教你一個簡單的深度學習方法檢測人臉面部特征
筆者按:你可能在一些手機軟件上已經看到了給人臉增加特效的app,它們將一些可愛有趣的物體添加到自拍視頻中,有些更有趣的還能檢測表情自動選擇相應的物體。這篇文章將會科普一種使用深度學習進行人臉表情檢測的方法,并簡要介紹下傳統的檢測方法。

在過去,檢測面部及其特征,包括眼睛、鼻子、嘴巴,甚至從它們的形狀中提取表情是非常困難的,而現在,這項任務可以通過深度學習“神奇”地得到解決,任何一個聰明的年輕人都可以在幾個小時內完成。雷鋒網 AI 科技評論編譯的這篇來自佐治亞理工大學學生 Peter Skvarenina 的文章將介紹這一實現方法。
“傳統”的方法(CLM)
假設你和我一樣,現在需要進行人臉追蹤(在這篇文章的情況下,是指將一個人的面部動作通過網絡攝像頭同步到一個動畫人物上去),你可能會發現,以前實現這個任務最好的算法是局部約束模型(CLM),基于Cambridge Face Tracker或者OpenFace。這種方法是將檢測的任務進行分解,分成檢測形狀向量特征(ASM)、布丁圖像模板(AAM)和使用預先訓練的線性SVM進行檢測優化這幾個步驟逐一處理。

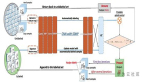
首先對關鍵點進行粗略估計,然后使用含有部分人臉信息的預訓練的圖像進行SVM處理,同時對關鍵點的位置進行校正。重復這個過程多次,直到其產生的誤差低于我們的要求。另外,值得一提的是,這一方法假定了圖像上的人臉位置已經被估計,如使用Viola-Jones檢測器(Haar級聯)。但是,這種方法非常復雜并不是高中級別的學生可以輕易實現的,整體架構如下:

深度學習(Deep Learning)
為了實現文中一開始提到的,使得青少年可以進行人臉檢測的目標,我們向大家介紹深度學習的方法。在這里,我們將會使用一種非常簡單的卷積神經網絡(CNN,convolutional neural network)并在一些含有人臉的圖像上進行人臉重要部位的檢測。為此,我們首先需要一個訓練的數據庫,這邊我們可以使用Kaggle提供的人臉部位識別挑戰賽的數據庫,包含15個關鍵點;或者一個更復雜些的數據庫MUCT,它有76個關鍵點(超棒的!)。
很顯然的,有質量的圖像訓練數據庫是必不可少的,這里,我們向“可憐的”本科學生致敬,他們為了畢業“犧牲”了自己的時間和精力對這些圖像進行了標注,從而使得我們可以進行這些有趣的實驗。
如下是基于Kaggle數據庫的巴洛克面部和關鍵點的樣子:

這個數據庫是由灰度96*96分辨率的圖像組成的,并且有15個關鍵點,分別包含兩個眼睛各5個點、鼻子嘴巴共5個點。
對于任何一個圖像來說,我們首先要對臉部進行定位,即使用上文提到的Viola-Jones檢測器并基于Haar級聯架構(如果說你仔細看看這一實現過程,會發現它與CNN的概念相近)。如果你想更近一步,也可以使用全卷積網絡(FCN,Fully Convolutional Network)并使用深度預測進行圖像分割。

