解讀JavaScript之V8引擎及優化代碼的5個技巧
幾個星期前,我們開始了一系列旨在深入研究 JavaScript 及其實際工作方式的系列文章:我們認為通過了解 JavaScript 的構建塊以及它們如何一起協作的,你將能夠編寫更好的代碼和應用程序。
本系列的***篇文章重點介紹了引擎,運行時和調用堆棧的概述。第二篇文章將深入到 Google V8 JavaScript 引擎的內部。我們還將提供一些關于如何編寫更好的 JavaScript 代碼的快速技巧 - 我們的 SessionStack 開發團隊在構建產品時所遵循的***實踐。
概覽
JavaScript 引擎是執行 JavaScript 代碼的程序或解釋器。 JavaScript 引擎可以作為標準解釋器或即時編譯器,它以某種形式將 JavaScript 編譯為字節碼。
下面是一個實現了 JavaScript 引擎的流行項目列表:
- V8 — 開源,由 Google 開發,用 C ++ 編寫
- Rhino — 由 Mozilla 基金會管理,開源,完全用 Java 開發
- SpiderMonkey — 是***個支持 Netscape Navigator 的 JavaScript 引擎,目前正供 Firefox 使用
- JavaScriptCore — 開源,由蘋果公司為 Safari 開發
- KJS — KDE 的引擎,最初由 Harri Porten 為 KDE 項目中的 Konqueror 網頁瀏覽器開發
- Chakra (JScript9) — Internet Explorer
- Chakra (JavaScript) — Microsoft Edge
- Nashorn, 作為 OpenJDK 的一部分,由 Oracle Java 語言和工具組編寫
- JerryScript — 物聯網的輕量級引擎
為什么創建 V8 引擎?
由 Google 構建的 V8 引擎是開源的,用 C ++ 編寫。 此引擎被用在 Google Chrome 中。 與其他引擎不同的是,V8 也被用于流行的 Node.js 中。
V8 最初是被設計用來提高網頁瀏覽器內部 JavaScript 執行的性能。為了獲得更快的速度,V8 將 JavaScript 代碼翻譯成更高效的機器代碼,而不是使用解釋器來翻譯代碼。它通過使用 JIT(Just-In-Time)編譯器(如 SpiderMonkey 或 Rhino(Mozilla)等許多現代 JavaScript 引擎)來將 JavaScript 代碼編譯為機器代碼。 這里的主要區別在于 V8 不生成字節碼或任何中間代碼。
V8 曾有兩個編譯器
在 V8 的 5.9 版本出來之前(今年早些時候發布),引擎使用了兩個編譯器:
- full-codegen - 一個簡單而且速度非常快的編譯器,可以生成簡單且相對較慢的機器代碼。
- Crankshaft - 一種更復雜(Just-In-Time)的優化編譯器,生成高度優化的代碼。
V8 引擎也在內部使用多個線程:
- 主線程完成您期望的任務:獲取代碼,編譯并執行它
- 還有一個單獨的線程用于編譯,以便主線程可以繼續執行,而前者正在優化代碼
- 一個 Profiler 線程,它會告訴運行時我們花了很多時間,讓 Crankshaft 可以優化它們
- 一些線程處理垃圾收集器
