如何一步一步設(shè)計一個大規(guī)模復(fù)雜的系統(tǒng)
良好的系統(tǒng)設(shè)計能力,是一個優(yōu)秀程序員的必要素質(zhì),反應(yīng)出了處理復(fù)雜問題的能力,也是面試過程中能否獲得相應(yīng)的職位和薪酬的關(guān)鍵。
最近在 https://www.educative.io/ 上看到一份介紹系統(tǒng)設(shè)計的教程:Grokking the System Design Interview[1],里面有很多系統(tǒng)設(shè)計實例,如 Dropbox, Twitter, Facebook Messenger, Uber 等,教程是收費的,質(zhì)量很高,學(xué)習(xí)系統(tǒng)設(shè)計的絕佳資料,該教程的中文資料很少,這里就將其中的核心內(nèi)容翻成中文與大家分享,如果需看英文原版,回復(fù)「系統(tǒng)設(shè)計」即可獲取。
許多軟件工程師在系統(tǒng)設(shè)計面試(以下簡稱 SDI)時遇到困難,主要有三個方面原因:
- SDI 具有非結(jié)構(gòu)化性質(zhì),往往要求開放式設(shè)計,很多問題沒有標(biāo)準(zhǔn)答案。
- 他們?nèi)狈﹂_發(fā)大型系統(tǒng)的經(jīng)驗。
- 他們沒有為 SDI 做準(zhǔn)備。
像編碼面試一樣,沒有認(rèn)真準(zhǔn)備 SDI 的應(yīng)聘者,大部分表現(xiàn)不佳,尤其是在 Google,F(xiàn)acebook,Amazon,Microsoft 等頂尖公司的面試,如果表現(xiàn)不及平均水平的候選人,獲得獲得 offer 的機會非常渺茫。另一方面,良好的面試表現(xiàn)總是會帶來更好的回報,或者是更高的職位,或者是更高的薪水,因為這顯示了候選人處理復(fù)雜系統(tǒng)的能力。
接下來,我們將按以下步驟循序漸進地解決多個設(shè)計問題:
第一步:需求澄清
在需求范圍內(nèi)提出一些問題有助于澄清需求。設(shè)計問題大多是開放性的,并且沒有一個標(biāo)準(zhǔn)答案,這就是為什么要澄清一些具體需求。花費足夠時間來定義系統(tǒng)最終目標(biāo)有助于在面試中獲得成功。另外,由于系統(tǒng)設(shè)計的面試只有 35-40 分鐘的時間,我們應(yīng)該弄清楚哪些部分需要重點關(guān)注。
以設(shè)計一個類 Twitter 的服務(wù)為例,在開始設(shè)計之前應(yīng)先回答以下問題:
- 我們服務(wù)的用戶能否發(fā)布推文并關(guān)注其他人?
- 我們是否還應(yīng)該設(shè)計來創(chuàng)建和顯示用戶的時間軸?
- 推文中是否包含照片和視頻?
- 我們是僅專注于后端還是前端?
- 用戶將能夠搜索推文嗎?
- 我們需要顯示熱門話題嗎?
- 是否有關(guān)于新(或重要)推文的推送通知?
這些問題將決定最終設(shè)計的系統(tǒng)長什么樣。
第二步:系統(tǒng)接口定義
定義系統(tǒng)期望的接口(API)不僅可以幫助建立預(yù)期的接口協(xié)議 ,也可以確保我們沒有弄錯需求。比如類似 Twitter 的服務(wù)的接口可能是這樣的:
- postTweet(user_id, tweet_data, tweet_location, user_location, timestamp, …)
- generateTimeline(user_id, current_time, user_location, …)
- markTweetFavorite(user_id, tweet_id, timestamp, …)
第三步:資源預(yù)估
預(yù)估我們要設(shè)計的系統(tǒng)的規(guī)模是非常必要的,有助于我們后續(xù)的系統(tǒng)擴展、分區(qū)、負(fù)載平衡和緩存的設(shè)計。
- 系統(tǒng)預(yù)期的規(guī)模,例如,新推文的數(shù)量,推文的閱讀量,每秒產(chǎn)生的時間線?
- 我們需要多少存儲空間?如果用戶可以拍攝照片和視頻,又需要多少存儲空間。
- 我們期望多大的帶寬?這對于決定我們?nèi)绾喂芾砹髁亢推胶夥?wù)器之間的負(fù)載。
第四步:設(shè)計數(shù)據(jù)模型
早一點定義數(shù)據(jù)模型可以弄明白數(shù)據(jù)如何在不同組件之間進行流轉(zhuǎn)。數(shù)據(jù)模型將指導(dǎo)數(shù)據(jù)分區(qū)和管理。設(shè)計者應(yīng)該識別系統(tǒng)的各個實體,它們之間的交互方式以及 數(shù)據(jù)管理的各個方面,例如存儲、傳輸、加密等。以下是我們的類 Twitter 服務(wù)的一些實體:
- User:UserID, Name, Email, DoB, CreationData, LastLogin 等。
- Tweet:TweetID,Content,,TweetLocation,NumberOfLikes,TimeStamp等。
- UserFollowo:UserdID1,UserID2
- FavoriteTweets: UserID, TweetID, TimeStamp
我們應(yīng)該使用哪個數(shù)據(jù)庫系統(tǒng)?像 Cassandra 這樣的 NoSQL 是否最適合我們的需求,還是應(yīng)該使用類似于 MySQL 的解決方案?我們應(yīng)該使用哪種塊存儲來存儲照片和視頻?
