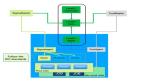
阿里雙11數據庫計算存儲分離與離在線混布
“如何做到支撐32.5萬筆/秒交易的同時降低數據庫成本?”
一、背景
隨著阿里集團電商、物流、大文娛等業務的蓬勃發展,數據庫實例以及數據存儲規模不斷增長,在傳統基于單機的運維以及管理模式下,遇到非常多的困難與挑戰,主要歸結為:
- 機型采購與預算問題
在單機模式下計算資源(CPU和內存)與存儲資源(主要為磁盤或者SSD)存在著不可調和的沖突;計算與存儲資源綁定緊密,無法進行單獨預算。數據庫存儲時,要么計算資源達到瓶頸,要么是存儲單機存儲容量不足。這種綁定模式下,注定了有一種資源必須是浪費的。
- 調度效率問題
在計算與存儲綁定的情況下,計算資源無法做無狀態調度,導致無法實現大規模低成本調度,也就無法與在大促與離線資源進行混布。
- 大促成本問題
在計算資源無法做到調度后,離線混布就不再可能;為了大促需要采購更多的機器,大促成本上漲嚴重。
因此,為了解決諸多如成本,調度效率等問題,2017年***對數據庫實現計算存儲分離;計算存儲分離后,再將計算節點與離線資源混布,達到節省大促成本的目的。
2017年數據庫計算存儲分離,
使得數據庫進行大規模無狀態化容器調度成為可能!
使得數據庫與離線業務混布成為可能!
使得低成本支持大促彈性成為可能!
在高吞吐下,總存儲集群整體RT表現平穩,與離線資源聯合***發力,最終***完成2017年“11.11”大促10%的交易支撐;
并為明年全面擁抱計算存儲分離與大規模離在線混布,打下堅實的基礎。
二、計算存儲分離
在所有業務中,數據庫的計算存儲分離最難,這是大家公認的。因為數據庫對于存儲的穩定性以及單路端到端的時延有著***的要求:
1. 存儲穩定性
在分布式存儲的穩定性方面,我們做了非常多的有意探索,并且逐一落地。這些新技術的落地,使得數據庫計算存儲分離成為可能:
- 單機failover
單機failover我們做到業界的***,5s內完成fo,對整體集群的影響在4%以內(以集群規模24臺為例,集群機器越多,影響越小)。另外,我們對分布式存儲的狀態機進行加速優化,使得基于paxos的選舉在秒級內進行集群視圖更新推送。
- 長尾時延優化
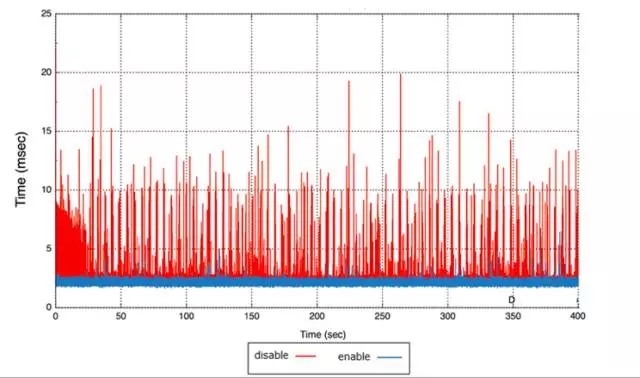
計算存儲分離后,所有的IO都變成了網絡IO,因此對于單路IO時延影響的因素非常多,如網絡抖動,慢盤,負載等,而這些因素也是不可避免的。我們設計了“副本達成多數寫入即返回的策略(commit majority feature)”,能夠有效地使長尾時延抖動做到合理的控制,以滿足業務的需求。
以下是commit majority feature開起前后的效果對比。其中“藍色”為優化后的長尾時延,“紅色”為優化前長尾時延,效果非常顯著。
- 流控
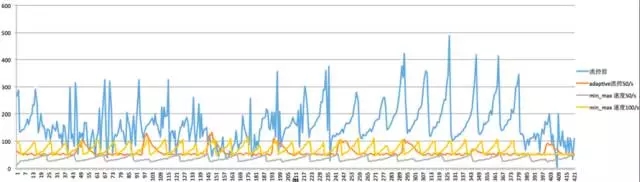
我們實現了基于滑動窗口的流控功能,使得集群后臺活動(如backfill和recovery)能根據當前的業務流量進行自適配的調整,在業務與后臺數據恢復之間做到***平衡。
一般如果集群后端活動太低,會影響數據恢復,這會提高多盤故障的概率,降低了數據的可靠性。我們經過優化后,通過滑動窗口機制,做到了前后端數據寫入的速動,在不影響業務寫入的情況下,盡***可能提高數據恢復速度,保證多副本數據的完整性。
提高數據重平衡的速度,也是為了保證整個集群的性能。因為一出現數據傾斜時,部分盤的負載將變大,從而會影響整個集群的時延和吞吐。
流控效果如下:
- 高可用部署
在高可用部署上,我們引入的故障域的概念。多個數據副本存儲在多個故障域,分布到至少4個RACK以上的機架上,用于保障底層機柜電源以及網絡交換設備引起的故障等。
為了能夠更好的理解數據副本存儲位置(data locality),需要知道數據散射度(scatter width)的概念。怎么來理解數據散射度?