當***次執行 JavaScript 代碼時,V8 利用 full-codegen 編譯器,直接將解析的 JavaScript 翻譯成機器代碼而不進行任何轉換。這使得它可以非常快速地開始執行機器代碼。請注意,V8 不使用中間字節碼,從而不需要解釋器。
當你的代碼運行了一段時間,分析器線程已經收集了足夠的數據來判斷哪個方法應該被優化。
接下來,Crankshaft 從另一個線程開始優化。它將 JavaScript 抽象語法樹轉換為被稱為 Hydrogen 的高級靜態單分配(SSA)表示,并嘗試優化 Hydrogen 圖。大多數優化都是在這個級別完成的。
內聯代碼
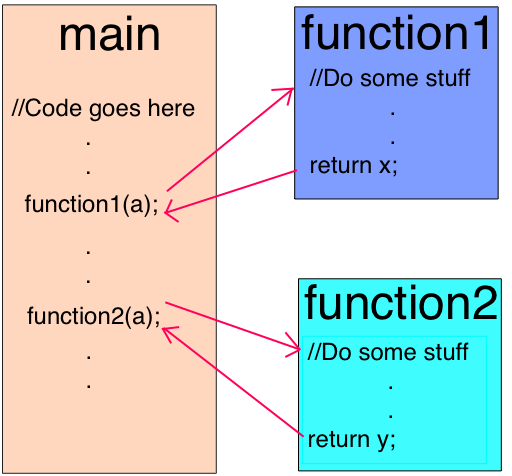
***個優化是提前盡可能多地內聯代碼。內聯是將被調用函數的主體替換為調用站點(調用函數的代碼行)的過程。這個簡單的步驟使得下面的優化更有意義。
隱藏類
JavaScript 是一種基于原型的語言:沒有類和對象而是使用克隆創建的。 JavaScript 也是一種動態編程語言,這意味著屬性可以在實例化后方便地添加或從對象中移除。
大多數 JavaScript 解釋器使用類似字典的結構(基于散列函數)來存儲對象屬性值在內存中的位置。這種結構使得在 JavaScript 中檢索一個屬性的值比在 Java 或 C# 這樣的非動態編程語言中的計算量要大得多。在 Java 中,所有的對象屬性都是在編譯之前由一個固定的對象決定的,并且不能在運行時動態添加或刪除(當然,C#的動態類型是另一個主題)。因此,屬性的值(或指向這些屬性的指針)可以作為連續的緩沖區存儲在內存中,每個值之間有一個固定的偏移量。偏移量的長度可以很容易地根據屬性類型來確定,而在運行時屬性類型可以改變的 JavaScript 中這是不可能的。
由于使用字典查找內存中對象屬性的位置效率非常低,因此 V8 使用了不同的方法:隱藏類。隱藏類與 Java 等語言中使用的固定對象(類)的工作方式類似,除了隱藏類是在運行時創建的這點區別。現在,讓我們看看他們實際的例子:
- function Point(x, y) {
- this.x = x;
- this.y = y;
- }
- var p1 = new Point(1, 2);
一旦 “new Point(1,2)” 調用發生,V8 將創建一個名為 “C0” 的隱藏類。

尚未為 Point 定義屬性,因此“C0”為空。
一旦***個語句 “this.x = x” 被執行(在 “Point” 函數內部),V8 將創建第二個隱藏的類,名為“C1”,它基于“C0”。 “C1”描述了可以找到屬性x的在內存中的位置(相對于對象指針)。在這種情況下,“x”被存儲在0處,這意味著當在內存中將點對象看作一段連續存儲空間時,***個地址將對應于屬性“x”。 V8 也會用“class transition”來更新“C0”,如果一個屬性“x”被添加到一個點對象時,隱藏類應該從“C0”切換到“C1”。下面的點對象的隱藏類現在是“C1”。

每當一個新的屬性被添加到一個對象時,舊的隱藏類將被更新為到新的隱藏類的轉換路徑。隱藏的類轉換非常重要,因為它們允許隱藏的類在以相同方式創建的對象之間共享。如果兩個對象共享一個隱藏類,并將相同的屬性添加到這兩個對象,則轉換將確保兩個對象接收相同的新隱藏類和所有優化代碼。
當語句 “this.y = y” 被執行時,會重復同樣的過程(在 “Point” 函數內部,“this.x = x”語句之后)。
