單介紹了Word2vec的skip-gram模型,只作拋磚引玉。由于作者水平限制,文中難免有不當(dāng)之處,歡迎指正。
【本文為51CTO專欄作者“達(dá)觀數(shù)據(jù)”的原創(chuàng)稿件,轉(zhuǎn)載可通過51CTO專欄獲取聯(lián)系】