自創數據集,用TensorFlow預測股票教程
STATWORX 團隊近日從 Google Finance API 中精選出了 S&P 500 數據,該數據集包含 S&P 500 的指數和股價信息。有了這些數據,他們就希望能利用深度學習模型和 500 支成分股價預測 S&P 500 指數。STATWORX 團隊的數據集十分新穎,但只是利用四個隱藏層的全連接網絡實現預測,讀者也可以下載該數據嘗試更加優秀的循環神經網絡。
本文非常適合初學者了解如何使用 TensorFlow 構建基本的神經網絡,它全面展示了構建一個 TensorFlow 模型所涉及的概念與模塊。本文所使用的數據集可以直接下載,所以有一定基礎的讀者也可以嘗試使用更強的循環神經網絡處理這一類時序數據。
數據集地址:http://files.statworx.com/sp500.zip
導入和預處理數據
STATWORX 團隊從服務器爬取股票數據,并將它們保存為 csv 格式的文件。該數據集包含 n=41266 分鐘的記錄,范圍從 2017 年的 4 月到 8 月的 500 支股票和 S&P 500 指數,股票和股指的范圍分布十分廣。
- # Import data
- data = pd.read_csv('data_stocks.csv')
- # Dimensions of dataset
- n = data.shape[0]
- p = data.shape[1]
該數據集已經經過了清理與預處理,即損失的股票和股指都通過 LOCF’ed 處理(下一個觀測數據復制前面的),所以該數據集沒有任何缺損值。
我們可以使用 pyplot.plot(‘SP500’) 語句繪出 S&P 時序數據。

S&P 500 股指時序繪圖
- 預備訓練和測試數據
該數據集需要被分割為訓練和測試數據,訓練數據包含總數據集 80% 的記錄。該數據集并不需要擾亂而只需要序列地進行切片。訓練數據可以從 2017 年 4 月選取到 2017 年 7 月底,而測試數據再選取剩下到 2017 年 8 月的數據。
- # Training and test data
- train_start = 0
- train_end = int(np.floor(0.8*n))
- test_start = train_end + 1
- test_end = n
- data_train = data[np.arange(train_start, train_end), :]
- data_test = data[np.arange(test_start, test_end), :]
時序交叉驗證有很多不同的方式,例如有或沒有再擬合(refitting)而執行滾動式預測、或者如時序 bootstrap 重采樣等更加詳細的策略等。后者涉及時間序列周期性分解的重復樣本,以便模擬與原時間序列相同周期性模式的樣本,但這并不不是簡單的復制他們的值。
- 數據標準化
大多數神經網絡架構都需要標準化數據,因為 tanh 和 sigmoid 等大多數神經元的激活函數都定義在 [-1, 1] 或 [0, 1] 區間內。目前線性修正單元 ReLU 激活函數是最常用的,但它的值域有下界無上界。不過無論如何我們都應該重新縮放輸入和目標值的范圍,這對于我們使用梯度下降算法也很有幫助。縮放取值可以使用 sklearn 的 MinMaxScaler 輕松地實現。
- # Scale data
- from sklearn.preprocessing import MinMaxScaler
- scaler = MinMaxScaler()
- scaler.fit(data_train)
- scaler.transform(data_train)
- scaler.transform(data_test)
- # Build X and y
- X_train = data_train[:, 1:]
- y_train = data_train[:, 0]
- X_test = data_test[:, 1:]
- y_test = data_test[:, 0]pycharm
注意,我們必須謹慎地確定什么時候該縮放哪一部分數據。比較常見的錯誤就是在拆分測試和訓練數據集之前縮放整個數據集。因為我們在執行縮放時會涉及到計算統計數據,例如一個變量的***和最小值。但在現實世界中我們并沒有來自未來的觀測信息,所以必須對訓練數據按比例進行統計計算,并將統計結果應用于測試數據中。不然的話我們就使用了未來的時序預測信息,這常常令預測度量偏向于正向。
TensorFlow 簡介
TensorFlow 是一個十分優秀的框架,目前是深度學習和神經網絡方面用戶最多的框架。它基于 C++的底層后端,但通常通過 Python 進行控制。TensorFlow 利用強大的靜態圖表征我們需要設計的算法與運算。這種方法允許用戶指定運算為圖中的結點,并以張量的形式傳輸數據而實現高效的算法設計。由于神經網絡實際上是數據和數學運算的計算圖,所以 TensorFlow 能很好地支持神經網絡和深度學習。
