如何在Java中構建神經網絡
譯文譯者 | 李睿
審校 | 重樓
人工神經網絡是深度學習的一種形式,也是現代人工智能的支柱之一。用戶真正掌握其工作原理的最佳方法是自己構建一個人工神經網絡。本文將介紹如何用Java構建和訓練神經網絡。
感興趣的用戶可以查閱軟件架構師Matthew Tyson以前撰寫的名為《機器學習的風格:神經網絡簡介》文章,以了解人工神經網絡如何運行的概述。本文中的示例將不是一個生產等級的系統,與其相反,它在一個易于理解的演示例子中展示了所有的主要組件。
一個基本的神經網絡
神經網絡是一種稱為神經元(Neuron)的節點圖。神經元是計算的基本單位。它接收輸入并使用每個輸入的權重、每個節點的偏差和最終函數處理器(其名稱為激活函數)算法處理它們。例如圖1所示的雙輸入神經元。
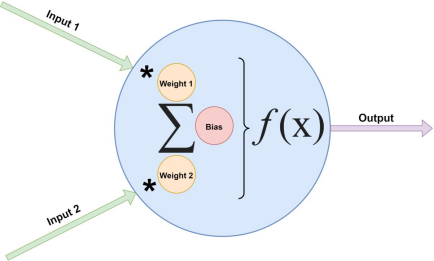
圖1 神經網絡中的雙輸入神經元
這個模型具有廣泛的可變性,將在下面演示的例子中使用這個精確的配置。
第一步是建立一個神經元類模型,該類將保持這些值。可以在清單1中看到神經元類。需要注意的是,這是該類的第一個版本。它將隨著添加的功能而改變。
清單1.簡單的神經元類
class Neuron {
Random random = new Random();
private Double bias = random.nextDouble(-1, 1);
public Double weight1 = random.nextDouble(-1, 1);
private Double weight2 = random.nextDouble(-1, 1);
public double compute(double input1, double input2){
double preActivation = (this.weight1 * input1) + (this.weight2 * input2) + this.bias;
double output = Util.sigmoid(preActivation);
return output;
}
}可以看到神經元(Neuron)類非常簡單,有三個成員:bias、weight1和weight2。每個成員被初始化為-1到1之間的隨機雙精度。
當計算神經元的輸出時,遵循圖1所示的算法:將每個輸入乘以其權重,再加上偏差:input1 * weight1 + input2 * weight2 + biass。這提供了通過激活函數運行的未處理計算(即預激活)。在本例中,使用Sigmoid激活函數,它將值壓縮到-1到1的范圍內。清單2顯示了Util.sigmoid()靜態方法。
清單2.Sigmoid激活函數
public class Util {
public static double sigmoid(double in){
return 1 / (1 + Math.exp(-in));
}
}現在已經了解了神經元是如何工作的,可以把一些神經元放到一個網絡中。然后將使用帶有神經元列表的Network類,如清單3所示。
清單3.神經網絡類
class Network {
List<Neuron> neurons = Arrays.asList(
new Neuron(), new Neuron(), new Neuron(), /* input nodes */
new Neuron(), new Neuron(), /* hidden nodes */
new Neuron()); /* output node */
}
}雖然神經元的列表是一維的,但將在使用過程中將它們連接起來,使它們形成一個網絡。前三個神經元是輸入,第二個和第三個是隱藏的,最后一個是輸出節點。
進行預測
現在,使用這個網絡來做一個預測。將使用兩個輸入整數的簡單數據集和0到1的答案格式。這個例子使用體重-身高組合來猜測某人的性別,這是基于這樣的假設,即體重和身高越高,則表明某人是男性。可以對任何兩個因素使用相同的公式,即單輸出概率。可以將輸入視為一個向量,因此神經元的整體功能將向量轉換為標量值。
網絡的預測階段如清單4所示。
清單4.網絡預測
public Double predict(Integer input1, Integer input2){
return neurons.get(5).compute(
neurons.get(4).compute(
neurons.get(2).compute(input1, input2),
neurons.get(1).compute(input1, input2)
),
neurons.get(3).compute(
neurons.get(1).compute(input1, input2),
neurons.get(0).compute(input1, input2)
)
);
}清單4顯示了將兩個輸入饋入到前三個神經元,然后將前三個神經元的輸出饋入到神經元4和5,神經元4和5又饋入到輸出神經元。這個過程被稱為前饋。
現在,可以要求網絡進行預測,如清單5所示。
清單5.獲取預測
Network network = new Network();
Double prediction = network.predict(Arrays.asList(115, 66));
System.out.println(“prediction: “ + prediction);在這里肯定會得到一些結果,但這是隨機權重和偏差的結果。為了進行真正的預測,首先需要訓練網絡。
訓練網絡
訓練神經網絡遵循一個稱為反向傳播的過程。反向傳播基本上是通過網絡向后推動更改,使輸出向期望的目標移動。