不管你使用什么方法,這對OpenCV來說都很簡單:
- Grayscale_image = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
- face_cascade =
- cv2.CascadeClassifier(‘haarcascade_frontalface_default.xml’
- )
- bounding_boxes =
- face_cascade.detectMultiScale(grayscale_image, 1.25, 6)
使用如上的幾行代碼,可將圖像中的人臉框出來。
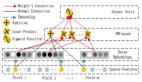
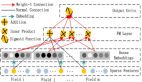
然后,對每一個返回的人臉框,我們提取其中相應的子圖像,將它們調整到灰度圖像并將尺寸轉換為96*96。新產生的圖像數據則成為了我們完成的CNN網絡的輸入。CNN的架構采用最通用的,5*5的卷積層(實際上是3個layer,每層分別是24、36和48個ReLU),然后用2個3*3的卷積層(每個有64個ReLU),最后使用3個全連接層(包含500、90和30個單元)。同時使用Max Pooling來避免過擬合并使用global average pooling來減少平滑參數的數量。這一架構的最終輸出結果是30個浮點數,這對應著15個關鍵點每個的想x,y坐標值。
如下是Keras的實現過程:
- model = Sequential()
- model.add(BatchNormalization(input_shape=(96, 96, 1)))
- model.add(Convolution2D(24, 5, 5, border_mode=”same”,
- init=’he_normal’, input_shape=(96, 96, 1),
- dim_ordering=”tf”))
- model.add(Activation(“relu”))
- model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2),
- border_mode=”valid”))
- model.add(Convolution2D(36, 5, 5))
- model.add(Activation(“relu”))
- model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2),
- border_mode=”valid”))
- model.add(Convolution2D(48, 5, 5))
- model.add(Activation(“relu”))
- model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2),
- border_mode=”valid”))
- model.add(Convolution2D(64, 3, 3))
- model.add(Activation(“relu”))
- model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2),
- border_mode=”valid”))
- model.add(Convolution2D(64, 3, 3))
- model.add(Activation(“relu”))
- model.add(GlobalAveragePooling2D());
- model.add(Dense(500, activation=”relu”))
- model.add(Dense(90, activation=”relu”))
- model.add(Dense(30))
你可能想選擇均方根傳播(rmsprop)優化和均方誤差(MSE)作為損失函數和精度指標。只需要在輸入圖像上使用批處理正常化和全局平均遍歷(global average polling)和HE normal weight初始化,你就可以在30個訓練周期內獲得80%-90%的驗證準確率并實現<0.001的誤差:
- model.compile(optimizer=’rmsprop’, loss=’mse’, metrics=
- [‘accuracy’])
- checkpointer = ModelCheckpoint(filepath=’face_model.h5',
- verbose=1, save_best_only=True)
- epochs = 30
- hist = model.fit(X_train, y_train, validation_split=0.2,
- shuffle=True, epochs=epochs, batch_size=20, callbacks=
- [checkpointer], verbose=1)


簡單的執行如下指令對關鍵點位置進行預測:
- features = model.predict(region, batch_size=1)
好了!現在你已經學會了怎么去檢測面部關鍵點了!
提醒一下,你的預測結果是15對(x,y)坐標值,可在如下圖像中表現出來:

如果上述的操作還不能滿足你的需求,你還可以進行如下步驟:
- 實驗如何在保持精度和提高推理速度的同時減少卷積層和濾波器的數量;
- 使用遷移學習來替代卷積的部分(Xception是我的最愛)
- 使用一個更詳細的數據庫
- 做一些高級的圖像增強來提高魯棒性
你可能依然覺得太簡單了,那么推薦你學習去做一些3D的處理,你可以參考Facebook和NVIDIA是怎么進行人臉識別和追蹤的。
另外,你可以用已經學到的這些進行一些新奇的事情(你可能一直想做但不知道怎么實現):
- 在視頻聊天時,把一些好玩的圖片放置在人臉面部上,比如:墨鏡,搞笑的帽子和胡子等;
- 交換面孔,包括你和朋友的臉,動物和物體等;
- 在自拍實時視頻中用一些新發型、珠寶和化妝進行產品測試;
- 檢測你的員工是因為喝酒無法勝任一些任務;
- 從人們的反饋表情中提取當下流行的表情;
- 使用對抗網絡(GANs)來進行實時的人臉-卡通變換,并使用網絡實現實時人臉和卡通動畫表情的同步。
好了~你現在已經學會了怎么制作你自己的視頻聊天濾鏡了,快去制作一個有趣的吧!