總的來說,TensorFlow 是一種采用數據流圖(data flow graphs),用于數值計算的開源軟件庫。其中 Tensor 代表傳遞的數據為張量(多維數組),Flow 代表使用計算圖進行運算。數據流圖用「結點」(nodes)和「邊」(edges)組成的有向圖來描述數學運算。「結點」一般用來表示施加的數學操作,但也可以表示數據輸入的起點和輸出的終點,或者是讀取/寫入持久變量(persistent variable)的終點。邊表示結點之間的輸入/輸出關系。這些數據邊可以傳送維度可動態調整的多維數據數組,即張量(tensor)。
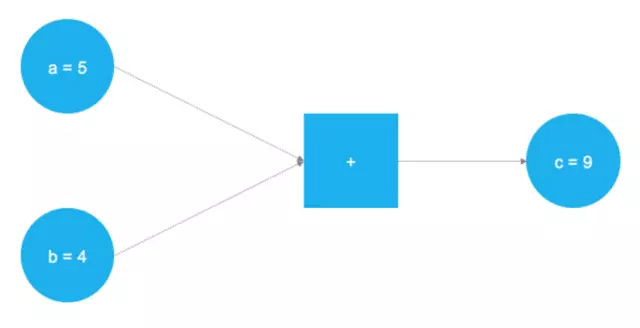
執行加法的簡單計算圖
在上圖中,兩個零維張量(標量)將執行相加任務,這兩個張量儲存在兩個變量 a 和 b 中。這兩個值流過圖形在到達正方形結點時被執行相加任務,相加的結果被儲存在變量 c 中。實際上,a、b 和 c 可以被看作占位符,任何輸入到 a 和 b 的值都將會相加到 c。這正是 TensorFlow 的基本原理,用戶可以通過占位符和變量定義模型的抽象表示,然后再用實際的數據填充占位符以產生實際的運算,下面的代碼實現了上圖簡單的計算圖:
- # Import TensorFlow
- import tensorflow as tf
- # Define a and b as placeholders
- a = tf.placeholder(dtype=tf.int8)
- b = tf.placeholder(dtype=tf.int8)
- # Define the addition
- c = tf.add(a, b)
- # Initialize the graph
- graph = tf.Session()
- # Run the graph
- graph.run(c, feed_dict{a: 5, b: 4})
如上在導入 TensorFlow 庫后,使用 tf.placeholder() 定義兩個占位符來預儲存張量 a 和 b。隨后定義運算后就能執行運算圖得出結果。
- 占位符
正如前面所提到的,神經網絡的初始源自占位符。所以現在我們先要定義兩個占位符以擬合模型,X 包含神經網絡的輸入(所有 S&P 500 在時間 T=t 的股票價格),Y 包含神經網絡的輸出(S&P 500 在時間 T=t+1 的指數值)。
因此輸入數據占位符的維度可定義為 [None, n_stocks],輸出占位符的維度為 [None],它們分別代表二維張量和一維張量。理解輸入和輸出張量的維度對于構建整個神經網絡十分重要。
- # Placeholder
- X = tf.placeholder(dtype=tf.float32, shape=[None, n_stocks])
- Y = tf.placeholder(dtype=tf.float32, shape=[None])
以上代碼中的 None 指代我們暫時不知道每個批量傳遞到神經網絡的數量,所以使用 None 可以保持靈活性。我們后面會定義控制每次訓練時使用的批量大小 batch_size。
- 變量
除了占位符,變量是 TensorFlow 表征數據和運算的另一個重要元素。雖然占位符在計算圖內通常用于儲存輸入和輸出數據,但變量在計算圖內部是非常靈活的容器,它可以在執行中進行修改與傳遞。神經網絡的權重和偏置項一般都使用變量定義,以便在訓練中可以方便地進行調整,變量需要進行初始化,后文將詳細解釋這一點。
該模型由四個隱藏層組成,***層包含 1024 個神經元,然后后面三層依次以 2 的倍數減少,即 512、256 和 128 個神經元。后面的層級的神經元依次減少就壓縮了前面層級中抽取的特征。當然,我們還能使用其它神經網絡架構和神經元配置以更好地處理數據,例如卷積神經網絡架構適合處理圖像數據、循環神經網絡適合處理時序數據,但本文只是為入門者簡要地介紹如何使用全連接網絡處理時序數據,所以那些復雜的架構本文并不會討論。
- # Model architecture parameters
- n_stocks = 500
- n_neurons_1 = 1024
- n_neurons_2 = 512
- n_neurons_3 = 256
- n_neurons_4 = 128
- n_target = 1
- # Layer 1: Variables for hidden weights and biases
- W_hidden_1 = tf.Variable(weight_initializer([n_stocks, n_neurons_1]))
