干貨 | 全面理解無監(jiān)督學習基礎(chǔ)知識
督學習基礎(chǔ)知識")
一、無監(jiān)督學習
無監(jiān)督學習的特點是,模型學習的數(shù)據(jù)沒有標簽,因此無監(jiān)督學習的目標是通過對這些無標簽樣本的學習來揭示數(shù)據(jù)的內(nèi)在特性及規(guī)律,其代表就是聚類。與監(jiān)督學習相比,監(jiān)督學習是按照給定的標準進行學習(這里的標準指標簽),而無監(jiān)督學習則是按照數(shù)據(jù)的相對標準進行學習(數(shù)據(jù)之間存在差異)。以分類為例,小時候你在區(qū)分貓和狗的時候,別人和你說,這是貓,那是狗,最終你遇到貓或狗你都能區(qū)別出來(而且知道它是貓還是狗),這是監(jiān)督學習的結(jié)果。但如果小時候沒人教你區(qū)別貓和狗,不過你發(fā)現(xiàn)貓和狗之間存在差異,應(yīng)該是兩種動物(雖然能區(qū)分但不知道貓和狗的概念),這是無監(jiān)督學習的結(jié)果。
聚類正是做這樣的事,按照數(shù)據(jù)的特點,將數(shù)據(jù)劃分成多個沒有交集的子集(每個子集被稱為簇)。通過這樣的劃分,簇可能對應(yīng)一些潛在的概念,但這些概念就需要人為的去總結(jié)和定義了。
聚類可以用來尋找數(shù)據(jù)的潛在的特點,還可以用來其他學習任務(wù)的前驅(qū)。例如在一些商業(yè)引用中需要對新用戶的類型進行判別,但是“用戶類型”不好去定義,因此可以通過對用戶進行聚類,根據(jù)聚類結(jié)果將每個簇定義為一個類,然后基于這些類訓練模型,用于判別新用戶的類型。
二、聚類的性能度量
聚類有著自己的性能度量,這和監(jiān)督學習的損失函數(shù)類似,如果沒有性能度量,則不能判斷聚類結(jié)果的好壞了。
聚類的性能大致有兩類:一類是聚類結(jié)果與某個參考模型進行比較,稱為外部指標;另一種則是直接考察聚類結(jié)果而不參考其他模型,稱為內(nèi)部指標。
在介紹外部指標之前先作以下定義。對于樣本集合,我們可以給每一個樣本一個單獨的編號,并且我們以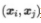 表示編號為i j 的樣本屬于同一個簇,這里 i<j 可以避免重復(fù)。因此有
表示編號為i j 的樣本屬于同一個簇,這里 i<j 可以避免重復(fù)。因此有
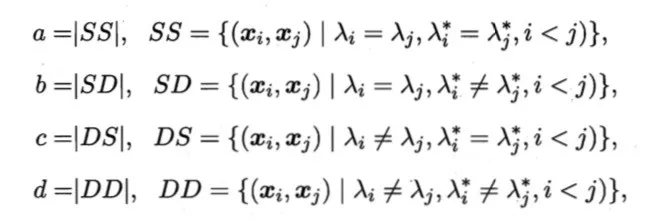
a表示在聚類結(jié)果中樣本i j 屬于同一個簇,而在參考模型中i j 也同屬于一個簇。b表示在聚類結(jié)果中樣本i j 屬于同一個簇,而在參考模型中i j 不同屬于一個簇。c和d同理。以上定義兩兩樣本在聚類結(jié)果和參考模型結(jié)果可能出現(xiàn)的情況。
常用的外部指標如下

以上的性能度量的結(jié)果都在[0,1]區(qū)間中,并且結(jié)果越大,說明性能越好。
倘若沒有可參考的模型,一個好的聚類結(jié)果應(yīng)是類內(nèi)的點都足夠近,類間的點都足夠遠,這就是內(nèi)部指標說要描述的。對于內(nèi)部指標我們需要先做以下定義


