Spark Streaming原理剖析
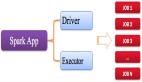
1.初始化與集群上分布接收器 圖8-12所示為Spark Streaming執行模型從中可看到數據接收及組件間的通信。
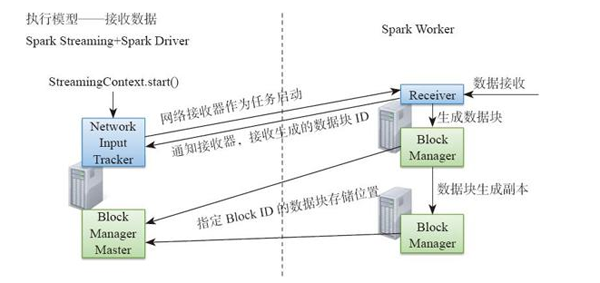
初始化的過程主要可以概括為以下兩點。
1)調度器的初始化。
2)將輸入流的接收器轉化為RDD在集群打散,然后啟動接收器集合中的每個接收器。
下面通過具體的代碼更深入地理解這個過程。
(1)NetworkWordCount示例 本例以NetworkWordCount作為研究Spark Streaming的入口程序。
- object NetworkWordCount {
- def main(args: Array[String]) {
- if (args.length < 2) {
- System.err.println("Usage: NetworkWordCount <hostname> <port>"))
- System.exit(1)
- }
- StreamingExamples.setStreamingLogLevels()
- val sparkConf = new SparkConf().setAppName("NetworkWordCount")
- /*創建StreamingContext對象,形成整個程序的上下文*/
- val ssc = new StreamingContext(sparkConf, Seconds(1))
- /*通過socketTextStream接收源源不斷地socket文本流*/
- val lines = ssc.socketTextStream(args(0), args(1).toInt, StorageLevel.MEMORY_AND_DISK_SER)
- val words = lines.flatMap(_.split(" "))
- val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
- wordCounts.print()
- ssc.start()
- ssc.awaitTermination()
- }
- }
(2)進入scoketTextStream
- def socketTextStream(hostname:String,port:Int,storageLevel:StorageLevel = StorageLevel.MEMORY_AND_DISK_SER_2):ReceiverInputDStream[String] = {
- /*內部實際調用的socketStream方法 */
- socketStream[String](hostname, port, SocketReceiver.bytesToLines, storageLevel)
- }
- /*進入socketStream方法 */
- def socketStream[T: ClassTag](hostname:String, port:Int, converter: (InputStream) => Iterator[T], storageLevel: StorageLevel ): ReceiverInputDStream[T] = {
- /*此處初始化SocketInputDStream對象 */
- new SocketInputDStream[T](this, hostname, port, converter, storageLevel)
- }
(3)初始化SocketInputDStream 在之前的Spark Streaming介紹中,讀者已經了解到整個Spark Streaming的調度靈魂就是DStream的DAG,可以將這個DStream DAG類比Spark中的RDD DAG,而DStream類比RDD,DStream可以理解為包含各個時間段的一個RDD集合。SocketInputDStream就是一個DStream。
- private[streaming] class SocketInputDStream[T: ClassTag](
- @transient ssc_ : StreamingContext,host:String,port:Int, bytesToObjects:InputStream => Iterator[T],storageLevel:StorageLevel)extends ReceiverInputDStream[T](ssc_) {
- def getReceiver(): Receiver[T] = {
- new SocketReceiver(host,port,bytesToObjects,storageLevel)
- }
- }
(4)觸發StreamingContext中的Start()方法上面的步驟基本完成了Spark Streaming的初始化工作。類似于Spark機制,Spark Streaming也是延遲(Lazy)觸發的,只有調用了start()方法,才真正地執行了。
- private[streaming] val scheduler = new JobScheduler(this)
- /*StreamingContext中維持著一個調度器*/
- def start(): Unit = synchronized {
- ……
- /*啟動調度器*/
- scheduler.start()
- ……
- }
(5)JobScheduler.start()啟動調度器在start方法中初始化了很多重要的組件。
- def start(): Unit = synchronized {
- ……
- /*初始化事件處理Actor,當有消息傳遞給Actor時,調用processEvent進行事件處理*/
- eventActor = ssc.env.actorSystem.actorOf(Props(new Actor {
- def receive = {
