如何一步一步提高圖像分類準確率?
一、問題描述
當我們在處理圖像識別或者圖像分類或者其他機器學習任務的時候,我們總是迷茫于做出哪些改進能夠提升模型的性能(識別率、分類準確率)。。。或者說我們在漫長而苦惱的調參過程中到底調的是哪些參數。。。所以,我花了一部分時間在公開數據集CIFAR-10 [1] 上進行探索,來總結出一套方法能夠快速高效并且有目的性地進行網絡訓練和參數調整。
CIFAR-10數據集有60000張圖片,每張圖片均為分辨率為32*32的彩色圖片(分為RGB3個信道)。CIFAR-10的分類任務是將每張圖片分成青蛙、卡車、飛機等10個類別中的一個類別。本文主要使用基于卷積神經網絡的方法(CNN)來設計模型,完成分類任務。
首先,為了能夠在訓練網絡的同時能夠檢測網絡的性能,我對數據集進行了訓練集/驗證集/測試集的劃分。訓練集主要用戶進行模型訓練,驗證集主要進行參數調整,測試集主要進行模型性能的評估。因此,我將60000個樣本的數據集分成了,45000個樣本作為訓練集,5000個樣本作為驗證集,10000個樣本作為測試集。接下來,我們一步步來分析,如果進行模型設計和改進。
二、搭建最簡單版本的CNN
對于任何的機器學習問題,我們一上來肯定是采用最簡單的模型,一方面能夠快速地run一個模型,以了解這個任務的難度,另一方面能夠有一個baseline版本的模型,利于進行對比實驗。所以,我按照以往經驗和網友的推薦,設計了以下的模型。
模型的輸入數據是網絡的輸入是一個4維tensor,尺寸為(128, 32, 32, 3),分別表示一批圖片的個數128、圖片的寬的像素點個數32、高的像素點個數32和信道個數3。首先使用多個卷積神經網絡層進行圖像的特征提取,卷積神經網絡層的計算過程如下步驟:
- 卷積層1:卷積核大小3*3,卷積核移動步長1,卷積核個數64,池化大小2*2,池化步長2,池化類型為最大池化,激活函數ReLU。
- 卷積層2:卷積核大小3*3,卷積核移動步長1,卷積核個數128,池化大小2*2,池化步長2,池化類型為最大池化,激活函數ReLU。
- 卷積層3:卷積核大小3*3,卷積核移動步長1,卷積核個數256,池化大小2*2,池化步長2,池化類型為最大池化,激活函數ReLU。
- 全連接層:隱藏層單元數1024,激活函數ReLU。
- 分類層:隱藏層單元數10,激活函數softmax。
參數初始化,所有權重矩陣使用random_normal(0.0, 0.001),所有偏置向量使用constant(0.0)。使用cross entropy作為目標函數,使用Adam梯度下降法進行參數更新,學習率設為固定值0.001。
該網絡是一個有三層卷積層的神經網絡,能夠快速地完成圖像地特征提取。全連接層用于將圖像特征整合成分類特征,分類層用于分類。cross entropy也是最常用的目標函數之一,分類任務使用cross entropy作為目標函數非常適合。Adam梯度下降法也是現在非常流行的梯度下降法的改進方法之一,學習率過大會導致模型難以找到較優解,設置過小則會降低模型訓練效率,因此選擇適中的0.001。這樣,我們最基礎版本的CNN模型就已經搭建好了,接下來進行訓練和測試以觀察結果。
訓練5000輪,觀察到loss變化曲線、訓練集準確率變化曲線和驗證集準確率變化曲線如下圖。測試集準確率為69.36%。
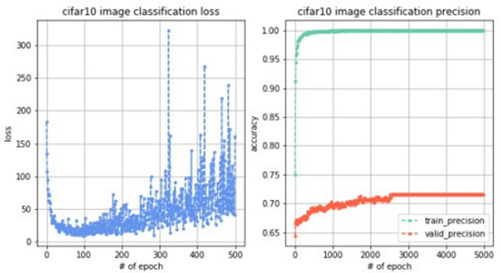
結果分析:首先我們觀察訓練loss(目標函數值)變化,剛開始loss從200不斷減小到接近0,但是在100輪左右開始出現震蕩,并且隨著訓練幅度越來越大,說明模型不穩定。然后觀察訓練集和驗證集的準確率,發現訓練集準確率接近于1,驗證集準確率穩定在70%左右,說明模型的泛化能力不強并且出現了過擬合情況。最后評估測試集,發現準確率為69.36%,也沒有達到很滿意的程度,說明我們對模型需要進行很大的改進,接下來進行漫長的調參之旅吧!
