使用Apache Spark和MySQL打造強大的數據分析
借助真實案例和代碼樣本,本文作者展示了如何將Sparke和MySQL結合起來,創造數據分析上的強大工具。 Apache Spark是一個類似Apache Hadoop的集群計算框架,在Wikipedia上有大量描述:Apache Spark是一個開源集群計算框架,出自加州大學伯克利分校的AMPLab,后被捐贈給了Apache軟件基金會。 相對于Hadoop基于磁盤的兩段式MapReduce規范,Spark基于內存的多段式基元在特定應用上表現要優出100倍。Spark允許用戶程序將數據加載到集群內存中反復查詢,非常適合機器學習算法。 
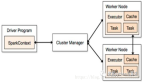
與流行的看法相反,Spark不需要將所有數據存入內存,但會使用緩存來加速操作(就像MySQL那樣)。Spark也能獨立運行而無需Hadoop,并可以運行在單獨一臺服務器上(甚至筆記本或臺式機上),并充分利用所有CPU內核。開啟它并使用分布式模式真的很簡單。先打開master,在同一個節點上運行slave:
然后在任何額外的節點上運行Spark worker(確定向/etc/hosts 添加了hostname或者使用DNS):
在很多任務中MySQL(開箱即用的)表現并不太好。MySQL的限制之一在于:1次查詢=1個CPU內核。也就是說,即便你有48個速度飛快的內核,外加一個大型數據集可用,也無法充分利用所有的計算能力,相反Spark卻能充分使用CPU內核。
MySQL與Spark的另一差異在于:
l MySQL使用所謂的“寫時模式(schema on write)”——需要將數據轉化到MySQL中,如果未包含在MySQL里,就無法使用sql來查詢。
l Spark(還有Hadoop/Hive)使用“讀時模式(schema on read)”——比如在一個壓縮txt文件頂部使用表格結構(或者其他支持的輸入格式),將其看作表格;然后我們可以用SQL來查詢這個“表格”。
也就是說,MySQL負責存儲+處理,而Spark只負責處理,并可直接貫通數據與外部數據集(Hadoop、Amazon S3,本地文件、JDBC MySQL或其他數據集)的通道。Spark支持txt文件(壓縮的)、SequenceFile、其他Hadoop輸入格式和Parquet列式存儲。相對Hadoop來說,Spark在這方面更為靈活:例如Spark可以直接從MySQL中讀取數據。
向MySQL加載外部數據的典型管道(pipeline)是:
1、 解壓縮(尤其是壓縮成txt文件的外部數據);
2、用“LOAD DATA INFILE”命令將其加載到MySQL的存儲表格中;
3、只有這樣,我們才能篩選/進行分組,并將結果保存到另一張表格中。
這會導致額外的開銷;在很多情況下,我們不需要“原始”數據,但仍需將其載入MySQL中。