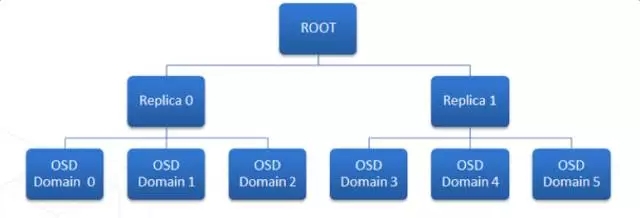
舉個例子:我們定義三個copy set(存放的都是不同的數據):{1,2,3},{4,5,6},{7,8,9}。任意一組copy set中存放的數據沒有重復,也就是說一份數據的三個副本分別放置在:{1,4,7}或者{2,5,8}或者{3,6,9}。那么這個時候,其數據散射度遠小于隨機組合的C(9,3)。
隨機組合時,任意3臺機器Down機都會存在數據丟失。而采用此方案后,只有當{1,4,7}或者{2,5,8}或者{3,6,9}其中的任意一個組合不可用時,才會影響高可用性,才會有數據丟失。
綜上可知,我們引入copy set的目標就是盡量的降低數據散射度“S“。下圖中兩組replica set,其中每一組的三個副本分別放置到不同的RACK中。
我們的優化還有很多,這里不再一一列舉。
2. 數據庫吞吐優化
當所有的IO都變成網絡IO后,我們要做的就是如何減少單路IO的延遲,當然這個是分布式存儲以及網絡要解的問題。
分布式存儲需要優化自身的軟件stack以及底層SPDK的結合等。
而網絡層則需要更高帶寬以及低時延技術,如25G TCP或者25G RDMA,或者100G等更高帶寬的網絡等。
但是我們可以從另外一個角度來考慮問題,如何在時延一定的情況下,提高并發量,從而來提高吞吐。或者說在關鍵路徑上減少IO調用的次數,從而從某種程度上提高系統的吞吐。
大家知道,影響數據庫事務數的最關鍵因素就是事務commit的速度,commit的速度依賴于寫REDO時的IO吞吐。所謂的REDO也就是大家熟知的WAL(Write Ahead Log)日志。
在臟數據flush回存儲時,日志必須先落地,這是因為數據庫的Crash Recovery是重度以來于此的。在recovery階段,數據庫先利用redo進行roll forward;再利用undo進行roll backward,***再撤銷用戶未提交的事務。
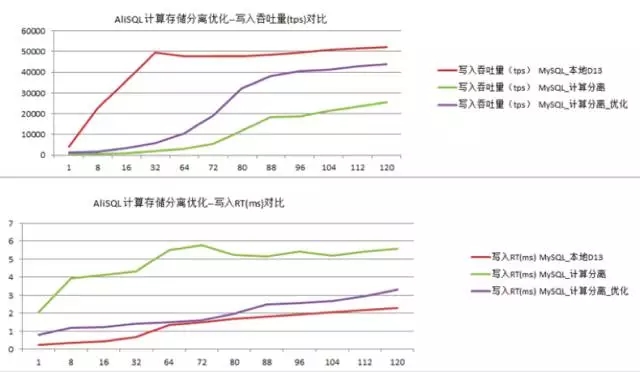
因此,存儲計算分離下,要想在單路IO時延一定時提高吞吐,就必須要優化commit提交時的效率。我們通過優化redo的寫入方式,讓整個提高吞吐100%左右,效果如下:
另外,也可以優化redo group commit的大小,結合底層存儲stripe能力,做并發與吞吐優化。
備注:”D13”是一種已經做過raid的SATASSD
3. 數據庫原子寫
在數據庫內存模型中,數據頁通常是以16K做為一個bufferpage來管理的。當內核修改完數據之后,會有專門的“checkpoint”線程按一定的頻率將Dirty Page flush到磁盤上。我們知道,通常os的page cache是4K,而一般的文件系統block size也是4K。所以一個16k和page會被分成4個4k的os filesystem block size來存儲,物理上不能保證連續性。
那么會帶來一個嚴重的問題,就是當fsync語義發出時,一個16k的pageflush,只完成其中的8k,而這個時候client端crash,不再會有重試;那么整個fsync就只寫了一半,fsync語義被破壞,數據不完整。上面的這個場景,我們稱之為“partial write”。