常用的內(nèi)部指標有

DBI值越小說明聚類效果好,DI則相反,DI值越大說明聚類效果越好。
三、距離度量
樣本點分布空間中,如果兩個樣本點相距很近,則認為樣本點應(yīng)該屬于同一個簇。如果樣本相距很遠,則不會認為它們屬于同一個簇。當然這里的遠近是一種相對的概念而不是單純的數(shù)值。我們可以使用VDM(Value Difference Metric)距離:

以上表示了屬性u上兩個離散值a與b之間的VDM距離。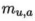 表示屬性u上取值為a的樣本數(shù)
表示屬性u上取值為a的樣本數(shù)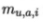 表示在第i個樣本簇中屬性u上取值為a的樣本數(shù),k為樣本簇數(shù)。
表示在第i個樣本簇中屬性u上取值為a的樣本數(shù),k為樣本簇數(shù)。
距離度量在聚類中非常重要,因為距離度量描述的是不同類別的相似度,距離越大相似度越小,由于不同概念之相似度的度量有所不同,在現(xiàn)實任務(wù)中,需要通過樣本確定合適的距離計算公式,這可以通過距離度量學習實現(xiàn)。
四、常見的距離算法
k-means
k均值是常用的快速聚類方法,該方法在學習開始之初,隨機設(shè)置若干個簇心,樣本點隸屬于離它最近的簇心。因此每個簇心會有一個隸屬于它自己的樣本集合。每次迭代,每個簇心找到隸屬于自己的樣本集合,并根據(jù)其隸屬的樣本集合中計算出中心位置(均值),然后簇心移動到此處。直到聚類結(jié)果不發(fā)生改變。k-means對球狀簇比較高效,針對其他的效果較差。
關(guān)于聚類簇心的設(shè)置,現(xiàn)實中我們往往會設(shè)置不同數(shù)量的簇心,通過聚類的性能度量來選擇***的簇心個數(shù)。
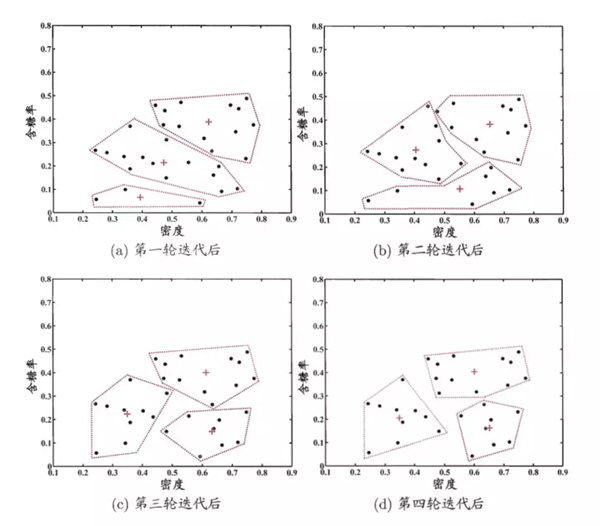
以上是西瓜數(shù)據(jù)集的聚類過程。
學習向量量化(Learin Vector Quantization)
LVQ和K均值算法很像,同樣是通過移動簇心來實現(xiàn)聚類,不同的是LVQ假設(shè)數(shù)據(jù)樣本有類別標記,通過這些監(jiān)督信息輔助聚類。算法過程如下