相反,我們的分析結果(比如聚合數據)應當存在MySQL中。將分析結果存在MySQL中并非必要,不過更為方便。假設你想要分析一個大數據集(即每年的銷售額對比),需要使用表格或圖表的形式展現出來。由于會進行聚合,結果集將會小很多,將其存在MySQL中與很多標準程序一同協作處理將會容易許多。
一個有趣的免費數據集是Wikipedia的頁數(從2008年啟用后到現在,壓縮后大于1TB)。這個數據可以下載(壓縮空間確定txt文件),在AWS上也是可用的(有限數據集)。數據以小時聚合,包括以下字段:
l項目(比如en,fr等,通常是一種語言)
l頁頭(uri),采用urlencode編碼
l請求數
l返回內容的大小
(數據字段編譯到了文件名中,每小時1個文件)
我們的目標是:找出英文版wiki中每日請求數位居前10的頁面,不過還要支持對任意詞的搜索,方便闡釋分析原理。例如,將2008到2015年間關于“Myspace”和“Facebook”的文章請求數進行對比。使用MySQL的話,需要將其原封不動的載入MySQL。所有文件按內置的日期編碼分布。解壓的總大小大于10TB。下面是可選的步驟方案(典型的MySQL方式):
1、解壓文件并運行“LOAD DATA INFILE”命令,將其錄入臨時表格:
2、“插入到”最終的表格,進行聚合:
3、通過url解碼標題(可能用到UDF)。
開銷很大:解壓并將數據轉化為MySQL格式,絕大部分都會被丟棄,作為損耗。
根據我的統計,整理6年來的數據需耗時超過1個月,還不包括解壓時間,隨著表格逐漸變大、索引需要更新所帶來的加載時間折損。當然,有很多辦法可以加速這一過程,比如載入不同的MySQL實例、首先載入內存表格再集合成InnoDB等。
不過最簡單的辦法是使用Apache Spark和Python腳本(pyspark)。Pyspark可以讀出原始的壓縮txt文件,用SQL進行查詢,使用篩選、類似urldecode函數等,按日期分組,然后將結果集保存到MySQL中。
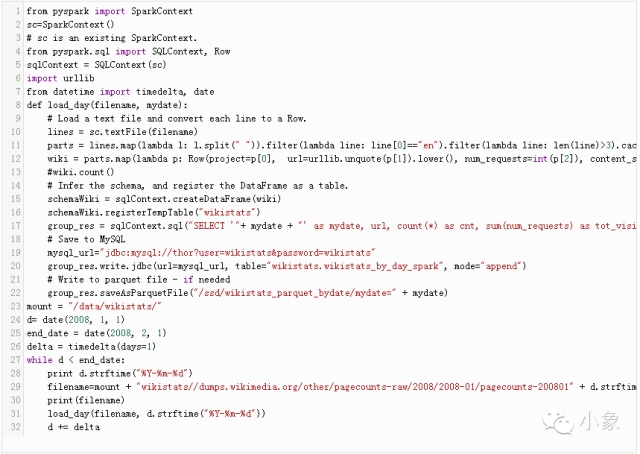
下面是執行操作的Python腳本:
在腳本中用到了Spark來讀取原始壓縮文件(每次一天)。我們可以使用目錄作為“輸入”或者文件列表。然后用彈性分布式數據集(RDD)轉化格式;Python包含lambda函數映射和篩選,允許我們將“輸入文件”分離并進行篩選。
下一步是應用模式(declare fields);我們還能使用其他函數,比如用urllib.unquote來解碼標題(urldecode)。最終,我們可以注冊臨時表格,然后使用熟悉的SQL來完成分組。
該腳本可以充分利用CPU內核。此外,即便不使用Hadoop,在分布式環境中運行也非常簡易:只要將文件復制到SparkNFS/外部存儲。
該腳本花了1個小時,使用了三個box,來處理一個月的數據,并將聚合數據加載到MySQL上(單一實例)。我們可以估出:加載全部6年的(聚合)數據到MySQL上需要大約3天左右。
