CVPR 2017論文解讀:Instance-Aware圖像語義分割
本屆 CVPR 2017大會上出現了很多值得關注的精彩論文,國內自動駕駛創業公司 Momenta 聯合機器之心推出 CVPR 2017 精彩論文解讀專欄,本文是此系列專欄的第五篇,介紹了清華大學與微軟的論文《Fully Convolutional Instance-aware Semantic Segmentation》,作者為 Momenta 高級研發工程師梁繼。

論文鏈接:https://arxiv.org/pdf/1611.07709.pdf
自從 FCN(Fully Convolutional Networks for Semantic Segmentation)一文將全卷積,端到端的訓練框架應用在了圖像分割領域,這種高效的模式被廣泛應用在了大多數的語義分割任務(semantic segment)中。它在網絡結構中只使用卷積操作,輸出結果的通道個數和待分類的類別個數相同。后接一個 softmax 操作來實現每個像素的類別訓練。
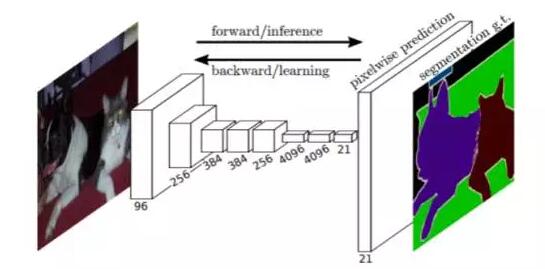
物體分割(instance aware segment)有別于語義分割。在語義分割中,同一類的物體并不區分彼此,而是統一標記為同一類。但物體分割需要區分每一個獨立的個體。

上圖的示例可以看出兩個任務的區別。左圖中的五只羊,在語義分割任務中(中圖),被賦予了同一種類別標簽。而在物體分割中(右圖),每只羊都被賦予了不同的類別。
在一張圖像中,待分割的物體個數是不定的,每個物體標記一個類別的話,這張圖像的類別個數也是不定的,導致輸出的通道個數也無法保持恒定,所以不能直接套用 FCN 的端到端訓練框架。
因此,一個直接的想法是,先得到每個物體的檢測框,在每個檢測框內,再去提取物體的分割結果。這樣可以避免類別個數不定的問題。比如,在 faster rcnn 的框架中,提取 ROI 之后,對每個 ROI 區域多加一路物體分割的分支。
這種方法雖然可行,但留有一個潛在的問題:label 的不穩定。想象一下有兩個人(A,B)離得很近,以至于每個人的檢測框都不得不包含一些另一個人的區域。當我們關注 A 時,B 被引入的部分會標記為背景;相反當我們關注 B 時,這部分會被標記為前景。
為了解決上述問題,本文引用了一種 Instance-sensitive score maps 的方法(首先在 Instance-sensitive Fully Convolutional Networks 一文中被提出),簡單卻有效的實現了端到端的物體分割訓練。
具體的作法是:
將一個 object 的候選框分為 NxN 的格子,每個格子的 feature 來自不同通道的 feature map。
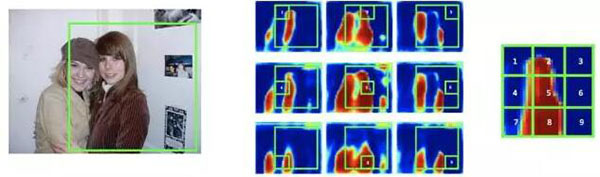
以上圖為例,可以認為,將物體分割的輸出分成了 9 個 channel,分別學習 object 的左上,上,右上,….. 右下等 9 個邊界。
這種改變將物體從一個整體打散成為 9 個部分,從而在任何一張 feature map 上,兩個相鄰的物體的 label 不再連在一起(feature map 1 代表物體的左上邊界,可以看到兩個人的左上邊界并沒有連在一起),因此,在每張 feature map 上,兩人都是可區分的。
打個比喻,假設本來我們只有一個 person 類別,兩個人如果肩并肩緊挨著站在一起,則無法區分彼此。如果我們劃分了左手,右手,中心軀干等三個類別,用三張獨立的 feature map 代表。那么在每張 feature map 上兩個人都是可區分的。當我們需要判斷某個候選框內有沒有人時,只需要對應的去左手,右手,中心軀干的 feature map 上分別去對應的區域拼在一起,看能不能拼成一個完整的人體即可。
借用這個方法,本文提出了一個物體分割端到端訓練的框架,如上圖所示,使用 region proposal 網絡提供物體分割的 ROI,對每個 ROI 區域,應用上述方法,得到物體分割的結果。
文章中還有一些具體的訓練細節,不過這里不再占用篇幅贅述。本文***的價值在于,***個提出了在物體分割中可以端到端訓練的框架,是繼 FCN 之后分割領域的又一個重要進展。
Q&A
1 文中將物體劃分為 NxN 的格子,這種人為規則是否有不適用的情況?
A:目前還沒有發現不適用的情況。對于硬性劃分帶來的潛在問題,可以考慮一些 soft 分格的方法。
2 是否考慮去掉 rpn 提取 proposal 的步驟,直接在整圖上做 multi class 的 instance aware segment?
A:這也是我們要嘗試實現的。
3 instance aware segment 目前主要的應用場景是什么?
A:不清楚。留給做應用開發的人去發掘。
【本文是51CTO專欄機構“機器之心”的原創文章,微信公眾號“機器之心( id: almosthuman2014)”】