談談Spark與Spark-Streaming關系
作者:佚名
spark程序是使用一個spark應用實例一次性對一批歷史數據進行處理,spark streaming是將持續不斷輸入的數據流轉換成多個batch分片,使用一批spark應用實例進行處理,側重點在Steaming上面。
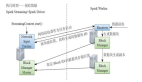
spark程序是使用一個spark應用實例一次性對一批歷史數據進行處理,spark streaming是將持續不斷輸入的數據流轉換成多個batch分片,使用一批spark應用實例進行處理,側重點在Steaming上面。我們常說的Spark-Streaming依賴了Spark Core的意思就是,實際計算的核心框架還是spark。我們還是上一張老生常談的官方圖:
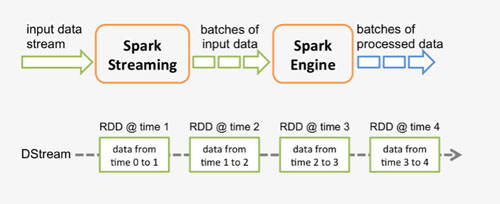
從原理上看,我們將spark-streaming轉變為傳統的spark需要什么?
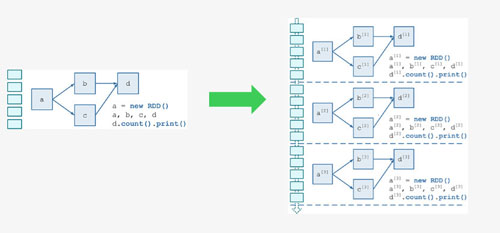
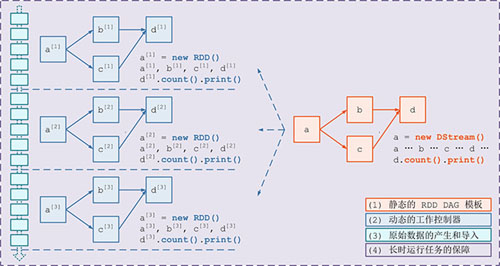
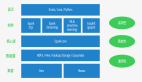
需要構建4個東西:
一個靜態的 RDD DAG 的模板,來表示處理邏輯;
一個動態的工作控制器,將連續的 streaming data 切分數據片段,并按照模板復制出新的 RDD
DAG 的實例,對數據片段進行處理;
Receiver進行原始數據的產生和導入;Receiver將接收到的數據合并為數據塊并存到內存或硬盤中,供后續batch RDD進行消費;對長時運行任務的保障,包括輸入數據的失效后的重構,處理任務的失敗后的重調。
至于上述過程具體怎么實現,我們會在spark-streaming源碼分析的文章中一一解決。本文中圖片文字來自于網絡。
責任編輯:武曉燕
來源:
oschina博客