搜尋失落的信號:無監(jiān)督學習面臨的眾多挑戰(zhàn)
督學習面臨的眾多挑戰(zhàn)")
無監(jiān)督特征學習的當前趨勢概覽:回歸到隨機目標的流形學習,發(fā)掘因果關(guān)系以描述視覺特征,以及在強化學習中通過輔助控制任務增強目的性和通過自我模擬進行預訓練。從無標注數(shù)據(jù)中可以挖掘的信息有很多,看起來我們目前的監(jiān)督學習只不過是掠過了數(shù)據(jù)蛋糕的表面奶油而已。
2017 年,在無監(jiān)督學習領(lǐng)域發(fā)生了什么?在本文中,我將從個人角度概覽一些最近工作進展的。
「無監(jiān)督學習是機器學習中一場曠日持久的挑戰(zhàn),被視為人工智能的關(guān)鍵要素。」Yann LeCun 解釋道。相當程度上,我們在無標注數(shù)據(jù)中忽略了非常多的信息,而且通常也認為,人類大腦在學習的大部分時間中都不是處于監(jiān)督狀態(tài)并能處理無標注信息。或許看看下面這幅著名的「Yann LeCun 的蛋糕」,你能得到更好的理解。

事實上,通過相當數(shù)量的標注樣本訓練機器也許對理解我們的學習機制很有幫助,但是在尋找現(xiàn)象的內(nèi)部規(guī)律的時候;被反常現(xiàn)象震驚并試圖尋找其中規(guī)律的時候;被好奇心牽動的時候;通過游戲訓練技能的時候,這些場景都不需要有人明確地告訴你理論上哪些是好的,哪些是壞的。沒錯,這些例子選取有些隨意,但以上就是我從本文涉及到的論文中找到的一些想法。
下文中提及的所有想法都有共同的基礎:從未接觸過的數(shù)據(jù)中找到一種自監(jiān)督的方法是不太可能的。那么,我們需要尋找在沒有標簽的數(shù)據(jù)中尋找哪些信號呢?或者說,如何在沒有任何監(jiān)督的情況下學習特征呢?
《Unsupervised learning by predicting the noise》這篇論文給出了一個很異乎尋常的答案,就是噪聲。我認為這篇論文在今年的 ICML 大會上是最重要的研究之一。論文的構(gòu)想如下:每一個樣本都相當于超球面上的一個向量,向量標注了數(shù)據(jù)點在其上的位置。實際上,學習的過程就相當于將圖像和隨機向量匹配對應,通過在深度卷積網(wǎng)絡里訓練,并通過監(jiān)督學習最小化損失函數(shù)。
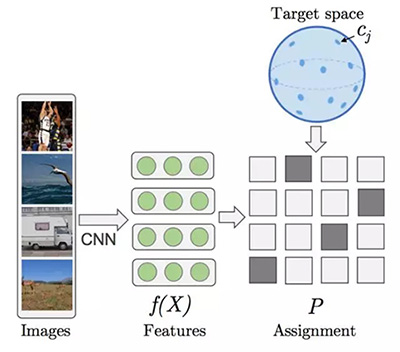
特別是,訓練的過程在以網(wǎng)絡的參量進行梯度下降和不同圖像的偽目標重置之間交替,最終也是為了最小化損失函數(shù)。這里展示的圖像特征的結(jié)果來自 ImageNet。兩者都是在 ImageNet 上訓練一個 AlexNet 得到的結(jié)果,左邊的基于目標函數(shù),右邊使用的是其提出的無監(jiān)督學習方法。
督學習方法")
這個方法可以說代表了遷移學習算法探索的***進技術(shù)水平,但為什么這種方法能奏效呢?我的解釋是:網(wǎng)絡學會了用新的表征空間重新表示超球面上的矩陣。這可稱為一種內(nèi)在的流形學習。通過打亂布置進行優(yōu)化是非常關(guān)鍵的方法,畢竟在新的表征空間中,不恰當?shù)钠ヅ洳荒軌蚴瓜嗨频膱D像位于相近的位置。此外,正如通常情況一樣,網(wǎng)絡必須作為一個信息瓶頸。否則,模型會由于容量限制而學習成信息不全的一一對應,給表征增加很多噪聲干擾(感謝 Mevlana 強調(diào)這一點)。
如此富有成效的結(jié)果竟然出自這樣反常的想法-我的意思是,論文的作者就是想要這種效果,看看標題就知道了-正是在不斷的強調(diào)著,你不應該用標注去尋找數(shù)據(jù)中的模式,即使目標具有很復雜的視覺特征。參見論文《Optimizing the Latent Space of Generative Networks》。
從圖像中發(fā)現(xiàn)因果關(guān)系[Lopez-Paz et al. CVPR17] (https://arxiv.org/abs/1605.08179)
我接下來的發(fā)現(xiàn)來自 Léon Bottou 一次極富啟發(fā)性和爭議性的報告 Looking for the missing signal
(https://www.youtube.com/watch?v=DfJeaa--xO0&t=12s)(沒錯,本文作者偷了他的題目)發(fā)現(xiàn)的另外一半來自于他們的 WGAN,是關(guān)于因果關(guān)系的。但是在討論之前,我們先回顧一下看看因果關(guān)系如何與我們的討論聯(lián)系起來。參見論文《Discovering Causal Signals in Images》。
如果你是通過機器學習理解因果關(guān)系的,你很快會得出圖中整個區(qū)域缺少了某樣東西,而較少關(guān)注它的背景。我們創(chuàng)造了一整套方法,只需要在訓練數(shù)據(jù)中關(guān)注它們的聯(lián)系,就可以將它們互相關(guān)聯(lián)并得出預測結(jié)果。但實際上很多種情況下這都不奏效。如果我們可以在模型訓練中加入因果關(guān)系的考慮的話又會如何呢?根本上說,我們可以阻止我們的卷積網(wǎng)絡宣布圖中的動物是一只獅子,因為背景表明這是一片典型的熱帶大草原嗎?