以上算法的過程可以簡單概括為,如果隨機選擇的點與簇心的類別不對應(yīng)則令簇心遠離該樣本點,否則靠近該樣本點。迭代結(jié)束后對于任意樣本x,它將被劃入與其距離最近的原型向量所代表的簇中。
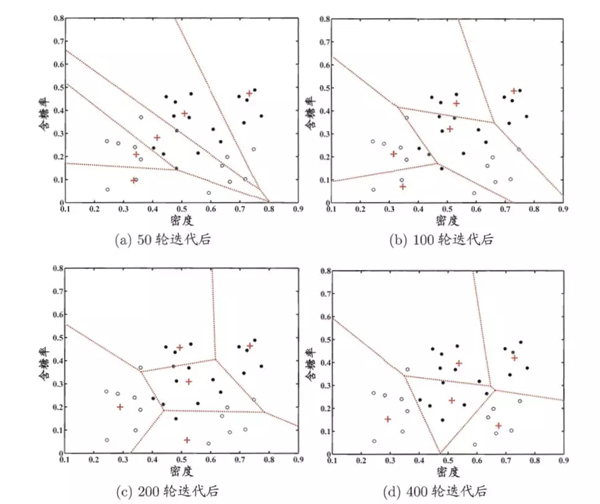
以上是LVQ在西瓜數(shù)據(jù)集聚類的過程。
高斯混合聚類
高斯混合聚類才用概率模型來表達聚類原型,我們可以定義高斯混合分布為
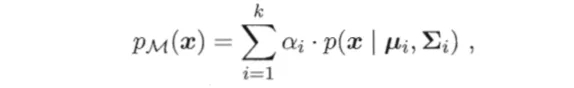
其中  為混合系數(shù)且
為混合系數(shù)且 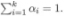 。使用高斯混合聚類其實是假設(shè)樣本是在高斯混合分布中采樣的結(jié)果。對于樣本我們可以通過計算
。使用高斯混合聚類其實是假設(shè)樣本是在高斯混合分布中采樣的結(jié)果。對于樣本我們可以通過計算
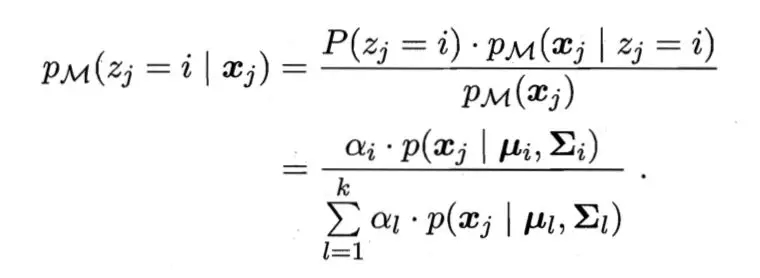
得出某樣本由第i個高斯分布生成的后驗概率,該樣本的類別為使得該概率***的分布的類別。有關(guān)于高斯混合模型的具體介紹,將會與EM算法一起介紹。
密度聚類
顧名思義,密度聚類從樣本密度的角度來考察樣本之間的關(guān)聯(lián)性,其經(jīng)典算法為DBSCAN,該算法通過設(shè)置的鄰域和樣本鄰域內(nèi)最少樣本點數(shù)為標準設(shè)置核心對象,倘若核心對象密度相連則將它們合并到同一簇,因此DBSCAN的聚類結(jié)果的一個簇為***的密度相連的樣本集合。以下是DBSCAN的一些概念的定義:


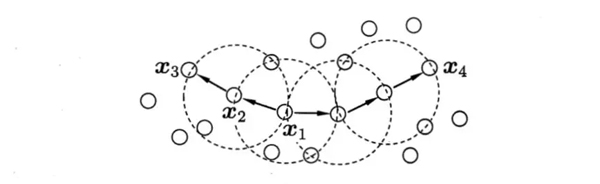
上面MinPts = 3,虛線表示核心對象的鄰域。X1與X2密度直達,X1與X3密度可達X3與X4密度相連。
DBSCAN能夠?qū)⒆銐蚋呙芏鹊膮^(qū)域劃分成簇,并能在具有噪聲的空間數(shù)據(jù)庫中發(fā)現(xiàn)任意形狀的簇。
層次聚類
層次聚類開始時把所有的樣本歸為一類,然后計算出各個類之間的距離,然后合并距離最小的兩個類。從上面的描述來看,層次聚類就像是在用克魯斯卡爾算法建立最小生成樹一樣,不過當層次聚類當前類別數(shù)下降到給定的類別數(shù)是就會終止。這里層次聚類所使用的聚類是不同類別之間的平均距離。
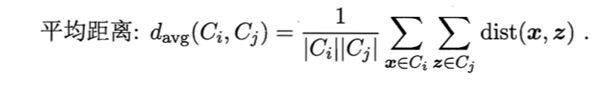
因為層次聚類所需要計算的距離很多,因此層次聚類并不適合在大的數(shù)據(jù)集中的使用。