可以使用函數微分進行反向傳播,但在這個例子中,需要做一些不同的事情,將賦予每個神經元“變異”的能力。在每一輪訓練(稱為epoch)中,選擇一個不同的神經元對其屬性之一(weight1,weight2或bias)進行小的隨機調整,然后檢查結果是否有所改善。如果結果有所改善,將使用remember()方法保留該更改。如果結果惡化,將使用forget()方法放棄更改。
添加類成員(舊版本的權重和偏差)來跟蹤變化。可以在清單6中看到mutate()、remember()和forget()方法。
清單6.Mutate(),remember(),forget()
public class Neuron() {
private Double oldBias = random.nextDouble(-1, 1), bias = random.nextDouble(-1, 1);
public Double oldWeight1 = random.nextDouble(-1, 1), weight1 = random.nextDouble(-1, 1);
private Double oldWeight2 = random.nextDouble(-1, 1), weight2 = random.nextDouble(-1, 1);
public void mutate(){
int propertyToChange = random.nextInt(0, 3);
Double changeFactor = random.nextDouble(-1, 1);
if (propertyToChange == 0){
this.bias += changeFactor;
} else if (propertyToChange == 1){
this.weight1 += changeFactor;
} else {
this.weight2 += changeFactor;
};
}
public void forget(){
bias = oldBias;
weight1 = oldWeight1;
weight2 = oldWeight2;
}
public void remember(){
oldBias = bias;
oldWeight1 = weight1;
oldWeight2 = weight2;
}
}非常簡單:mutate()方法隨機選擇一個屬性,隨機選擇-1到1之間的值,然后更改該屬性。forget()方法將更改滾回舊值。remember()方法將新值復制到緩沖區。
現在,為了利用神經元的新功能,我們向Network添加了一個train()方法,如清單7所示。
清單7.Network.train()方法
public void train(List<List<Integer>> data, List<Double> answers){
Double bestEpochLoss = null;
for (int epoch = 0; epoch < 1000; epoch++){
// adapt neuron
Neuron epochNeuron = neurons.get(epoch % 6);
epochNeuron.mutate(this.learnFactor);
List<Double> predictions = new ArrayList<Double>();
for (int i = 0; i < data.size(); i++){
predictions.add(i, this.predict(data.get(i).get(0), data.get(i).get(1)));
}
Double thisEpochLoss = Util.meanSquareLoss(answers, predictions);
if (bestEpochLoss == null){
bestEpochLoss = thisEpochLoss;
epochNeuron.remember();
} else {
if (thisEpochLoss < bestEpochLoss){
bestEpochLoss = thisEpochLoss;
epochNeuron.remember();
} else {
epochNeuron.forget();
}
}
}train()方法對數據重復1000次,并在參數中保留回答列表。這些是同樣大小的訓練集;數據保存輸入值,答案保存已知的良好答案。然后,該方法遍歷這些答案,并得到一個值,表明網絡猜測的結果與已知的正確答案相比的正確率。然后,它會讓一個隨機的神經元發生突變,如果新的測試表明這是一個更好的預測,它就會保持這種變化。
檢查結果
可以使用均方誤差(MSE)公式來檢查結果,這是一種在神經網絡中測試一組結果的常用方法。可以在清單8中看到MSE函數。
清單8.均方誤差函數
public static Double meanSquareLoss(List<Double> correctAnswers, List<Double> predictedAnswers){
double sumSquare = 0;
for (int i = 0; i < correctAnswers.size(); i++){
double error = correctAnswers.get(i) - predictedAnswers.get(i);
sumSquare += (error * error);
}
return sumSquare / (correctAnswers.size());
}微調系統
現在剩下的就是把一些訓練數據輸入網絡,并用更多的預測來嘗試。清單9顯示了如何提供訓練數據。
