數(shù)據(jù)缺失的坑,無(wú)監(jiān)督學(xué)習(xí)這樣幫你補(bǔ)了
無(wú)監(jiān)督學(xué)習(xí)(UL)有很多沒(méi)開(kāi)發(fā)的潛力。它是一門(mén)從“未標(biāo)記”數(shù)據(jù)中推導(dǎo)一個(gè)函數(shù)來(lái)描述其隱藏結(jié)構(gòu)的藝術(shù)。但首先,從數(shù)據(jù)中找到其結(jié)構(gòu)是什么意思呢? 讓我們來(lái)看以下兩個(gè)例子:
據(jù)缺失的坑,無(wú)監(jiān)督學(xué)習(xí)這樣幫你補(bǔ)了")
Blobs
氣泡狀分布:這個(gè)簡(jiǎn)單。任何人看到這張圖都會(huì)認(rèn)為它是由三個(gè)不同的簇組成的。如果你對(duì)統(tǒng)計(jì)學(xué)非常熟悉,你可能還會(huì)猜想它由三個(gè)隱藏的高斯分布構(gòu)成。對(duì)一個(gè)新的數(shù)據(jù)樣本,查看它的位置,人們就能推斷出它屬于哪一簇。
據(jù)缺失的坑,無(wú)監(jiān)督學(xué)習(xí)這樣幫你補(bǔ)了")
Wavy hi
波浪分布:這個(gè)就有難度了。它有明確的結(jié)構(gòu),但我怎么教計(jì)算機(jī)提取出這一結(jié)構(gòu)呢?為了讓你更好地理解這個(gè)問(wèn)題,想象一下我找來(lái)1000人,問(wèn)他們?cè)谶@張圖中看到了幾個(gè)簇。結(jié)果很可能是這樣,回答2的人最多,也有人回答3、4,甚至1!
所以說(shuō)對(duì)數(shù)據(jù)的結(jié)構(gòu),連人都無(wú)法達(dá)成共識(shí),那怎么可能教計(jì)算機(jī)學(xué)會(huì)呢?這里的癥結(jié)在于,對(duì)于什么是簇,或者廣義地說(shuō)什么是“結(jié)構(gòu)”,沒(méi)有統(tǒng)一的定義。人們可以研究一下日常生活的某個(gè)方面,看它有沒(méi)有結(jié)構(gòu),但這也會(huì)根據(jù)環(huán)境或其中涉及的人的變化而變化。
很多著名的無(wú)監(jiān)督學(xué)習(xí)算法,比如層次聚類,K-Means,混合高斯模型或隱馬爾可夫模型,對(duì)同一問(wèn)題可能得到不同的答案,依我拙見(jiàn),對(duì)于找結(jié)構(gòu)問(wèn)題,沒(méi)有所謂更好的或更正確的普適方法(真的嗎?又是沒(méi)有免費(fèi)的午餐定理?)
那么讓我們動(dòng)手探索吧——
聚類方法
- K-Means(scikit learn)
- 模糊K-Means(scikit fuzzy)
- 混合高斯模型(scikit learn)
用K-Means算法產(chǎn)生簇通常被稱為“硬劃分”,因?yàn)閷?duì)一個(gè)樣本和一個(gè)簇,只有屬于和不屬于兩種關(guān)系。K-Means的改進(jìn)版模糊K-Means算法是“軟劃分”或“模糊”,因?yàn)橐粋€(gè)樣本對(duì)每個(gè)簇都有隸屬度。基于這些隸屬度來(lái)更新簇的質(zhì)心。
混合高斯模型https://github.com/abriosi/gmm-mml
這個(gè)包是論文Unsupervised learning of finite mixture models(有限混合模型的無(wú)監(jiān)督學(xué)習(xí))中提出的方法,用一個(gè)算法實(shí)現(xiàn)估計(jì)和模型選擇。
數(shù)據(jù)集
1. 占有率檢測(cè):
