CVPR 2017最佳論文解讀:密集連接卷積網絡
此系列專欄的***篇文章《CVPR 2017論文解讀:用于單目圖像車輛3D檢測的多任務網絡》
此系列專欄的第二篇文章《CVPR 2017論文解讀:特征金字塔網絡FPN》
日前,CVPR 2017獲獎論文公布,其中一篇***論文為康奈爾大學、清華大學、Facebook FAIR 實驗室合著的《Densely Connected Convolutional Networks》。在這篇文章中,Momenta 高級研發工程師胡杰對這篇文章進行了解讀。此文為該系列專欄的第三篇。
近幾年來,隨著卷積神經網絡(CNNs)的迅速發展,學術界涌現出一大批非常高效的模型,如 GoogleNet、VGGNet、ResNet 等,在各種計算機視覺任務上均嶄露頭角。但隨著網絡層數的加深,網絡在訓練過程中的前傳信號和梯度信號在經過很多層之后可能會逐漸消失。先前有一些非常好的工作來解決這一問題。如在 Highway 和 ResNet 結構中均提出了一種數據旁路(skip-layer)的技術來使得信號可以在輸入層和輸出層之間高速流通,核心思想都是創建了一個跨層連接來連通網路中前后層。在本文中,作者基于這個核心理念設計了一種全新的連接模式。為了***化網絡中所有層之間的信息流,作者將網絡中的所有層兩兩都進行了連接,使得網絡中每一層都接受它前面所有層的特征作為輸入。由于網絡中存在著大量密集的連接,作者將這種網絡結構稱為 DenseNet。其結構示意圖如下左圖所示:

它主要擁有以下兩個特性:1)一定程度上減輕在訓練過程中梯度消散的問題。因為從上左圖我們可以看出,在反傳時每一層都會接受其后所有層的梯度信號,所以不會隨著網絡深度的增加,靠近輸入層的梯度會變得越來越小。2)由于大量的特征被復用,使得使用少量的卷積核就可以生成大量的特征,最終模型的尺寸也比較小。
上右圖所示的是構成 DenseNet 的單元模塊,看上去和 ResNet 的單元模塊非常相似,但實際上差異較大。我對結構設計上的細節進行了以下總結:
1)為了進行特征復用,在跨層連接時使用的是在特征維度上的 Concatenate 操作,而不是 Element-wise Addition 操作。
2)由于不需要進行 Elewise-wise 操作,所以在每個單元模塊的***不需要一個 1X1 的卷積來將特征層數升維到和輸入的特征維度一致。
3)采用 Pre-activation 的策略來設計單元,將 BN 操作從主支上移到分支之前。(BN->ReLU->1x1Conv->BN->ReLU->3x3Conv)
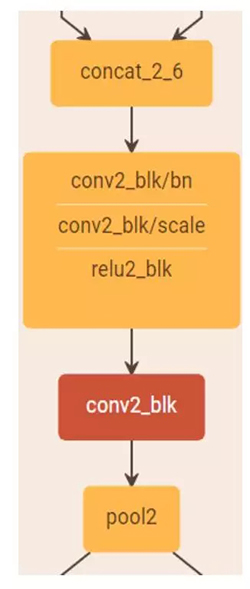
4)由于網絡中每層都接受前面所有層的特征作為輸入,為了避免隨著網絡層數的增加,后面層的特征維度增長過快,在每個階段之后進行下采樣的時候,首先通過一個卷積層將特征維度壓縮至當前輸入的一半,然后再進行 Pooling 的操作。如下圖所示:
5)增長率的設置。增長率指的是每個單元模塊***那個 3x3 的卷積核的數量,記為 k。由于每個單元模塊***是以 Concatenate 的方式來進行連接的,所以每經過一個單元模塊,下一層的特征維度就會增長 k。它的值越大意味著在網絡中流通的信息也越大,相應地網絡的能力也越強,但是整個模型的尺寸和計算量也會變大。作者在本文中使用了 k=32 和 k=48 兩種設置。
作者基于以上原則針對于 ImageNet 物體識別任務分別設計了 DesNet-121(k=32)、DesNet-169(k=32)、DesNet-201(k=32) 和 DesNet-161(k=48) 四種網絡結構。其網絡的組織形式和 ResNet 類似,也是分為 4 個階段,將原先的 ResNet 的單元模塊進行了替換,下采樣過程略有不同。整體結構設計如下所示:

在 ImageNet 上的實驗結果如下:
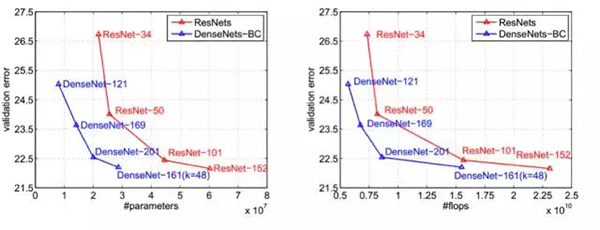
上左圖表示的是參數量和錯誤率的關系,上右圖表示的是模型測試的計算量和錯誤率的關系。我們不難看出,在達到相同精度時,DenseNet 的參數量和計算量均為 ResNet 的一半左右。
總的來說,這是一篇非常有創新性的工作,提出了共享特征、任意層間互連的概念很大程度上減輕了深層網絡在訓練過程中梯度消散而難以優化的問題,同時也減小了模型的尺寸和計算量,在標準數據集上獲得了非常好的性能。唯一可能的不足是網絡不能設計地特別「深」,因為隨著 DenseNet 網絡層數的增加,模型的特征維度會線性增長,使得在訓練過程中的計算量和顯存開銷也會爆發地增長。
Q&A:
1.DenseNet 是否可以在物體檢測任務中使用?效果如何?
A:當然,DenseNet 可以通過和 ResNet 一樣的方法被應用到物體檢測任務中。但是作者并沒有在物體檢測任務上進行實驗,如果關注 DenseNet 在物體檢測任務上的效果,可以參考第三方的將 DenseNet 用在物體檢測任務上的實驗結果。
2.通過圖表可以看到,DenseNet 在相對較小計算量和相對較小的模型大小的情況下,相比同等規模的 ResNet 的準確率提升會更明顯。是否說明 DenseNet 結構更加適合小模型的設計?
A:確實,在小模型的場景下 DenseNet 有更大的優勢。同時,作者也和近期發表的 MobileNet 這一針對移動端和小模型設計的工作進行了對比,結果顯示 DenseNet(~400MFlops)可以在更小的計算量的情況下取得比 MobileNet(~500MFlops)更高的 ImageNet 分類準確率。
3.DenseNet 中非常關鍵的連續的跨層 Concatenate 操作僅存在于每個 Dense Block 之內,不同 Dense Block 之間則沒有這種操作,是怎樣一種考慮?
A:事實上,每個 Dense Block ***的特征圖已經將當前 Block 內所有的卷積模塊的輸出拼接在一起,整體經過降采樣之后送入了下一個 Dense Block,其中已經包含了這個 Dense Block 的全部信息,這樣做也是一種權衡。
4.DenseNet 這樣的模型結構在訓練過程中是否有一些技巧?
A:訓練過程采用了和 ResNet 的文章完全相同的設定。但仍然存在一些技巧,例如因為多次 Concatenate 操作,同樣的數據在網絡中會存在多個復制,這里需要采用一些顯存優化技術,使得訓練時的顯存占用可以隨著層數線性增加,而非增加的更快,相關代碼會在近期公布。
【本文是51CTO專欄機構“機器之心”的原創文章,微信公眾號“機器之心( id: almosthuman2014)”】