三、數據增強有很大的作用
使用數據增強技術(data augmentation),主要是在訓練數據上增加微小的擾動或者變化,一方面可以增加訓練數據,從而提升模型的泛化能力,另一方面可以增加噪聲數據,從而增強模型的魯棒性。主要的數據增強方法有:翻轉變換 flip、隨機修剪(random crop)、色彩抖動(color jittering)、平移變換(shift)、尺度變換(scale)、對比度變換(contrast)、噪聲擾動(noise)、旋轉變換/反射變換 (rotation/reflection)等,可以參考Keras的官方文檔 [2] 。獲取一個batch的訓練數據,進行數據增強步驟之后再送入網絡進行訓練。
我主要做的數據增強操作有如下方面:
- 圖像切割:生成比圖像尺寸小一些的矩形框,對圖像進行隨機的切割,最終以矩形框內的圖像作為訓練數據。
- 圖像翻轉:對圖像進行左右翻轉。
- 圖像白化:對圖像進行白化操作,即將圖像本身歸一化成Gaussian(0,1)分布。
為了進行對比實驗,觀測不同數據增強方法的性能,實驗1只進行圖像切割,實驗2只進行圖像翻轉,實驗3只進行圖像白化,實驗4同時進行這三種數據增強方法,同樣訓練5000輪,觀察到loss變化曲線、訓練集準確率變化曲線和驗證集準確率變化曲線對比如下圖。
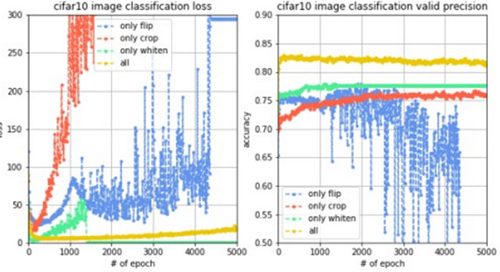
結果分析:我們觀察訓練曲線和驗證曲線,很明顯地發現圖像白化的效果好,其次是圖像切割,再次是圖像翻轉,而如果同時使用這三種數據增強技術,不僅能使訓練過程的loss更穩定,而且能使驗證集的準確率提升至82%左右,提升效果十分明顯。而對于測試集,準確率也提升至80.42%。說明圖像增強確實通過增加訓練集數據量達到了提升模型泛化能力以及魯棒性的效果,從準確率上看也帶來了將近10%左右的提升,因此,數據增強確實有很大的作用。但是對于80%左右的識別準確率我們還是不夠滿意,接下來繼續調參。
四、從模型入手,使用一些改進方法
接下來的步驟是從模型角度進行一些改進,這方面的改進是誕生論文的重要區域,由于某一個特定問題對某一個模型的改進千變萬化,沒有辦法全部去嘗試,因此一般會實驗一些general的方法,比如批正則化(batch normalization)、權重衰減(weight decay)。我這里實驗了4種改進方法,接下來依次介紹。
- 權重衰減(weight decay):對于目標函數加入正則化項,限制權重參數的個數,這是一種防止過擬合的方法,這個方法其實就是機器學習中的l2正則化方法,只不過在神經網絡中舊瓶裝新酒改名為weight decay [3]。
- dropout:在每次訓練的時候,讓某些的特征檢測器停過工作,即讓神經元以一定的概率不被激活,這樣可以防止過擬合,提高泛化能力 [4]。
- 批正則化(batch normalization):batch normalization對神經網絡的每一層的輸入數據都進行正則化處理,這樣有利于讓數據的分布更加均勻,不會出現所有數據都會導致神經元的激活,或者所有數據都不會導致神經元的激活,這是一種數據標準化方法,能夠提升模型的擬合能力 [5]。