對于MySQL而言,在本地存儲時,使用Double Write Buffer問題不大。但是如果底層變成網絡IO,IO時延變高時,會使MySQL的整體吞吐下降,而Double Write Buffer會加重這個影響。
我們實現了原子寫,關閉掉Double Write Buffer,從而在高并發壓力及高網絡IO時延下,讓吞吐至少提高50%以上。
4. 網絡架構升級
分布式存儲,對于網絡的帶寬要求極高,我們引入了25G網絡。高帶寬能更好的支持阿里集團的大促業務。另外,對于存儲集群后臺的活動,如數據重平衡以及恢復都提供了有力的保障。
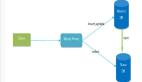
三、離在線混布
計算存儲分離后,離在線混布成為可能;今年完成數據庫離在線混布,為2017年大促節省了計算資源成本。
在與離線混布的方案中,我們對數據庫與離線任務混跑的場景進行了大量的測試。
實踐證明,數據庫對時延極度敏感,所以為了達到數據庫混布的目的,我們采用了以下的隔離方案:
- CPU與內存隔離技術
CPU的L3是被各個核共享的,如果在一個socket內部進行調度,會對數據庫業務有抖動。因此,在大促場景下,我們會對CPU進行獨立socket 綁定,避免L3 cache干擾;另外,內存不超賣。當然,大促結束后,在業務平峰時,可以擇機進行調度和超賣。
- 網絡QOS
我們對數據庫在線業務進行網絡打標,NetQoS中將數據庫計算節點的所有通信組件加入到高優先級group中。
- 基于分布式存儲的彈性效率
基于分布式存儲,底層分布式存儲支持多點mount,用于將計算節點快速彈性到離線機器。
另外,數據庫Buffer Pool可以進行動態擴容。大促ODPS任務撤離,DB實例Buffer Pool擴容;大促結束后,Buffer Pool回縮到平峰業務時的大小。
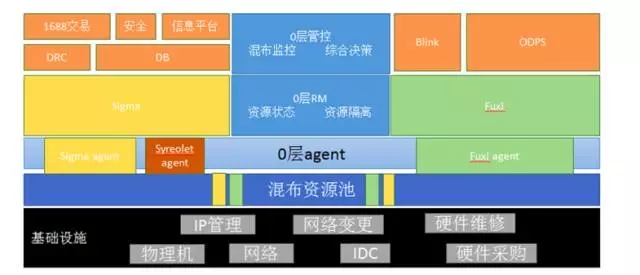
以下是今年離在線混布的部署圖:
四、雙11大促求證
我們拿了其中一個中等壓力的數據庫的業務,其吞吐達到將近3w tps,RT在1ms以內,基本上與本地相當,很好的支撐了2017年大促。
這就是我們今年所做的諸多技術創新的結果。
五、展望
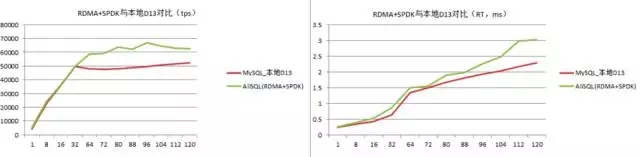
目前我們正在進行軟硬件結合(RDMA,SPDK)以及上層數據庫引擎與分布式存儲融合優化,性能將會超出傳統SATA SSD本地盤的性能。
RDMA和SPDK的特點就是kernel pass-by。未來,我們數據庫將引入全用戶態IO Stack,從計算節點到存儲節點使用用戶態技術,更能充分滿足集團電商業務對高吞吐低時延的***要求。
下面是我們進行測試的一組數據,其中本地用的是SATA SSD,并且做了raid,但是其性能略低于基于RDMA和SPDK的分布式存儲。
這些網絡和硬件技術的發展,將會給“云計算”帶來更多的可能性,也會給真正的“云計算”新的商業模式帶來更多憧憬,而我們已經在這條陽光的大道上。
歡迎有更多的存儲及數據庫內核專家一起參與進來,一起攜手邁進未來。
【引用】
[1] Copysets:Reducing the Frequency of Data Loss in Cloud Storage
[2] CRUSH: Controlled,Scalable, Decentralized Placement of Replicated Data