這是一個(gè)沒(méi)有缺失值的時(shí)間序列數(shù)據(jù)集,因此要人為刻意地進(jìn)行空缺數(shù)據(jù)補(bǔ)全。
這一數(shù)據(jù)集相對(duì)較小,有20560個(gè)樣本和7個(gè)特征,其中一個(gè)模型預(yù)測(cè)變量為是否占有。(二元分類問(wèn)題)。
2. Sberbank俄羅斯房?jī)r(jià)市場(chǎng)數(shù)據(jù)集:
這也是一個(gè)時(shí)序數(shù)據(jù)集,來(lái)自數(shù)月前結(jié)束的Kaggle競(jìng)賽。
將訓(xùn)練數(shù)據(jù)與俄羅斯宏觀經(jīng)濟(jì)和金融部門(mén)的數(shù)據(jù)合并后,得到30471個(gè)樣本,389個(gè)特征,其中一個(gè)是要預(yù)測(cè)的價(jià)格(回歸問(wèn)題)。
它有93列有缺失數(shù)據(jù),有些NaNs(非指定類型數(shù)據(jù))占比很大(> 90%)。
3.子宮頸癌(危險(xiǎn)因素)數(shù)據(jù)集:
這一數(shù)據(jù)集有858個(gè)樣本和32個(gè)特征,4個(gè)目標(biāo)變量(不同醫(yī)學(xué)測(cè)試指標(biāo)的二元輸出)取眾數(shù)轉(zhuǎn)化成1個(gè)目標(biāo)變量。
它有26個(gè)特征有空缺值,有些NaNs(非指定類型數(shù)據(jù))占比很大(> 90%)。
數(shù)據(jù)缺失值補(bǔ)全過(guò)程
先刪去訓(xùn)練集和測(cè)試集中所有含有缺失數(shù)據(jù)的特征。利用留下的特征,對(duì)訓(xùn)練集應(yīng)用聚類算法,并預(yù)測(cè)兩組中每個(gè)樣本的簇。加上刪去的列,計(jì)算按照簇分組后每個(gè)特征的平均值(或均值,如果是定性的話)。所以現(xiàn)在我們有了每個(gè)簇未補(bǔ)全時(shí)的特征的平均值。
據(jù)缺失的坑,無(wú)監(jiān)督學(xué)習(xí)這樣幫你補(bǔ)了")
“普通”和加權(quán)補(bǔ)全方法:
- 這里“普通補(bǔ)全”指的是每個(gè)樣本都用以計(jì)算其所屬簇的平均值/眾數(shù)。
- 加權(quán)方法則用樣本對(duì)每個(gè)簇的“歸屬度”。比如,在混合高斯模型(GMM)中,歸屬度是樣本屬于各個(gè)簇的可能性,在K-Means方法中,歸屬度基于樣本與各個(gè)簇的質(zhì)心的距離。
評(píng)分方法
- 除標(biāo)準(zhǔn)化之外,幾乎沒(méi)對(duì)數(shù)據(jù)集做任何處理。
- 對(duì)于時(shí)間序列數(shù)據(jù)集,從***個(gè)樣本算起對(duì)時(shí)間標(biāo)記排序,在占有率檢測(cè)數(shù)據(jù)集中轉(zhuǎn)化成按秒計(jì)數(shù),同理在俄羅斯房?jī)r(jià)市場(chǎng)數(shù)據(jù)集中按天計(jì)數(shù)。
- 完成插補(bǔ)后,用XGBoost在測(cè)試集進(jìn)行評(píng)分。用負(fù)對(duì)數(shù)損失和均方誤差作為評(píng)分度量。
得到簇的數(shù)目
最初考慮了“肘”或者說(shuō)“膝”方法。當(dāng)簇的數(shù)量取值在一定范圍內(nèi)時(shí),畫(huà)出不同聚簇方法的得分并從圖中尋找肘部。
據(jù)缺失的坑,無(wú)監(jiān)督學(xué)習(xí)這樣幫你補(bǔ)了")
比如,上圖的肘部在8到12之間。缺點(diǎn)是這種方法需要人的參與來(lái)選擇肘部,而實(shí)際應(yīng)用上應(yīng)該自動(dòng)。但自動(dòng)選擇肘部效果并不理想,因此可以考慮一種新方法。