很多人都在朝這個方向努力。這篇文章也想證實這樣的觀點,「圖像數(shù)據(jù)的高級統(tǒng)計描述可以理解因果關(guān)系」。更精確的說,作者們猜想,物體特征和非因果特征是緊密聯(lián)系的,而環(huán)境特征和因果特征并不需要互相關(guān)聯(lián)。環(huán)境特征提供背景,而物體特征則是在數(shù)據(jù)集中的邊界特性。在圖中,它們分別指熱帶大草原和獅子的鬣毛。
另一方面,「因果特征是指導致圖中物體如此表現(xiàn)的原因(就是說,那些特征決定了物體的類別標簽),而非因果特征則是由圖中物體的表現(xiàn)所導致(就是說,那些特征是由類別標簽所決定)。」在我們的例子中,因果特征是熱帶大草原的視覺模式,非因果特征是獅子的鬣毛。
他們是怎么進行實驗的呢?太簡短的說明會有偏差,我將盡量避免。首先,我們需要訓練一個探測器尋找因果的方向,這個想法源于大量過去工作所證實的,「加法因果模型」會在觀察數(shù)據(jù)中遺留關(guān)于因果方向的統(tǒng)計痕跡,可以依次在學習高級時間點的過程中被探測到。(如果聽起來太陌生,我推薦先看看參考文獻)這個想法意在通過神經(jīng)網(wǎng)絡學習捕捉這些統(tǒng)計痕跡,可以用來辨別因果和非因果特征(進行二進制分類)。
只有擁有了真實因果關(guān)系標注的數(shù)據(jù)才能訓練這樣的網(wǎng)絡,而這樣的數(shù)據(jù)是很稀有的。但是實際上,通過設置一對因果變量并以一個記號指示因果關(guān)系,這樣的數(shù)據(jù)是很容易合成的。目前為止,還沒有人這樣使用過數(shù)據(jù)。
第二,兩個版本的圖像,無論是目標還是屏蔽目標后的圖片,都被標準的深度殘差網(wǎng)絡特征化。一些目標和背景評分都被設計為特征頂端,作為表示目標/背景的信號。

現(xiàn)在我們可以將圖像中物體和環(huán)境通過因果或者非因果關(guān)系聯(lián)系起來。這樣導致的結(jié)果是,舉例來說,「擁有***非因果分數(shù)的特征比起擁有***因果分數(shù)的特征,表現(xiàn)出更高的物體分數(shù)。」通過實驗性的證實這個猜想,結(jié)果暗示了,圖像中的因果性實際上是指物體和背景之間的差異。這個結(jié)果展現(xiàn)了其開辟新的研究領(lǐng)域的潛力,理論上,當數(shù)據(jù)的分布改變的時候,一個更好的探測因果方向的算法應該能更好的提取和學習特征。參見論文:《Causal inference using invariant prediction: identification and confidence intervals》、《Causal Effect Inference with Deep Latent-Variable Models》。
無監(jiān)督輔助任務的強化學習:《Reinforcement Learning with Unsupervised Auxiliary Tasks》這篇論文以現(xiàn)在標準看來也許有點不夠新穎,畢竟在本文寫成的時候,它已經(jīng)被引用過 60 次-自 11 月 16 日發(fā)表在 arXiv 上以來。但是實際上針對這個想法已經(jīng)出現(xiàn)了新的工作,而我并非在其基礎上討論更加復雜的方法,只是由于其基本和新穎的見解而引用了它。