清單9.訓練數據
List<List<Integer>> data = new ArrayList<List<Integer>>();
data.add(Arrays.asList(115, 66));
data.add(Arrays.asList(175, 78));
data.add(Arrays.asList(205, 72));
data.add(Arrays.asList(120, 67));
List<Double> answers = Arrays.asList(1.0,0.0,0.0,1.0);
Network network = new Network();
network.train(data, answers);在清單9中,訓練數據是一個二維整數集列表(可以把它們看作體重和身高),然后是一個答案列表(1.0表示女性,0.0表示男性)。
如果在訓練算法中添加一些日志記錄,運行它將得到類似清單10的輸出。
清單10.記錄訓練器
// Logging:
if (epoch % 10 == 0) System.out.println(String.format("Epoch: %s | bestEpochLoss: %.15f | thisEpochLoss: %.15f", epoch, bestEpochLoss, thisEpochLoss));
// output:
Epoch: 910 | bestEpochLoss: 0.034404863820424 | thisEpochLoss: 0.034437939546120
Epoch: 920 | bestEpochLoss: 0.033875954196897 | thisEpochLoss: 0.431451026477016
Epoch: 930 | bestEpochLoss: 0.032509260025490 | thisEpochLoss: 0.032509260025490
Epoch: 940 | bestEpochLoss: 0.003092720117159 | thisEpochLoss: 0.003098025397281
Epoch: 950 | bestEpochLoss: 0.002990128276146 | thisEpochLoss: 0.431062364628853
Epoch: 960 | bestEpochLoss: 0.001651762688346 | thisEpochLoss: 0.001651762688346
Epoch: 970 | bestEpochLoss: 0.001637709485751 | thisEpochLoss: 0.001636810460399
Epoch: 980 | bestEpochLoss: 0.001083365453009 | thisEpochLoss: 0.391527869500699
Epoch: 990 | bestEpochLoss: 0.001078338540452 | thisEpochLoss: 0.001078338540452清單10顯示了損失(誤差偏離正右側)緩慢下降;也就是說,它越來越接近做出準確的預測。剩下的就是看看模型對真實數據的預測效果如何,如清單11所示。
清單11.預測
System.out.println("");
System.out.println(String.format(" male, 167, 73: %.10f", network.predict(167, 73)));
System.out.println(String.format("female, 105, 67: %.10", network.predict(105, 67)));
System.out.println(String.format("female, 120, 72: %.10f | network1000: %.10f", network.predict(120, 72)));
System.out.println(String.format(" male, 143, 67: %.10f | network1000: %.10f", network.predict(143, 67)));
System.out.println(String.format(" male', 130, 66: %.10f | network: %.10f", network.predict(130, 66)));在清單11中,將訓練好的網絡輸入一些數據,輸出預測結果。結果如清單12所示。
清單12.訓練有素的預測
male, 167, 73: 0.0279697143
female, 105, 67: 0.9075809407
female, 120, 72: 0.9075808235
male, 143, 67: 0.0305401413
male, 130, 66: network: 0.9009811922在清單12中,看到網絡對大多數值對(又名向量)都做得很好。它給女性數據集的估計值約為0.907,非常接近1。兩名男性顯示0.027和0.030接近0。離群的男性數據集(130,67)被認為可能是女性,但可信度較低,為0.900。
結論
有多種方法可以調整這一系統上的參數。首先,訓練運行中的epoch數是一個主要因素。epoch越多,其模型就越適合數據。運行更多的epoch可以提高符合訓練集的實時數據的準確性,但也會導致過度訓練。也就是說,這是一個在邊緣情況下自信地預測錯誤結果的模型。
文章標題:How to build a neural network in Java,作者:Matthew Tyson