通過(guò)交叉驗(yàn)證,得到了一種比較有效但計(jì)算成本昂貴的方法。它是怎么工作的呢?首先選擇一個(gè)分類器,然后對(duì)于一系列質(zhì)心數(shù)目,進(jìn)行無(wú)監(jiān)督插補(bǔ),并用該分類器進(jìn)行K-fold交叉驗(yàn)證。***選擇在交叉驗(yàn)證中表現(xiàn)更好的質(zhì)心數(shù)目。
結(jié)果
在條形圖中,用紅線標(biāo)記平均值插補(bǔ)的分?jǐn)?shù),以便進(jìn)行比較。
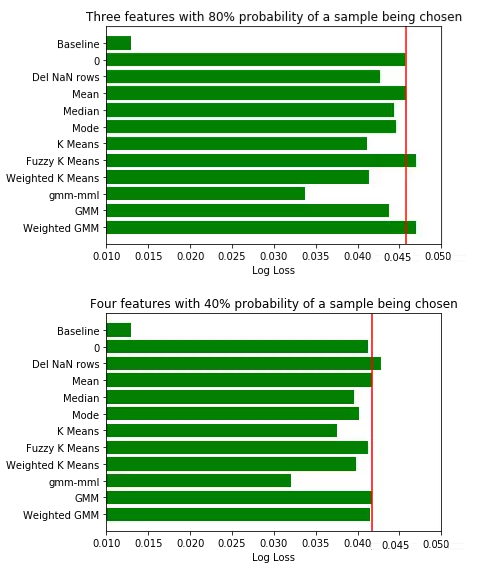
占有率檢測(cè)數(shù)據(jù)集:
誠(chéng)如之前提到的,這個(gè)數(shù)據(jù)集并沒(méi)有缺失數(shù)據(jù),所以只能模擬補(bǔ)缺行為。
對(duì)將要補(bǔ)缺的數(shù)據(jù)特征和樣本應(yīng)當(dāng)謹(jǐn)慎挑選。不僅特別選擇了數(shù)據(jù)特征,而且對(duì)是否選擇樣本設(shè)定了概率。如果概率為0.5,有50%的機(jī)會(huì)該樣本將被丟棄。由于每次填補(bǔ)缺失值的樣本選擇都不同,我們將每三輪不同樣本補(bǔ)缺的評(píng)分結(jié)果取均值,***再對(duì)所有結(jié)果取均值。
據(jù)缺失的坑,無(wú)監(jiān)督學(xué)習(xí)這樣幫你補(bǔ)了")
據(jù)缺失的坑,無(wú)監(jiān)督學(xué)習(xí)這樣幫你補(bǔ)了")
房產(chǎn)市場(chǎng)數(shù)據(jù)集:
由于該數(shù)據(jù)集的數(shù)據(jù)量過(guò)大,怎樣在有限的內(nèi)存中完成聚類分析值得研究一番。我們放棄了使用全量數(shù)據(jù)做歸類計(jì)算的打算,隨機(jī)抽取了適合電腦內(nèi)存的樣本數(shù)據(jù)量(本次測(cè)試我選用了5000條記錄)。
在原始數(shù)據(jù)集中使用隨機(jī)抽樣的方法抽取樣本,也盡量保持了數(shù)據(jù)的時(shí)間結(jié)構(gòu)。樣本的數(shù)據(jù)量越大,反映的時(shí)間結(jié)構(gòu)越準(zhǔn)確。
據(jù)缺失的坑,無(wú)監(jiān)督學(xué)習(xí)這樣幫你補(bǔ)了")
子宮頸癌數(shù)據(jù)集:
據(jù)缺失的坑,無(wú)監(jiān)督學(xué)習(xí)這樣幫你補(bǔ)了")
結(jié)果分析
根據(jù)結(jié)果,在數(shù)據(jù)分群的基礎(chǔ)上選擇補(bǔ)缺方式的表現(xiàn)比一般方法要好。
對(duì)于占有率檢測(cè)數(shù)據(jù)集,表現(xiàn)最優(yōu)的是GMM_MML分類算法,而對(duì)于房產(chǎn)市場(chǎng)數(shù)據(jù)和宮頸癌數(shù)據(jù)集,K_Means聚類算法更好。我們并沒(méi)有對(duì)房產(chǎn)市場(chǎng)數(shù)據(jù)使用GMM_MML算法,因?yàn)樗嗵卣鳎鴧f(xié)方差的計(jì)算對(duì)于多特征數(shù)據(jù)比多樣本量數(shù)據(jù)更加困難。
在增加占有率檢測(cè)數(shù)據(jù)集的缺失數(shù)據(jù)后,整體上可以觀測(cè)到,無(wú)監(jiān)督的補(bǔ)缺方法比均值補(bǔ)缺表現(xiàn)要好。因此,當(dāng)數(shù)據(jù)集有缺失值占比較高時(shí),先探索數(shù)據(jù)結(jié)構(gòu)再補(bǔ)缺方法反而形成一種優(yōu)勢(shì)。