- case event: JobSchedulerEvent => processEvent(event)
- }
- }), "JobScheduler")
- /*啟動監聽總線*/
- listenerBus.start()
- receiverTracker = new ReceiverTracker(ssc)
- /*啟動接收器的監聽器receiverTracker*/
- receiverTracker.start()
- /*啟動job生成器*/
- jobGenerator.start()
- ……
- }
(6)ReceiverTracker類
- /*進入ReceiverTracker查看*/
- private[streaming] class ReceiverTracker(ssc: StreamingContext) extends Logging {
- val receiverInputStreams = ssc.graph.getReceiverInputStreams()
- def start() = synchronized {
- ……
- val receiverExecutor = new ReceiverLauncher()
- ……
- if (!receiverInputStreams.isEmpty) {
- /*初始化ReceiverTrackerActor */
- actor = ssc.env.actorSystem.actorOf(Props(new ReceiverTrackerActor), "ReceiverTracker")
- /*啟動ReceiverLauncher()實例,(7)中進行介紹*/
- receiverExecutor.start()
- ……
- }
- }
- /*讀者可以先參考ReceiverTrackerActor的代碼查看實現注冊Receiver和注冊Block元數據信息的功能。 */
- private class ReceiverTrackerActor extends Actor {
- def receive = {
- /*接收注冊receiver的消息,每個receiver就是一個輸入流接收器,Receiver分布在Worker節點,一個Receiver接收一個輸入流,一個Spark Streaming集群可以有多個輸入流 */
- case RegisterReceiver(streamId, typ, host, receiverActor) => registerReceiver(streamId, typ, host, receiverActor, sender)
- sender ! true case AddBlock(receivedBlockInfo) => addBlocks(receivedBlockInfo)
- ……
- }
- }
(7)receivelauncher類,在集群上分布式啟動接收器
- class ReceiverLauncher {
- ……
- @transient val thread = new Thread() {
- override def run() {
- ……
- /*啟動ReceiverTrackerActor已經注冊的Receiver*/
- startReceivers()
- ……
- }
- }
- }
下面進入startReceivers方法,方法中將Receiver集合轉變為RDD,從而在集群上打散,分布式分布。如圖8-13所示,一個集群可以分布式地在不同的Worker節點接收輸入數據流。
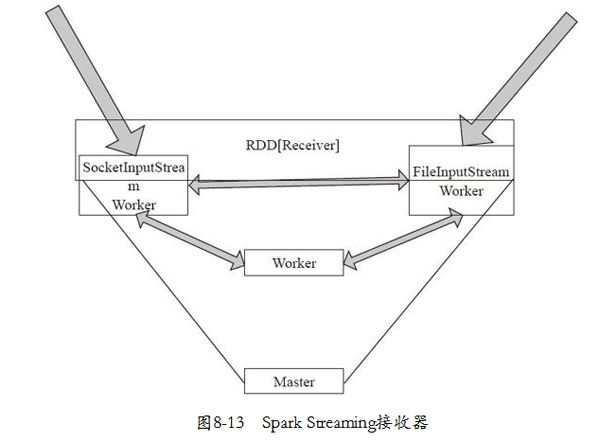
- private def startReceivers() {
- /*獲取之前配置的接收器 */
- val receivers = receiverInputStreams.map(nis => {
- val rcvr = nis.getReceiver()
- rcvr.setReceiverId(nis.id)
- cvr
- })
- ……
- /* 創建并行的在不同Worker節點分布的receiver集合 */
- val tempRDD = if (hasLocationPreferences) {
- val receiversWithPreferences = receivers.map(r => (r, Seq(r.preferredLocation.get)))
- ssc.sc.makeRDD[Receiver[_]](receiversWithPreferences)
- } else {
- /*在這里創造RDD相當于進入SparkContext.makeRDD,此經典之處在于將receivers集合作為一個RDD [Receiver]進行分區。即使只有一個輸入流,按照分布式分區方式,也是將輸入分布在Worker端,而不在Master*/
- ssc.sc.makeRDD(receivers, receivers.size)
- /*調用Sparkcontext中的makeRDD方法,本質是調用將數據分布式化的方法parallelize*/
- /* def makeRDD[T: ClassTag](seq: Seq[T], numSlices: Int = defaultParallelism): //RDD[T] = { parallelize(seq, numSlices) */
- /*在RDD[Receiver[_]]每個分區的每個Receiver 上都同時啟動,這樣其實Spark Streaming可以構建大量的分布式輸入流 */
- val startReceiver = (iterator: Iterator[Receiver[_]]) => {
- if (!iterator.hasNext) {
- throw new SparkException( "Could not start receiver as object not found.")