一個名為“C2”的新隱藏類會被創建,如果將一個屬性 “y” 添加到一個 Point 對象(已經包含屬性“x”),一個類轉換會添加到“C1”,則隱藏類應該更改為“C2”,點對象的隱藏類更新為“C2”。

隱藏類轉換取決于將屬性添加到對象的順序。看看下面的代碼片段:
- function Point(x, y) {
- this.x = x;
- this.y = y;
- }
- var p1 = new Point(1, 2);
- p1.a = 5;
- p1.b = 6;
- var p2 = new Point(3, 4);
- p2.b = 7;
- p2.a = 8;
現在,假設對于p1和p2,將使用相同的隱藏類和轉換。那么,對于“p1”,首先添加屬性“a”,然后添加屬性“b”。然而,“p2”首先分配“b”,然后是“a”。因此,由于不同的轉換路徑,“p1”和“p2”以不同的隱藏類別結束。在這種情況下,以相同的順序初始化動態屬性好得多,以便隱藏的類可以被重用。
內聯緩存
V8 利用另一種被稱為內聯緩存的技術來優化動態類型語言。內聯緩存依賴于發生在相同類型的對象上的相同方法的重復調用的觀察上。內嵌緩存的更多解釋可以在這里找到。
接下來將討論內聯緩存的一般概念(如果您沒有時間通過上面的深入了解)。
它是怎樣工作的? V8 維護一個在最近的方法調用中作為參數傳遞的對象類型的緩存,并使用這些信息來預測將來作為參數傳遞的對象的類型。如果V8能夠很好地假定傳遞給方法的對象類型,那么它可以繞過如何訪問對象的屬性的過程,而是將之前查找到的信息用于對象的隱藏類。
那么隱藏類和內聯緩存的概念如何相關呢?無論何時在特定對象上調用方法時,V8 引擎都必須執行對該對象的隱藏類的查找,以確定訪問特定屬性的偏移量。在同一個隱藏類的兩次成功的調用之后,V8 省略了隱藏類的查找,并簡單地將該屬性的偏移量添加到對象指針本身。對于該方法的所有下一次調用,V8 引擎都假定隱藏的類沒有更改,并使用從以前的查找存儲的偏移量直接跳轉到特定屬性的內存地址。這大大提高了執行速度。
內聯緩存也是為什么相同類型的對象可以共享隱藏類非常重要的原因。如果你創建了兩個相同類型的對象和不同的隱藏類(就像我們之前的例子中那樣),V8 將不能使用內聯緩存,因為即使兩個對象是相同的類型,它們相應的隱藏類為其屬性分配不同的偏移量。

這兩個對象基本相同,但“a”和“b”屬性的創建順序不同。
編譯成機器碼
一旦 Hydrogen 圖被優化,Crankshaft 將其降低到稱為 Lithium 的較低級表示。大部分的 Lithium 實現都是特定于架構的。寄存器分配往往發生在這個級別。
***,Lithium 被編譯成機器碼。然后就是 OSR :on-stack replacement(堆棧替換)。在我們開始編譯和優化一個明確的長期運行的方法之前,我們可能會運行堆棧替換。 V8 不只是緩慢執行堆棧替換,并再次開始優化。相反,它會轉換我們擁有的所有上下文(堆棧,寄存器),以便在執行過程中切換到優化版本上。這是一個非常復雜的任務,考慮到除了其他優化之外,V8 最初還將代碼內聯。 V8 不是唯一能夠做到的引擎。
有一種叫做去優化的保護措施來做出相反的變換,并且在假設引擎優化無效的情況下,還原回非優化的代碼。
垃圾收集