這個方案就是強化學習。強化學習的主要困難就是獎勵的稀疏和延遲,那么為什么不引進輔助任務以增強訓練信號呢?當然是因為,偽獎勵必須和真實目標關(guān)聯(lián)并且在執(zhí)行過程中不依賴人為的監(jiān)督。
論文給出了很直接和實在的建議:遍歷所有輔助任務并增強目標函數(shù)(***化獎勵)。在總體表現(xiàn)的意義上,該策略會在整體表現(xiàn)的前提下學習。實際上,有一些模型會同時接近于主策略與其他策略,以完成額外任務;這些模型會共享它們的參數(shù)。例如,模型的***層可以共同學習,將其視覺特征都展開。「讓智能體平衡提高總體獎勵的表現(xiàn)和提高輔助任務的表現(xiàn)是很有必要的」。
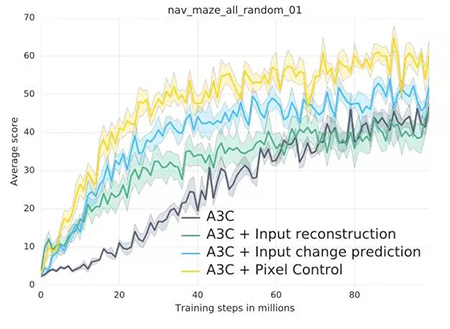
以下所示是論文中所探索的輔助性任務。首先是像素控制,智能體通過獨立的決策***的改變輸入圖像的每一個像素點。其基本原理是「感知流中的改變通常和環(huán)境中的重要事件有關(guān)。」因此學習控制改變是很有意義的。第二個是特征控制,智能體被訓練預測價值網(wǎng)絡的一些中間層的隱藏單元的活化值。這個想法很有趣,「因為一個智能體的決策或者價值網(wǎng)絡能學習提取環(huán)境中任務相關(guān)的高級特征。」第三個是獎勵預測,智能體學習預測即時到來的獎勵。這三種輔助任務通過智能體過去經(jīng)驗緩存的不斷重新體驗來學習。
其它細節(jié)暫且不提,這一整套方法被稱作 UNREAL。在 Atari 游戲和 Labyrint 的測試中,它表現(xiàn)出了很快的學習速度,并能做出更好的決策。
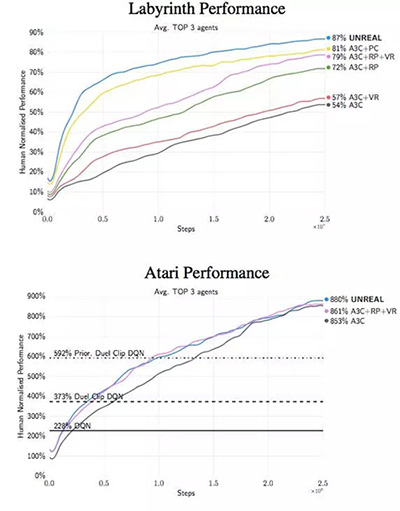
論文***的洞見是關(guān)于像素控制的有效性,而不是簡單通過重構(gòu)損失函數(shù)來進行預測的。可以將這些行為視為視覺自監(jiān)督,但這是另一種層次的抽象概念。「學習重構(gòu)只能讓剛開始的學習速度很快,但***得到的效果卻更差。我們的假設是輸入重構(gòu)會降低***的表現(xiàn)效果,因為它過于關(guān)注重構(gòu)視覺輸入的不相關(guān)部分,而不是能得到獎勵的視覺線索。」
通過非對稱自我模擬的內(nèi)在動機形成和無意識學習:論文《Intrinsic Motivation and Automatic Curricula via Asymmetric Self-Play》。***我想強調(diào)的一篇論文是強化學習中關(guān)于輔助任務的想法。不過,關(guān)鍵是,相比明確的扭曲目標函數(shù),智能體被訓練完成完整的自我模擬,在確切的范圍內(nèi)可以自動生成更簡單的任務。
自我模擬的最初形態(tài)是將智能體分離成「兩個獨立的意識」而建立的,分別稱作 Alice 和 Bob。作者假定自我模擬中環(huán)境是(幾乎)可逆的或者是可以重置到初始狀態(tài)的。在這個案例中,Alice 執(zhí)行了一個任務然后叫 Bob 也做同樣的事,即根據(jù) Alice 結(jié)束任務時的位置,到達世界中的同一個可觀測狀態(tài)。例如,Alice 可以走動然后撿起一把鑰匙,打開一扇門,關(guān)掉燈然后停在一個確切的位置;Bob 必須跟隨 Alice 做同樣事情然后和 Alice 停在同一個位置。***,可以想象,這個簡單環(huán)境的根本任務是在燈打開的時候在房間里拿到旗子。