第五步:高級設(shè)計
畫一個帶有 5-6 個方框的圖,代表我們系統(tǒng)的核心組件。我們應(yīng)該識別出足夠的組件來解決端到端的問題,對于 Twitter 而言,我們將需要多個應(yīng)用服務(wù)器來服務(wù)所有的讀/寫服務(wù),并配置負(fù)載平衡器進行流量分配。假如讀流量大于寫流量,我們可以使用單獨的服務(wù)器進行處理這些情況,比如分配 10 臺服務(wù)器服務(wù)讀請求,2 臺服務(wù)器服務(wù)寫請求。在后端,我們需要一個高性能的數(shù)據(jù)庫,該數(shù)據(jù)庫可以存儲所有推文并支持大量讀取。我們還需要一個分布式文件存儲系統(tǒng)來存儲照片和視頻。
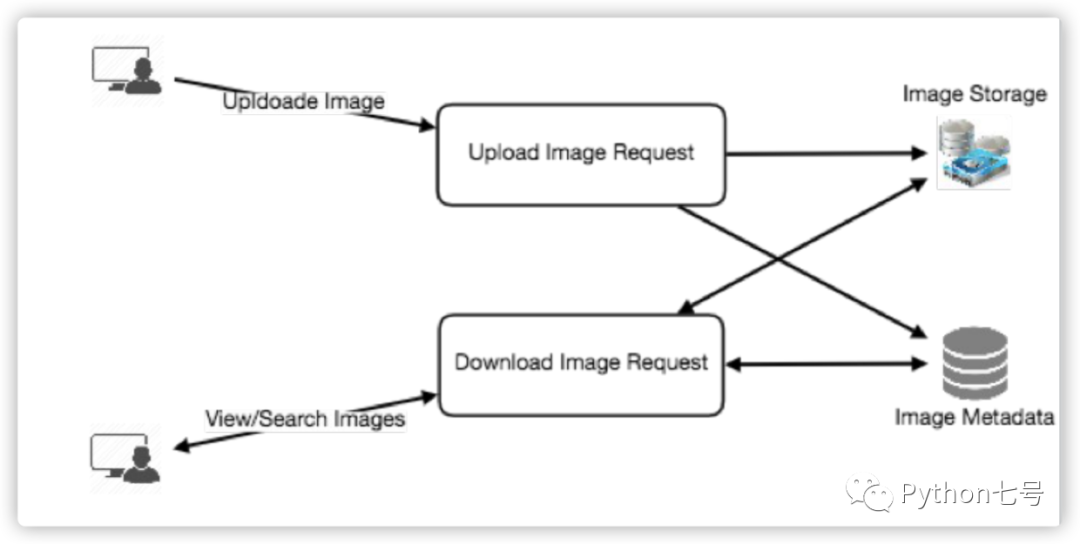
第六步:詳細設(shè)計
深入挖掘兩個或三個組成部分;面試官的反饋意見引導(dǎo)我們進一步討論。我們應(yīng)該能夠提出不同的方法,它們的優(yōu)點和缺點,并說明為什么我們會選擇另一種方法。請記住,沒有標(biāo)準(zhǔn)答案,唯一重要的是有限資源前提下怎么做出權(quán)衡。
- 由于我們將存儲大量數(shù)據(jù),因此如何將數(shù)據(jù)分區(qū)到分發(fā)到多個數(shù)據(jù)庫?是否應(yīng)該嘗試將用戶的所有數(shù)據(jù)存儲在同一數(shù)據(jù)庫?它會導(dǎo)致什么問題?
- 如何處理發(fā)大量推文或關(guān)注很多人的熱門用戶?
- 由于用戶的時間軸將包含最新推文,為了獲取最新推文是否需要優(yōu)化數(shù)據(jù)的存取方式?
- 我們應(yīng)該在多少層引入緩存以加快處理速度?
- 哪些組件需要更好的負(fù)載平衡?
第七步:找出并解決瓶頸
找出盡可能多的瓶頸問題,并提出緩解這些瓶頸的不同方法。比如:
- 我們的系統(tǒng)中是存在單點故障?應(yīng)該采取什么措施緩解這種情況?
- 我們是否有足夠的數(shù)據(jù)備份,在多少臺服務(wù)器宕機的情況下仍可以為用戶提供服務(wù)?
- 類似的,我們是否有足夠數(shù)量的不同服務(wù)在運行,即使一些服務(wù)有故障也不會會導(dǎo)致系統(tǒng)崩潰?
- 我們?nèi)绾伪O(jiān)控我們的服務(wù)性能?關(guān)鍵時刻比如組件發(fā)生故障或性能下降時會收到報警嗎?
最后的話
簡而言之,面試前有足夠的準(zhǔn)備是系統(tǒng)設(shè)計面試成功的關(guān)鍵,上述步驟可以指導(dǎo)我們設(shè)計一個復(fù)雜的大規(guī)模系統(tǒng),涵蓋了的不同方面的面試問題,后續(xù)的面試問題,可以參考以上步驟來思考和回答。
參考資料
[1]Grokking the System Design Interview: https://www.educative.io/courses/grokking-the-system-design-interview
本文轉(zhuǎn)載自微信公眾號「Python七號」,可以通過以下二維碼關(guān)注。轉(zhuǎn)載本文請聯(lián)系Python七號公眾號。