- LRN:LRN層模仿生物神經系統的側抑制機制,對局部神經元的活動創建競爭機制,使得響應比較大的值相對更大,提高模型泛化能力。
為了進行對比實驗,實驗1只使用權重衰減,實驗2使用權重衰減+dropout,實驗3使用權重衰減+dropout+批正則化,實驗4使用權重衰減+dropout+批正則化+LRN,同樣都訓練5000輪,觀察到loss變化曲線、訓練集準確率變化曲線和驗證集準確率變化曲線對比如下圖。
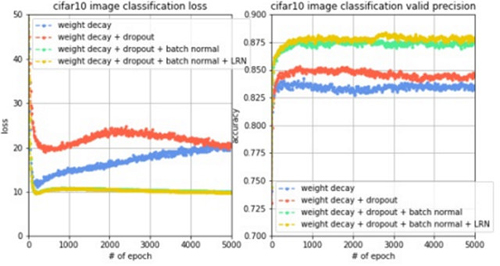
結果分析:我們觀察訓練曲線和驗證曲線,隨著每一個模型提升的方法,都會使訓練集誤差和驗證集準確率有所提升,其中,批正則化技術和dropout技術帶來的提升非常明顯,而如果同時使用這些模型提升技術,會使驗證集的準確率從82%左右提升至88%左右,提升效果十分明顯。而對于測試集,準確率也提升至85.72%。我們再注意看左圖,使用batch normalization之后,loss曲線不再像之前會出現先下降后上升的情況,而是一直下降,這說明batch normalization技術可以加強模型訓練的穩定性,并且能夠很大程度地提升模型泛化能力。所以,如果能提出一種模型改進技術并且從原理上解釋同時也使其適用于各種模型,那么就是非常好的創新點,也是我想挑戰的方向。現在測試集準確率提升至85%左右,接下來我們從其他的角度進行調參。
五、變化的學習率,進一步提升模型性能
在很多關于神經網絡的論文中,都采用了變化學習率的技術來提升模型性能,大致的想法是這樣的:
- 首先使用較大的學習率進行訓練,觀察目標函數值和驗證集準確率的收斂曲線。
- 如果目標函數值下降速度和驗證集準確率上升速度出現減緩時,減小學習率。
- 循環步驟2,直到減小學習率也不會影響目標函數下降或驗證集準確率上升為止。
為了進行對比實驗,實驗1只使用0.01的學習率訓練,實驗2前10000個batch使用0.01的學習率,10000個batch之后學習率降到0.001,實驗3前10000個batch使用0.01的學習率,10000~20000個batch使用0.001的學習率,20000個batch之后學習率降到0.0005。同樣都訓練5000輪,觀察到loss變化曲線、訓練集準確率變化曲線和驗證集準確率變化曲線對比如下圖。
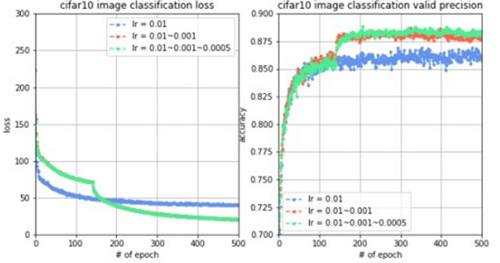
結果分析:我們觀察到,當10000個batch時,學習率從0.01降到0.001時,目標函數值有明顯的下降,驗證集準確率有明顯的提升,而當20000個batch時,學習率從0.001降到0.0005時,目標函數值沒有明顯的下降,但是驗證集準確率有一定的提升,而對于測試集,準確率也提升至86.24%。這說明,學習率的變化確實能夠提升模型的擬合能力,從而提升準確率。學習率在什么時候進行衰減、率減多少也需要進行多次嘗試。一般在模型基本成型之后,使用這種變化的學習率的方法,以獲取一定的改進,精益求精。
六、加深網絡層數,會發生什么事情?