你可能會問,為什么現在要快得多(而且實現了同樣的實例)。答案是:管道不同了,而且更為有效。在我們起初的MySQL管道中,載入的是原始數據,需要大約數月時間完成。而在本案例中,我們在讀取時篩選、分組,然后只將需要的內容寫入MySQL。
這里還有一個問題:我們真的需要整個“管道”嗎?是否可以簡單地在“原始”數據之上運行分析查詢?答案是:確實有可能,但是也許會需要1000個節點的Spark集群才能奏效,因為需要掃描的數據量高達5TB(參見下文中的“補充”)。
#p#
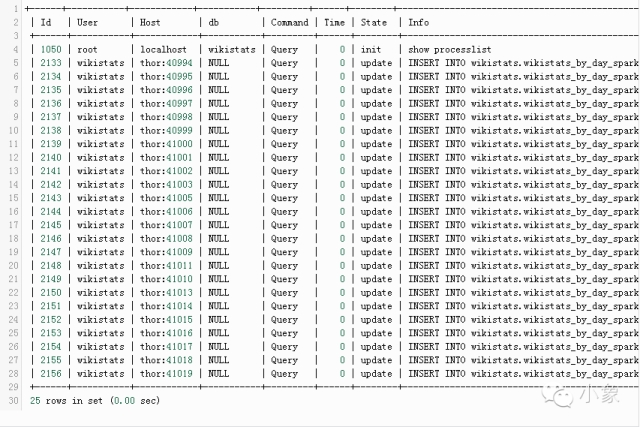
通過使用group_res.write.jdbc(url=mysql_url, table=”wikistats.wikistats_by_day_spark”, mode=”append”) ,Spark會啟動多線程插入。
Spark提供了web接口,方便對工作進行監控管理。樣例如下:運行wikistats.py application:
結果:使用Parquet分列格式與MySQL InnoDB表格
Spark支持Apache Parquet分列格式,因此我們可以將RDD存儲為parquet文件(存入HDFS時可以保存到目錄中):
![]()
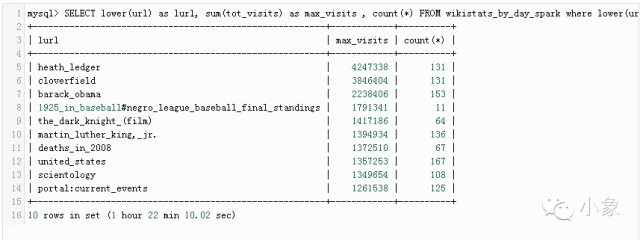
我們將管道結果(聚合數據)存入Spark。這次使用了按天分區(“mydate=20080101”),Spark可以在這種格式中自動發現分區。得到結果后要進行查詢。假設我們想要找到2018年1月查詢最頻繁的10大wiki頁面。可以用MySQL進行查詢(需要去掉主頁和搜索頁):

請注意,我們已經使用了聚合(數據匯總)表格,而不是“原始”數據。我們可以看到,查詢花了1小時22分鐘。由于將同樣的結果存入了Parquet(見腳本)中,現在可以在Spark-SQL中使用它了:
這將用到spark-sql的本地版本,而且只用到1個主機。
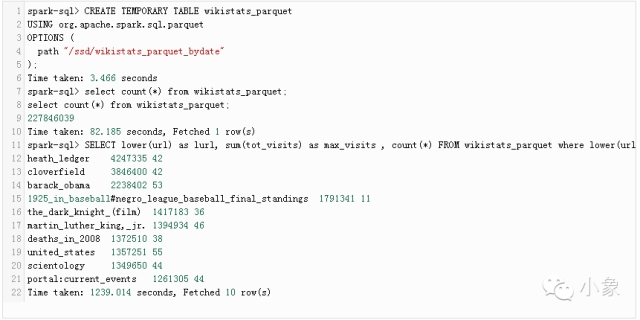
耗時大約20分鐘,比之前更快。
Apache Spark是分析和聚合數據的好辦法,而且非常簡便。我喜歡Spark與其他大數據還有分析框架的原因在于:
l開源與積極開發
l不依賴工具,例如輸入數據與輸出數據不一定非要借助Hadoop
l獨立模式,啟動迅速,易于部署
l大規模并行,易于添加節點
l支持多種輸入與輸出格式;比如可以讀取/寫入MySQL(Java數據庫連接驅動)與Parquet分列格式
但是,也有很多缺點:
l技術太新,會有一些bug和非法行為。很多錯誤難以解釋。
l需要Java;Spark 1.5僅支持Java 7及以上版本。這也意味著需要額外內存——合情合理。
l你需要通過“spark-submit”來運行任務。
我認為作為工具,Apache Spark十分不錯,補足了MySQL在數據分析與商業智能方面的短板。