- bias_hidden_1 = tf.Variable(bias_initializer([n_neurons_1]))
- # Layer 2: Variables for hidden weights and biases
- W_hidden_2 = tf.Variable(weight_initializer([n_neurons_1, n_neurons_2]))
- bias_hidden_2 = tf.Variable(bias_initializer([n_neurons_2]))
- # Layer 3: Variables for hidden weights and biases
- W_hidden_3 = tf.Variable(weight_initializer([n_neurons_2, n_neurons_3]))
- bias_hidden_3 = tf.Variable(bias_initializer([n_neurons_3]))
- # Layer 4: Variables for hidden weights and biases
- W_hidden_4 = tf.Variable(weight_initializer([n_neurons_3, n_neurons_4]))
- bias_hidden_4 = tf.Variable(bias_initializer([n_neurons_4]))
- # Output layer: Variables for output weights and biases
- W_out = tf.Variable(weight_initializer([n_neurons_4, n_target]))
- bias_out = tf.Variable(bias_initializer([n_target]))
理解輸入層、隱藏層和輸出層之間變量的維度變換對于理解整個網絡是十分重要的。作為多層感知機的一個經驗性法則,后面層級的***個維度對應于前面層級權重變量的第二個維度。這可能聽起來比較復雜,但實際上只是將每一層的輸出作為輸入傳遞給下一層。偏置項的維度等于當前層級權重的第二個維度,也等于該層中的神經元數量。
設計神經網絡的架構
在定義完神經網絡所需要的權重矩陣與偏置項向量后,我們需要指定神經網絡的拓撲結構或網絡架構。因此占位符(數據)和變量(權重和偏置項)需要組合成一個連續的矩陣乘法系統。
此外,網絡隱藏層中的每一個神經元還需要有激活函數進行非線性轉換。激活函數是網絡體系結構非常重要的組成部分,因為它們將非線性引入了系統。目前有非常多的激活函數,其中最常見的就是線性修正單元 ReLU 激活函數,本模型也將使用該激活函數。
- # Hidden layer
- hidden_1 = tf.nn.relu(tf.add(tf.matmul(X, W_hidden_1), bias_hidden_1))
- hidden_2 = tf.nn.relu(tf.add(tf.matmul(hidden_1, W_hidden_2), bias_hidden_2))
- hidden_3 = tf.nn.relu(tf.add(tf.matmul(hidden_2, W_hidden_3), bias_hidden_3))
- hidden_4 = tf.nn.relu(tf.add(tf.matmul(hidden_3, W_hidden_4), bias_hidden_4))
- # Output layer (must be transposed)
- out = tf.transpose(tf.add(tf.matmul(hidden_4, W_out), bias_out))
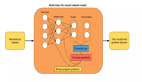
下圖將展示本文構建的神經網絡架構,該模型主要由三個構建塊組成,即輸入層、隱藏層和輸出層。這種架構被稱為前饋網絡或全連接網絡,前饋表示輸入的批量數據只會從左向右流動,其它如循環神經網絡等架構也允許數據向后流動。
前饋網絡的核心架構
- 損失函數
該網絡的損失函數主要是用于生成網絡預測與實際觀察到的訓練目標之間的偏差值。對回歸問題而言,均方誤差(MSE)函數最為常用。MSE 計算預測值與目標值之間的平均平方誤差。
- # Cost function
- mse = tf.reduce_mean(tf.squared_difference(out, Y))
然而,MSE 的特性在常見的優化問題上很有優勢。
- 優化器
優化器處理的是訓練過程中用于適應網絡權重和偏差變量的必要計算。這些計算調用梯度計算結果,指示訓練過程中,權重和偏差需要改變的方向,從而最小化網絡的代價函數。穩定、快速的優化器的開發,一直是神經網絡和深度學習領域的重要研究。
- # Optimizer
- opt = tf.train.AdamOptimizer().minimize(mse)