現在深度學習大熱,所以,在計算資源足夠的情況下,想要獲得模型性能的提升,大家最常見打的想法就是增加網絡的深度,讓深度神經網絡來解決問題,但是簡單的網絡堆疊不一定就能達到很好地效果,抱著深度學習的想法,我按照plain-cnn模型 [6],我做了接下來的實驗。
- 卷積層1:卷積核大小3*3,卷積核移動步長1,卷積核個數16,激活函數ReLU,使用batch_normal和weight_decay,接下來的n層,卷積核大小3*3,卷積核移動步長1,卷積核個數16,激活函數ReLU,使用batch_normal和weight_decay。
- 卷積層2:卷積核大小3*3,卷積核移動步長2,卷積核個數32,激活函數ReLU,使用batch_normal和weight_decay,接下來的n層,卷積核大小3*3,卷積核移動步長1,卷積核個數32,激活函數ReLU,使用batch_normal和weight_decay。
- 卷積層3:卷積核大小3*3,卷積核移動步長2,卷積核個數64,激活函數ReLU,使用batch_normal和weight_decay,接下來的n層,卷積核大小3*3,卷積核移動步長1,卷積核個數64,激活函數ReLU,使用batch_normal和weight_decay。
- 池化層:使用全局池化,對64個隱藏單元分別進行全局池化。
- 全連接層:隱藏層單元數10,激活函數softmax,使用batch_normal和weight_decay。
為了進行對比實驗,進行4組實驗,每組的網絡層數分別設置8,14,20和32。同樣都訓練5000輪,觀察到loss變化曲線、訓練集準確率變化曲線和驗證集準確率變化曲線對比如下圖。
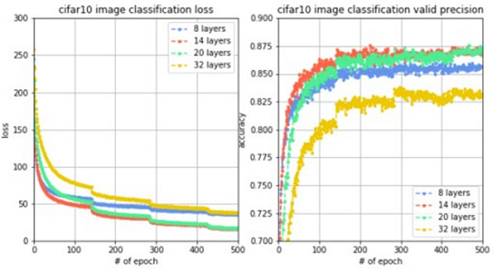
結果分析:我們驚訝的發現,加深了網絡層數之后,性能反而下降了,達不到原來的驗證集準確率,網絡層數從8層增加到14層,準確率有所上升,但從14層增加到20層再增加到32層,準確率不升反降,這說明如果網絡層數過大,由于梯度衰減的原因,導致網絡性能下降,因此,需要使用其他方法解決梯度衰減問題,使得深度神經網絡能夠正常work。
七、終極武器,殘差網絡
2015年,Microsoft用殘差網絡 [7] 拿下了當年的ImageNet,這個殘差網絡就很好地解決了梯度衰減的問題,使得深度神經網絡能夠正常work。由于網絡層數加深,誤差反傳的過程中會使梯度不斷地衰減,而通過跨層的直連邊,可以使誤差在反傳的過程中減少衰減,使得深層次的網絡可以成功訓練,具體的過程可以參見其論文[7]。
通過設置對比實驗,觀察殘差網絡的性能,進行4組實驗,每組的網絡層數分別設置20,32,44和56。觀察到loss變化曲線和驗證集準確率變化曲線對比如下圖。
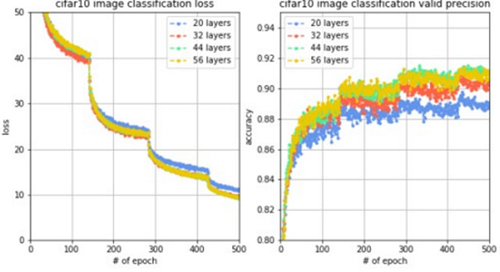
結果分析:我們觀察到,網絡從20層增加到56層,訓練loss在穩步降低,驗證集準確率在穩步提升,并且當網絡層數是56層時能夠在驗證集上達到91.55%的準確率。這說明,使用了殘差網絡的技術,可以解決梯度衰減問題,發揮深層網絡的特征提取能力,使模型獲得很強的擬合能力和泛化能力。當我們訓練深度網絡的時候,殘差網絡很有可能作為終極武器發揮至關重要的作用。
八、總結
對于CIFAR-10圖像分類問題,我們從最簡單的卷積神經網絡開始,分類準確率只能達到70%左右,通過不斷地增加提升模型性能的方法,最終將分類準確里提升到了90%左右,這20%的準確率的提升來自于對數據的改進、對模型的改進、對訓練過程的改進等,具體每一項提升如下表所示。
- 改進方法 獲得準確率 提升
- 基本神經網絡 69.36% –
- +數據增強 80.42% 11.06%
- +模型改進 85.72% 16.36%
- +變化學習率 86.24% 16.88%
- +深度殘差網絡 91.55% 22.19%
其中,數據增強技術使用翻轉圖像、切割圖像、白化圖像等方法增加數據量,增加模型的擬合能力。模型改進技術包括batch normalization、weight decay、dropout等防止過擬合,增加模型的泛化能力。變化學習率通過在訓練過程中遞減學習率,使得模型能夠更好的收斂,增加模型的擬合能力。加深網絡層數和殘差網絡技術通過加深模型層數和解決梯度衰減問題,增加模型的擬合能力。這些改進方法的一步步堆疊,一步步遞進,使得網絡的擬合能力和泛化能力越來越強,最終獲得更高的分類準確率。
本文的所有代碼見我的github,persistforever/cifar10-tensorflow
本文介紹的調參歷程,希望能幫助到大家,聽說過這么一句話,“讀研期間學習人工智能,什么都不用學,學好調參就行了”,而“調參”二字卻包含著無數的知識,希望大家能多分享神經網絡相關的干貨。