什么是Apache Spark?數據分析平臺如是說
自從 Apache Spark 2009 年在 U.C. Berkeley 的 AMPLab 默默誕生以來,它已經成為這個世界上最重要的分布式大數據框架之一。Spark 可以用多種方式部署,它為 Java、Scala、Python,和 R 編程語言提供了本地綁定,并且支持 SQL、流數據、機器學習,和圖處理。你將會發現它被銀行、電信公司、游戲公司、政府,和所有如 Apple、Facebook、IBM,和 Microsoft 等主要的科技巨頭公司使用。

非常好,Spark 可以運行在一個只需要在你集群中的每臺機器上安裝 Apache Spark 框架和 JVM 的獨立集群模式。然而,你將更有可能做的是,希望利用資源或集群管理系統來幫你按需分配工作。 在企業中,這通常意味著在 Hadoop YARN (這是 Cloudera 和 Hortonworks 分配運行 Spark 任務的方式 )上運行。盡管 work 是在增加了本地支持的 Kubernetes 上執行,但是 Apache Spark 也可以在 Apache Mesos 上運行。
如果你追求一個有管理的解決方案,那么可以發現 Apache Spark 已作為 Amazon EMR、Google Cloud Dataproc, 和 Microsoft Azure HDInsight 的一部分。雇傭了 Apache Spark 創始人的公司 Databricks 也提供了 Databricks 統一分析平臺,這個平臺是一個提供了 Apache Spark 集群,流式支持,集成了基于 Web 的筆記本開發,和在標準的 Apache Spark 分布上優化了云的 I/O 性能的綜合管理服務。
值得一提的是,拿 Apache Spark 和 Apache Hadoop 比是有點不恰當的。目前,在大多數 Hadoop 發行版中都包含 Spark 。但是由于以下兩大優勢,Spark 在處理大數據時已經成為***框架,超越了使 Hadoop 騰飛的舊 MapReduce 范式。
***個優勢是速度。Spark 的內存內數據引擎意味著在某些情況下,它執行任務的速度比 MapReduce 快一百倍,特別是與需要將狀態寫回到磁盤之間的多級作業相比時更是如此。即使 Apache Spark 的作業數據不能完全包含在內存中,它往往比 MapReduce 的速度快10倍左右。
第二個優勢是對開發人員友好的 Spark API 。與 Spark 的加速一樣重要的是,人們可能會認為 Spark API 的友好性更為重要。
Spark Core
與 MapReduce 和其他 Apache Hadoop 組件相比,Apache Spark API 對開發人員非常友好,在簡單的方法調用后面隱藏了分布式處理引擎的大部分復雜性。其中一個典型的例子是幾乎要 50 行的 MapReduce 代碼來統計文檔中的單詞可以縮減到幾行 Apache Spark 實現(下面代碼是 Scala 中展示的):
- val textFile = sparkSession.sparkContext.textFile(“hdfs:///tmp/words”)
- val counts = textFile.flatMap(line => line.split(“ “))
- .map(word => (word, 1))
- .reduceByKey(_ + _)
- counts.saveAsTextFile(“hdfs:///tmp/words_agg”)
通過提供類似于 Python、R 等數據分析流行語言的綁定,以及更加對企業友好的 Java 和 Scala ,Apache Spark 允許應用程序開發人員和數據科學家以可訪問的方式利用其可擴展性和速度。
Spark RDD
Apache Spark 的核心是彈性分布式數據集(Resilient Distributed Dataset,RDD)的概念,這是一種編程抽象,表示一個可以在計算集群中分離的不可變對象集合。 RDD 上的操作也可以跨群集分割,并以批處理并行方式執行,從而實現快速和可擴展的并行處理。
RDD 可以通過簡單的文本文件、SQL 數據庫、NoSQL 存儲(如 Cassandra 和 MongoDB )、Amazon S3 存儲桶等等創建。Spark Core API 的大部分是構建于 RDD 概念之上,支持傳統的映射和縮減功能,還為連接數據集、過濾、采樣和聚合提供了內置的支持。
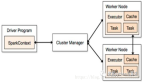
Spark 是通過結合驅動程序核心進程以分布式方式運行的,該進程將 Spark 應用程序分解成任務,并將其分發到完成任務的許多執行程序的進程中。這些執行程序可以根據應用程序的需要進行擴展和縮減。
Spark SQL
Spark SQL 最初被稱為 Shark,Spark SQL 對于 Apache Spark 項目開始變得越來越重要。它就像現在的開發人員在開發應用程序時常用的接口。Spark SQL 專注于結構化數據的處理,借用了 R 和 Python 的數據框架(在 Pandas 中)。不過顧名思義,Spark SQL 在查詢數據時還兼容了 SQL2003 的接口,將 Apache Spark 的強大功能帶給分析師和開發人員。
除了支持標準的 SQL 外,Spark SQL 還提供了一個標準接口來讀寫其他數據存儲,包括 JSON,HDFS,Apache Hive,JDBC,Apache Parquet,所有這些都是可以直接使用的。像其他流行的存儲工具 —— Apache Cassandra、MongoDB、Apache HBase 和一些其他的能夠從 Spark Packages 生態系統中提取出來單獨使用的連接器。
下邊這行簡單的代碼是從數據框架中選擇一些字段:
- citiesDF.select(“name”, “pop”)
要使用 SQL 接口,首先要將數據框架注冊成一個臨時表,之后我們就可以使用 SQL 語句進行查詢:
- citiesDF.createOrReplaceTempView(“cities”)
- spark.sql(“SELECT name, pop FROM cities”)
在后臺, Apache Spark 使用名為 Catalyst 的查詢優化器來檢查數據和查詢,以便為數據局部性和計算生成有效的查詢計劃,以便在集群中執行所需的計算。在 Apache Spark 2.x 版本中,Spark SQL 的數據框架和數據集的接口(本質上是一個可以在編譯時檢查正確性的數據框架類型,并在運行時利用內存并和計算優化)是推薦的開發方式。RDD 接口仍然可用,但只有無法在 Spark SQL 范例中封裝的情況下才推薦使用。
Spark MLib
Apache Spark 還有一個捆綁許多在大數據集上做數據分析和機器學習的算法的庫 (Spark MLib) 。Spark MLlib 包含一個框架用來創建機器學習管道和在任何結構化數據集上進行特征提取、選擇、變換。MLLib 提供了聚類和分類算法的分布式實現,如 k 均值聚類和隨機森林等可以在自定義管道間自由轉換的算法。數據科學家可以在 Apache Spark 中使用 R 或 Python 訓練模型,然后使用 MLLib 存儲模型,***在生產中將模型導入到基于 Java 或者 Scala 語言的管道中。
需要注意的是 Spark MLLib 只包含了基本的分類、回歸、聚類和過濾機器學習算法,并不包含深度學建模和訓練的工具(更多內容 InfoWorld’s Spark MLlib review )。提供深度學習管道的工作正在進行中。
Spark GraphX
Spark GraphX 提供了一系列用于處理圖形結構的分布式算法,包括 Google 的 PageRank 實現。這些算法使用 Spark Core 的 RDD 方法來建模數據;GraphFrames 包允許您對數據框執行圖形操作,包括利用 Catalyst 優化器進行圖形查詢。
Spark Streaming
Spark Streaming 是 Apache Spark 的一個新增功能,它幫助在需要實時或接近實時處理的環境中獲得牽引力。以前,Apache Hadoop 世界中的批處理和流處理是不同的東西。您可以為您的批處理需求編寫 MapReduce 代碼,并使用 Apache Storm 等實時流媒體要求。這顯然導致不同的代碼庫需要保持同步的應用程序域,盡管是基于完全不同的框架,需要不同的資源,并涉及不同的操作問題,以及運行它們。
Spark Streaming 將 Apache Spark 的批處理概念擴展為流,將流分解為連續的一系列微格式,然后使用 Apache Spark API 進行操作。通過這種方式,批處理和流操作中的代碼可以共享(大部分)相同的代碼,運行在同一個框架上,從而減少開發人員和操作員的開銷。每個人都能獲益。
對 Spark Streaming 方法的一個批評是,在需要對傳入數據進行低延遲響應的情況下,批量微操作可能無法與 Apache Storm,Apache Flink 和 Apache Apex 等其他支持流的框架的性能相匹配,所有這些都使用純粹的流媒體方法而不是批量微操作。
Structured Streaming
Structured Streaming(在 Spark 2.x 中新增的特性)是針對 Spark Streaming 的,就跟 Spark SQL 之于 Spark 核心 API 一樣:這是一個更高級別的 API,更易于編寫應用程序。在使用 Structure Streaming 的情況下,更高級別的 API 本質上允許開發人員創建***流式數據幀和數據集。它還解決了用戶在早期的框架中遇到的一些非常真實的痛點,尤其是在處理事件時間聚合和延遲傳遞消息方面。對 Structured Streaming 的所有查詢都通過 Catalyst 查詢優化器,甚至可以以交互方式運行,允許用戶對實時流數據執行 SQL 查詢。
Structured Streaming 在 Apache Spark 中仍然是一個相當新的部分,已經在 Spark 2.2 發行版中被標記為產品就緒狀態。但是,Structure Streaming 是平臺上流式傳輸應用程序的未來,因此如果你要構建新的流式傳輸應用程序,則應該使用 Structure Streaming。傳統的 Spark Streaming API 將繼續得到支持,但項目組建議將其移植到 Structure Streaming 上,因為新方法使得編寫和維護流式代碼更加容易。
Apache Spark 的下一步是什么?
盡管結構化數據流為 Spark Streaming 提供了高級改進,但它目前依賴于處理數據流的相同微量批處理方案。然而, Apache Spark 團隊正在努力為平臺帶來連續的流媒體處理,這應該能夠解決許多處理低延遲響應的問題(聲稱大約1ms,這將會非常令人印象深刻)。 更好的是,因為結構化流媒體是建立在 Spark SQL 引擎之上的,所以利用這種新的流媒體技術將不需要更改代碼。
除此之外,Apache Spark 還將通過 Deep Learning Pipelines 增加對深度學習的支持。 使用 MLlib 的現有管線結構,您將能夠在幾行代碼中構建分類器,并將自定義 Tensorflow 圖形或 Keras 模型應用于傳入數據。 這些圖表和模型甚至可以注冊為自定義的 Spark SQL UDF(用戶定義的函數),以便深度學習模型可以作為 SQL 語句的一部分應用于數據。
這些功能目前都無法滿足生產的需求,但鑒于我們之前在 Apache Spark 中看到的快速發展,他們應該會在2018年的黃金時段做好準備。