大家會(huì)注意到,當(dāng)使用檢測(cè)數(shù)據(jù)集的缺失數(shù)據(jù)特征從2個(gè)增加到4個(gè),且用于聚類的特征數(shù)量減少時(shí),無(wú)監(jiān)督補(bǔ)缺方法比均值補(bǔ)缺表現(xiàn)稍好。這種反常的現(xiàn)象可能是由于特定的數(shù)據(jù)集和選擇的特征造成的。
同時(shí),自然的,當(dāng)缺失數(shù)據(jù)占比增加時(shí),評(píng)分與基線分?jǐn)?shù)的差距越來(lái)越大。
在三種K_Means算法中,普通型表現(xiàn)優(yōu)于其他兩種。這種算法每次迭代的計(jì)算量也最小,是較佳選擇。
基于GMM方法的表現(xiàn)優(yōu)于K-Means算法,這一現(xiàn)象十分合理,因?yàn)镵-Means算法是GMM算法在歐式距離計(jì)算上的啟發(fā)式算法。歐式距離能有效測(cè)量低維數(shù)據(jù),但在高維空間上,其含義開(kāi)始失真。如想了解更多信息,請(qǐng)看這里(https://stats.stackexchange.com/questions/99171/why-is-euclidean-distance-not-a-good-metric-in-high-dimensions/)。GMM算法是基于樣本所屬概率密度函數(shù)的可能性,能更好的衡量高維空間距離。
結(jié)論
盡管基于聚類的缺失值補(bǔ)充算法沒(méi)有明顯高過(guò)其他算法的優(yōu)勝者,我們還是建議選擇基于GMM的算法。
想找到模型混合的較佳數(shù)量,使用交叉驗(yàn)證法會(huì)更好。盡管AIC準(zhǔn)則和BIC準(zhǔn)則需要大量計(jì)算,他們可以用于檢測(cè)模型混合數(shù)量的范圍。較佳數(shù)量會(huì)令準(zhǔn)則值達(dá)到最小。
計(jì)算協(xié)方差矩陣有很多方法。這里介紹兩種最常使用的:
據(jù)缺失的坑,無(wú)監(jiān)督學(xué)習(xí)這樣幫你補(bǔ)了")
- 對(duì)角協(xié)方差:每個(gè)部分都有自己的對(duì)角矩陣。
- 全協(xié)方差:這種協(xié)方差用于統(tǒng)計(jì)檢測(cè)。每個(gè)部分有自己的廣義協(xié)方差矩陣。
數(shù)據(jù)集中如果特征維度太多,使用GMM算法計(jì)算協(xié)方差矩陣,可能因?yàn)闃颖玖坎蛔阌?jì)算錯(cuò)誤,也可能因?yàn)槭褂萌繑?shù)據(jù)耗時(shí)太久。因此建議使用對(duì)角協(xié)方差,更加平衡模型大小和計(jì)算質(zhì)量。
如果數(shù)據(jù)量大大超過(guò)內(nèi)存容量,應(yīng)當(dāng)從訓(xùn)練集中生成隨機(jī)樣本做聚類分析。
均值補(bǔ)缺的表現(xiàn)沒(méi)有比基于聚類補(bǔ)缺方法差很多,因此也可以考慮使用。
后續(xù)工作
數(shù)據(jù)整理也可以嘗試新方法:不再丟棄有缺失數(shù)據(jù)的特征,可以用均值或中位數(shù)填補(bǔ)缺失值,對(duì)修改后的數(shù)據(jù)集使用聚類分析。補(bǔ)缺可以在每個(gè)樣本被標(biāo)記后完成。
Finite Mixture Models (McLachlan和Peel著)這本書(shū)中提到NEC和ICL都是很好的方法。
也有更多無(wú)監(jiān)督方法值得研究檢測(cè),例如,不同距離度量方法下的分級(jí)聚類。當(dāng)然,普適的方法可能并不存在,畢竟沒(méi)有免費(fèi)的午餐。