以上是用到了 Adam 優化器,是目前深度學習中的默認優化器。Adam 表示適應性矩估計,可被當作 AdaGrad 和 RMSProp 這兩個優化器的結合。
- 初始化器
初始化器被用于在訓練之前初始化網絡的變量。因為神經網絡是使用數值優化技術訓練的,優化問題的起點是找到好的解決方案的重點。TensorFlow 中有不同的初始化器,每個都有不同的初始化方法。在這篇文章中,我使用的是 tf.variance_scaling_initializer(),是一種默認的初始化策略。
- # Initializers
- sigma =
- weight_initializer = tf.variance_scaling_initializer(mode="fan_avg", distribution="uniform", scale=sigma)
- bias_initializer = tf.zeros_initializer()
注意,用 TensorFlow 的計算圖可以對不同的變量定義多個初始化函數。然而,在大多數情況下,一個統一的初始化函數就夠了。
擬合神經網絡
完成對網絡的占位符、變量、初始化器、代價函數和優化器的定義之后,就可以開始訓練模型了,通常會使用小批量訓練方法。在小批量訓練過程中,會從訓練數據隨機提取數量為 n=batch_size 的數據樣本饋送到網絡中。訓練數據集將分成 n/batch_size 個批量按順序饋送到網絡中。此時占位符 X 和 Y 開始起作用,它們保存輸入數據和目標數據,并在網絡中分別表示成輸入和目標。
X 的一個批量數據會在網絡中向前流動直到到達輸出層。在輸出層,TensorFlow 將會比較當前批量的模型預測和實際觀察目標 Y。然后,TensorFlow 會進行優化,使用選擇的學習方案更新網絡的參數。更新完權重和偏差之后,下一個批量被采樣并重復以上過程。這個過程將一直進行,直到所有的批量都被饋送到網絡中去,即完成了一個 epoch。
當訓練達到了 epoch 的***值或其它的用戶自定義的停止標準的時候,網絡的訓練就會停止。
- # Run initializer
- net.run(tf.global_variables_initializer())
- # Setup interactive plot
- plt.ion()
- fig = plt.figure()
- ax1 = fig.add_subplot(111)
- line1, = ax1.plot(y_test)
- line2, = ax1.plot(y_test*0.5)
- plt.show()
- # Number of epochs and batch size
- epochs = 10
- batch_size = 256for e in range(epochs):
- # Shuffle training data
- shuffle_indices = np.random.permutation(np.arange(len(y_train)))
- X_train = X_train[shuffle_indices]
- y_train = y_train[shuffle_indices]
- # Minibatch training
- for i in range(0, len(y_train) // batch_size):
- start = i * batch_size
- batch_x = X_train[start:start + batch_size]
- batch_y = y_train[start:start + batch_size]
- # Run optimizer with batch
- net.run(opt, feed_dict={X: batch_x, Y: batch_y})
- # Show progress
- if np.mod(i, 5) == 0:
- # Prediction
- pred = net.run(out, feed_dict={X: X_test})
- line2.set_ydata(pred)
- plt.title('Epoch ' + str(e) + ', Batch ' + str(i))
- file_name = 'img/epoch_' + str(e) + '_batch_' + str(i) + '.jpg'
- plt.savefig(file_name)
- plt.pause(0.01)
在訓練過程中,我們在測試集(沒有被網絡學習過的數據)上評估了網絡的預測能力,每訓練 5 個 batch 進行一次,并展示結果。此外,這些圖像將被導出到磁盤并組合成一個訓練過程的視頻動畫。模型能迅速學習到測試數據中的時間序列的位置和形狀,并在經過幾個 epoch 的訓練之后生成準確的預測。太棒了!
