













如何用PyTorch進(jìn)行語義分割?一文搞定
很久沒給大家?guī)斫坛藤Y源啦。
正值PyTorch 1.7更新,那么我們這次便給大家?guī)硪粋€(gè)PyTorch簡(jiǎn)單實(shí)用的教程資源:用PyTorch進(jìn)行語義分割。
圖源:stanford
該教程是基于2020年ECCV Vipriors Chalange Start Code實(shí)現(xiàn)了語義分割,并且添加了一些技巧。
友情提示:教程中的所有文件均可以在文末的開源地址獲取。
預(yù)設(shè)置
在開始訓(xùn)練之前,得首先設(shè)置一下庫(kù)、數(shù)據(jù)集等。
庫(kù)準(zhǔn)備
- pip install -r requirements.txt
下載數(shù)據(jù)集
教程使用的是來自Cityscapes的數(shù)據(jù)集MiniCity Dataset。
數(shù)據(jù)集的簡(jiǎn)單數(shù)據(jù)分析
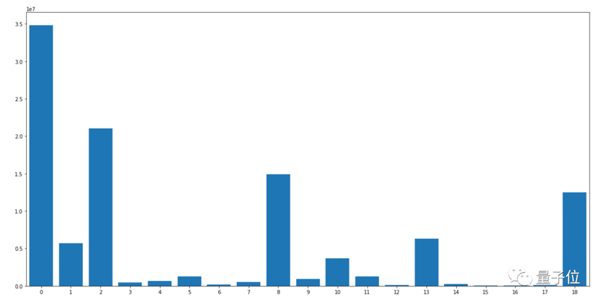
將各基準(zhǔn)類別進(jìn)行輸入:

之后,便從0-18計(jì)數(shù),對(duì)各類別進(jìn)行像素標(biāo)記:
使用deeplab v3進(jìn)行基線測(cè)試,結(jié)果發(fā)現(xiàn)次要類別的IoU特別低,這樣會(huì)導(dǎo)致難以跟背景進(jìn)行區(qū)分。
如下圖中所示的墻、柵欄、公共汽車、火車等。
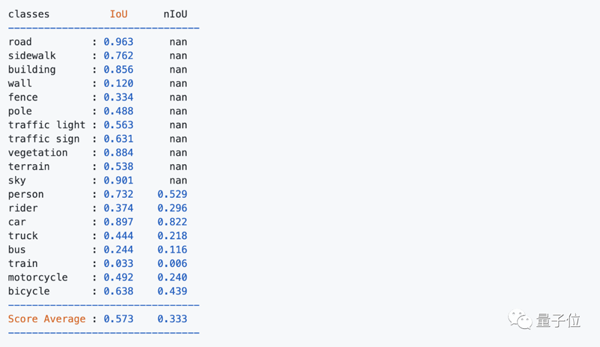
分析結(jié)論:數(shù)據(jù)集存在嚴(yán)重的類別不平衡問題。
訓(xùn)練基準(zhǔn)模型
使用來自torchvision的DeepLabV3進(jìn)行訓(xùn)練。
硬件為4個(gè)RTX 2080 Ti GPU (11GB x 4),如果只有1個(gè)GPU或較小的GPU內(nèi)存,請(qǐng)使用較小的批處理大小(< = 8)。
- python baseline.py --save_path baseline_run_deeplabv3_resnet50 --crop_size 576 1152 --batch_size 8;
- python baseline.py --save_path baseline_run_deeplabv3_resnet101 --model DeepLabv3_resnet101 --train_size 512 1024 --test_size 512 1024 --crop_size 384 768 --batch_size 8;
損失函數(shù)
有3種損失函數(shù)可供選擇,分別是:交叉熵?fù)p失函數(shù)(Cross-Entropy Loss)、類別加權(quán)交叉熵?fù)p失函數(shù)(Class-Weighted Cross Entropy Loss)和焦點(diǎn)損失函數(shù)(Focal Loss)。
交叉熵?fù)p失函數(shù),常用在大多數(shù)語義分割場(chǎng)景,但它有一個(gè)明顯的缺點(diǎn),那就是對(duì)于只用分割前景和背景的時(shí)候,當(dāng)前景像素的數(shù)量遠(yuǎn)遠(yuǎn)小于背景像素的數(shù)量時(shí),模型嚴(yán)重偏向背景,導(dǎo)致效果不好。