- }
- val receiver = iterator.next()
- /*此處的supervisorImpl是一個監督者的角色,在下面的內容中將會剖析這個對象的作用 */
- val executor = new ReceiverSupervisorImpl(receiver, SparkEnv.get)
- executor.start()
- executor.awaitTermination()
- }
- /*將receivers的集合打散,然后啟動它們 */
- ……
- ssc.sparkContext.runJob(tempRDD, startReceiver)
- ……
- }
2.數據接收與轉化
在“1.初始化與集群上分布接收器”中介紹了,receiver集合轉換為RDD在集群上分布式地接收數據流。那么每個receiver是怎樣接收并處理數據流的呢?Spark Streaming數據接收與轉化的示意圖如圖8-14所示。圖8-14的主要流程如下。
1)數據緩沖:在Receiver的receive函數中接收流數據,將接收到的數據源源不斷地放入BlockGenerator.currentBuffer。
2)緩沖數據轉化為數據塊:在BlockGenerator中有一個定時器(recurring timer),將當前緩沖區中的數據以用戶定義的時間間隔封裝為一個數據塊Block,放入BlockGenerator的blocksForPush隊列中。
3)數據塊轉化為Spark數據塊:在BlockGenerator中有一個BlockPushingThread線程,不斷地將blocksForPush隊列中的塊傳遞給Blockmanager,讓BlockManager將數據存儲為塊,讀者可以在本書的Spark IO章節了解Spark的底層存儲機制。BlockManager負責Spark中的塊管理。
4)元數據存儲:在pushArrayBuffer方法中還會將已經由BlockManager存儲的元數據信息(如Block的ID號)傳遞給ReceiverTracker,ReceiverTracker將存儲的blockId放到對應StreamId的隊列中。 上面過程中涉及最多的類就是BlockGenerator,在數據轉化的過程中,其扮演著不可或缺的角色。
- private[streaming] class BlockGenerator( listener: BlockGeneratorListener, receiverId: Int, conf: SparkConf ) extends Logging
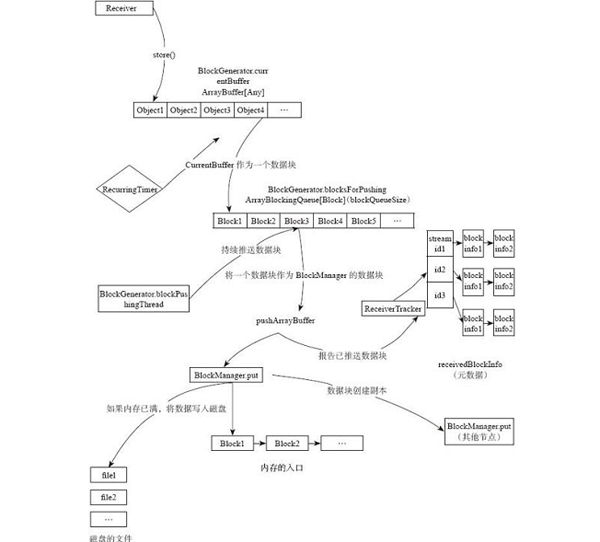
感興趣的讀者可以參照圖8-14中的類和方法更加具體地了解機制。由于篇幅所限,這個數據生成過程的代碼不再具體剖析。
【本文為51CTO專欄作者“王森豐”的原創稿件,轉載請注明出處】