可以看到,網絡迅速地適應了時間序列的基本形狀,并能繼續學習數據的更精細的模式。這歸功于 Adam 學習方案,它能在模型訓練過程中降低學習率,以避免錯過最小值。經過 10 個 epoch 之后,我們***地擬合了測試數據!***的測試 MSE 等于 0.00078,這非常低,因為目標被縮放過。測試集的預測的平均百分誤差率等于 5.31%,這是很不錯的結果。
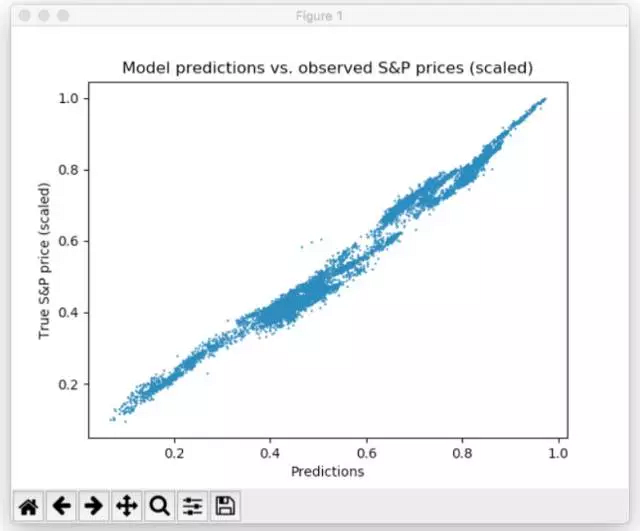
預測和實際 S&P 價格的散點圖(已縮放)
請注意其實還有很多種方法能進一步優化這個結果:層和神經元的設計、不同的初始化和激活方案的選擇、引入神經元的 dropout 層、早期停止法的應用,等等。此外,其它不同類型的深度學習模型,比如循環神經網絡也許能在這個任務中達到更好的結果。不過,這在我們的討論范圍之外。
結論和展望
TensorFlow 的發布是深度學習研究的里程碑事件,其高度的靈活性和強大的性能使研究者能開發所有種類的復雜神經網絡架構以及其它機器學習算法。然而,相比使用高級 API 如 Keras 或 MxNet,靈活性的代價是更長的建模時間。盡管如此,我相信 TensorFlow 將繼續發展,并成為神經網路和和深度學習開發的研究和實際應用的現實標準。我們很多客戶都已經在使用 TensorFlow,或正在開發應用 TensorFlow 模型的項目。我們的 STATWORX 的數據科學顧問(https://www.statworx.com/de/data-science/)基本都是用 TensorFlow 研究課開發深度學習以及神經網絡。
谷歌未來針對 TensorFlow 的計劃會是什么呢?至少在我看來,TensorFlow 缺少一個簡潔的圖形用戶界面,用于在 TensorFlow 后端設計和開發神經網絡架構。也許這就是谷歌未來的一個目標