- # Cross Entropy Loss
- python baseline.py --save_path baseline_run_deeplabv3_resnet50 --crop_size 576 1152 --batch_size 8;
類別加權(quán)交叉熵?fù)p失函數(shù)是在交叉熵?fù)p失函數(shù)的基礎(chǔ)上為每一個(gè)類別添加了一個(gè)權(quán)重參數(shù),使其在樣本數(shù)量不均衡的情況下可以獲得更好的效果。
- # Weighted Cross Entropy Loss
- python baseline.py --save_path baseline_run_deeplabv3_resnet50_wce --crop_size 576 1152 --batch_size 8 --loss weighted_ce;
焦點(diǎn)損失函數(shù)則更進(jìn)一步,用來解決難易樣本數(shù)量不平衡。
- # Focal Loss
- python baseline.py --save_path baseline_run_deeplabv3_resnet50_focal --crop_size 576 1152 --batch_size 8 --loss focal --focal_gamma 2.0;
歸一化層
有4種歸一化方法:BN(Batch Normalization)、IN(Instance Normalization)、GN(Group Normalization)和EvoNorm(Evolving Normalization)。
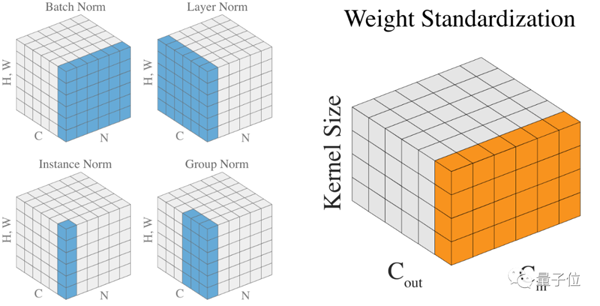
BN是在batch上,對(duì)N、H、W做歸一化,而保留通道 C 的維度。BN對(duì)較小的batch size效果不好。
- # Batch Normalization
- python baseline.py --save_path baseline_run_deeplabv3_resnet50 --crop_size 576 1152 --batch_size 8;
IN在圖像像素上,對(duì)H、W做歸一化,用在風(fēng)格化遷移。
- # Instance Normalization
- python baseline.py --save_path baseline_run_deeplabv3_resnet50_instancenorm --crop_size 576 1152 --batch_size 8 --norm instance;
GN將通道分組,然后再做歸一化。
- # Group Normalization
- python baseline.py --save_path baseline_run_deeplabv3_resnet50_groupnorm --crop_size 576 1152 --batch_size 8 --norm group;
EvoNorm則是4月份由谷歌和DeepMind 聯(lián)合發(fā)布的一項(xiàng)新技術(shù)。實(shí)驗(yàn)證明,EvoNorms 在多個(gè)圖像分類模型上效果顯著,而且還能很好地遷移到 Mask R-CNN 模型和 BigGAN。
- # Evolving Normalization