對于垃圾收集,V8 采用了傳統的分代式掃描方式來清理老一代。標記階段應該停止 JavaScript 的執行。為了控制 GC 成本并使執行更加穩定,V8 使用了漸進式標記:而不是走遍整個堆內容,試圖標記每一個可能的對象。它只走一部分堆內容,然后恢復正常執行。下一個 GC 將從先前堆走過的地方繼續執行。這允許在正常執行期間非常短的暫停。如前所述,掃描階段由不同的線程處理。
Ignition 和 TurboFan
隨著 2017 年早些時候 V8 5.9 的發布,一個新的執行管道被引入。這個新的管道在實際的 JavaScript 應用程序中實現了更大的性能改進和顯著的內存節省。
新的執行流程是建立在 Ignition( V8 的解釋器)和 TurboFan( V8 的***優化編譯器)之上的。
你可以查看 V8 團隊關于這個話題的博客文章。
自從 V8 5.9 版本問世以來,由于 V8 團隊一直努力跟上新的 JavaScript 語言特性以及這些特性所需要的優化,V8 團隊已經不再使用 full-codegen 和 Crankshaft(自 2010 年以來為 V8 技術所服務)。
這意味著 V8 整體上將有更簡單和更易維護的架構。
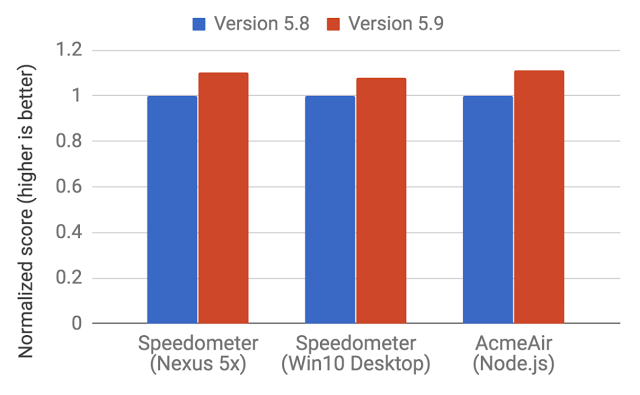
在 Web 和 Node.js 性能上的提升
這些改進僅僅是一個開始。新的 Ignition 和 TurboFan 管道為進一步的優化鋪平了道路,這將在未來幾年提高 JavaScript 性能,縮小 V8 在 Chrome 和 Node.js 中的占用空間。
***,這里有一些關于如何編寫優化的、更好的 JavaScript 的技巧。你可以很容易地從上面的內容中得到這些,不過,這里有一個為你提供便利的總結:
如何編寫優化的 JavaScript
- 對象屬性的順序:始終以相同的順序實例化對象屬性,以便共享的隱藏類和隨后優化的代碼可以共享之。
- 動態屬性:在實例化之后向對象添加屬性將強制執行隱藏的類更改,并降低之前隱藏類所優化的所有方法的執行速度。相反,在其構造函數中分配所有對象的屬性。
- 方法:重復執行相同方法的代碼將比僅執行一次的多個不同方法(由于內聯緩存)的代碼運行得更快。
- 數組:避免稀疏數組,其中鍵值不是自增的數字。并沒有存儲所有元素的稀疏數組是哈希表。這種數組中的元素訪問開銷較高。另外,盡量避免預分配大數組。***是按需增長。***,不要刪除數組中的元素。這會使鍵值變得稀疏。
- 標記值:V8 使用 32 位表示對象和數值。由于數值是 31 位的,它使用了一位來區分它是一個對象(flag = 1)還是一個稱為 SMI(SMall Integer)整數(flag = 0)。那么,如果一個數值大于 31 位,V8會將該數字裝箱,把它變成一個雙精度數,并創建一個新的對象來存放該數字。盡可能使用 31 位有符號數字,以避免對 JS 對象的高開銷的裝箱操作。
我們在 SessionStack 中試圖編寫高度優化的 JavaScript 代碼時遵循這些***實踐。 原因是,一旦將 SessionStack 集成到你的產品級的 Web 應用程序中,它就會開始記錄所有的東西:所有的 DOM 更改、用戶交互、JavaScript 異常、堆棧跟蹤、網絡請求失敗、調試消息等。
通過 SessionStack ,你可以以視頻的方式重現問題,并查看發生在用戶身上的所有事情。所有這些都必須在對你的網絡應用程序的性能沒有任何影響的情況下進行的。
這有一個免費的方案,所以你可以試試看。