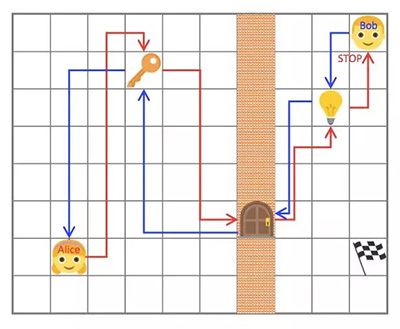
那些任務由 Alice 設定并強迫 Bob 學會與環(huán)境互動。Alice 和 Bob 都有明確的獎勵函數(shù)。Bob 必須將完成任務的時間最小化,而在 Bob 完成了任務的前提下又更費時的時候,Alice 反而能得到更多的獎勵。這些決策的相互作用使他們「自動構(gòu)建起探索的過程」。再次提醒,這是特征學習的自我模擬的另一種實現(xiàn)的想法。
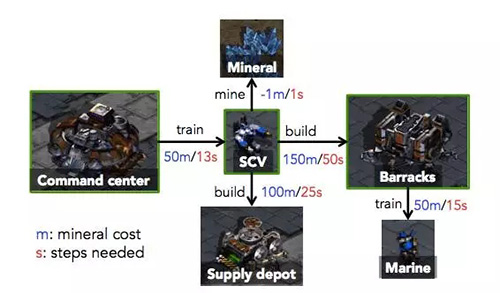
他們在幾種環(huán)境中測試了這個想法,并在星際爭霸的無敵人模式中也嘗試了一下。「目標任務是制造新的機槍兵,為了實現(xiàn)目標,智能體必須按特定的次序進行一系列操作:(i)讓 SCV 去挖礦;(ii)累積足夠的水晶礦,建立一座兵營,以及(iii)一旦兵營建好,開始制造機槍兵。」這其中有多種決策選擇,人工智能可以訓練更多 SCV,讓采礦速度加快,或者修建補給站擴充人口上限。在經(jīng)過 200 步的訓練后,人工智能每建立一個 就能得到加 1 分的獎勵。
雖然完全匹配真實游戲中的狀態(tài)幾乎是不可能的,Bob 成功與否只取決于游戲中的全局狀態(tài),其中包括了每種單位的編號(包含建筑),以及礦物資源的累積程度。因此 Bob 的目標是在自我模擬中,完成 Alice 在最短時間內(nèi)能建造的機槍兵數(shù)量和累積礦物的數(shù)量。在這個方案中,自我模擬確實有助于加快強化學習,并且在收斂行為上表現(xiàn)上,比起強化學習+一個更簡單的決策預訓練的基線方法的組合,要更好:
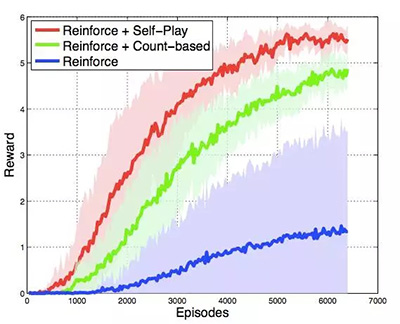
這里要注意的是圖中并沒有顯示決策預訓練的時間消耗。參見論文《Teacher-Student Curriculum Learning》。
***一提,并不是說無監(jiān)督學習就總是困難的,實際上對其行為的測量更為困難。正如 Yoshua Bengio 所說:「我們不知道什么樣的表征才是好的表征。[...] 我們甚至對判定無監(jiān)督學習工作好壞的合適的目標函數(shù)都沒有一個明確的定義。」
實際上,幾乎所有的關(guān)于無監(jiān)督學習都在間接使用監(jiān)督學習或者強化學習去測量其中的特征是否有意義。在無監(jiān)督學習還處在提高訓練質(zhì)量和加快訓練速度以訓練預測模型的階段的時候,這么做是合理的。但是,在經(jīng)過一個視頻和文本必須使用不可見的數(shù)據(jù)部分進行一般表征之后,一切都不同了。這和遷移學習的魯棒性特征的想法如出一轍。
原文:http://giorgiopatrini.org/posts/2017/09/06/in-search-of-the-missing-signals/
【本文是51CTO專欄機構(gòu)“機器之心”的原創(chuàng)譯文,微信公眾號“機器之心( id: almosthuman2014)”】