- python baseline.py --save_path baseline_run_deeplabv3_resnet50_evonorm --crop_size 576 1152 --batch_size 8 --norm evo;
數(shù)據(jù)增強(qiáng)
2種數(shù)據(jù)增強(qiáng)技術(shù):CutMix、Copy Blob。
- CutMix
將一部分區(qū)域cut掉但不填充0像素,而是隨機(jī)填充訓(xùn)練集中的其他數(shù)據(jù)的區(qū)域像素值,分類結(jié)果按一定的比例分配。
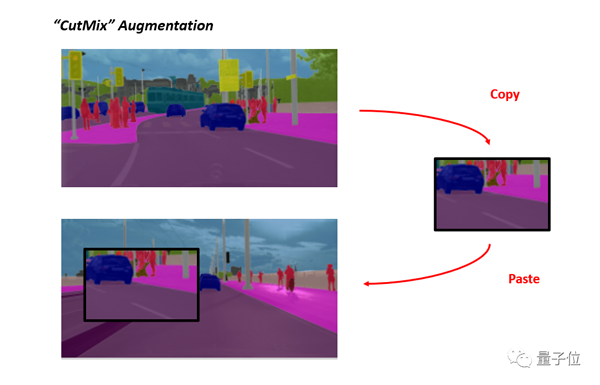
而在這里,則是在原有CutMix的基礎(chǔ)上,引入了語義分割。
- # CutMix Augmentation
- python baseline.py --save_path baseline_run_deeplabv3_resnet50_cutmix --crop_size 576 1152 --batch_size 8 --cutmix;
- Copy Blob
在 Blob 存儲(chǔ)的基礎(chǔ)上構(gòu)建,并通過Copy的方式增強(qiáng)了性能。
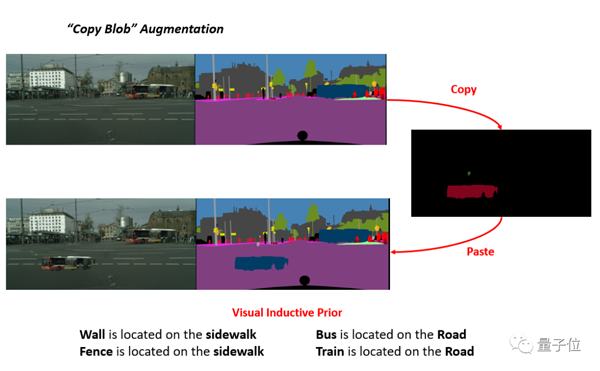
另外,如果要解決前面所提到的類別不平衡問題,則可以使用視覺歸納優(yōu)先的CopyBlob進(jìn)行增強(qiáng)。
- # CopyBlob Augmentation
- python baseline.py --save_path baseline_run_deeplabv3_resnet50_copyblob --crop_size 576 1152 --batch_size 8 --copyblob;
推理
訓(xùn)練結(jié)束后,對(duì)訓(xùn)練完成的模型進(jìn)行評(píng)估。
- python baseline.py --save_path baseline_run_deeplabv3_resnet50 --batch_size 4 --predict;
多尺度推斷
使用[0.5,0.75,1.0,1.25,1.5,1.75,2.0,2.2]進(jìn)行多尺度推理。另外,使用H-Flip,同時(shí)必須使用單一批次。
- # Multi-Scale Inference
- python baseline.py --save_path baseline_run_deeplabv3_resnet50 --batch_size 1 --predict --mst;
使用驗(yàn)證集計(jì)算度量
計(jì)算指標(biāo)并將結(jié)果保存到results.txt中。
- python evaluate.py --results baseline_run_deeplabv3_resnet50/results_val --batch_size 1 --predict --mst;
最終結(jié)果
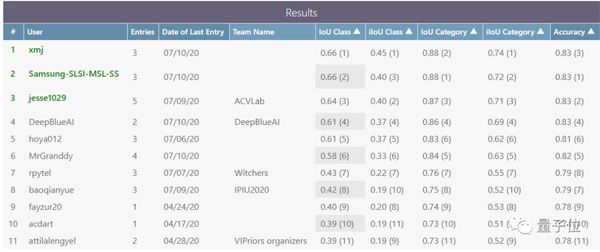
最后的單一模型結(jié)果是0.6069831962012341,
如果使用了更大的模型或者更大的網(wǎng)絡(luò)結(jié)構(gòu),性能可能會(huì)有所提高。
另外,如果使用了各種集成模型,性能也會(huì)有所提高。


















