IT運維 ≠“救火隊員”,別讓頻發的問題成為任性的“蛙兒子”
原創【51CTO.com原創稿件】2018 年魔都的第一場雪,比以往時候來的更大一些,我本想約上三五好友聚會賞雪,但是一個哥們卻遲遲未到。
經打聽得知:他們公司的實時收/付賬系統突然在庫中出現了大面積的報表亂碼和被鎖的現象,他們運維部的電話不但被打爆,而且受波及的用戶直接找上門來,要求從備份中恢復急需的報表。
這些也導致了他們團隊完全無法靜下心來冷靜地處理問題,并按步驟恢復。大家聽聞后,除了報以關切的“呵呵”,居然還有人在此基礎上提出了“問題與養蛙理論”。
他振振有詞地說:我們應對運維中的各類問題,實際上就和養旅行青蛙類似。我們必須對它們負責,關注其“成長”與“發展”。
同時,不能讓那些問題像蛙兒子那樣與我們缺少“交互”、甚至“任性”失控,從而我們完全無法 get 到它們身處何方、所處何態。你看,這腦洞開得也是沒誰了。
眾所周知,我們的系統也有著它自身的生命周期:從初出茅廬、到風華正茂、直至“芳華”不再,它出現的問題數量和復雜程度都會呈現V型曲線的趨勢。
因此我們要及時應對,否則積累太多的話,就會像今年的這波流感病毒那樣,迅速蔓延開來,到時候周董就真的只能來“等你下課”了。
話題聊到這里,想必大家已經猜出了我們本次的主題了。對,就讓我們來具體看看如何在不同的層面上對各類出現的問題進行全程管控吧。
概念層面上:認知有“灰度”,才能對癥下藥
很多企業只有事件管理的概念,而沒有問題管理的意識。為了統一認識,我們首先來理解三個基本概念:事件、事故和問題。
事件(Event)
一般是指某種 IT 服務或是被監控項到達了門限值,而引發的警告;或者是伴隨著某項操作所觸發的通知等。
比如說:存儲剩余空間小于已設定的百分比數值、對某個賬號的權限變更、或是用戶組的成員調整等。
事故(Incident)
事故指計劃外的 IT 服務中斷,或是服務質量的驟降。
例如:由于專線出現問題、某個分部失去了與總部的網絡連接;或是某用戶利用企業內網觀看在線視頻,而拖慢了整體的內、外網訪問速度。
事故也包括一些尚未產生影響的監控項異常。比如:在做了 RAID 鏡像的互備磁盤上,有一個出現了故障,但整體所提供的服務尚未中斷。
通常情況下,對于處理人員來說,能夠快速找到那些雖“能治標不治本”的事故處理方法,可能會比花更多的時間去研究癥結,更容易被用戶所接受和認可。
由此可見對于事故的管理,我們主要是以止損、抑制不良影響和快速恢復為目的。
問題(Problem)
如果說處理事故是利用應急措施,去盡快地恢復 IT 服務的話,那么解決問題則是通過查找根源,預防中斷的再次發生,以及對那些實在無法避免的問題,盡量控制其影響的程度,它往往是一個耗時比較長的過程。
例如:軟件開發部門協同運維部門一起,對其所發布的產品中代碼的漏洞和不正確的配置進行安全加固,以消除攻擊隱患等。
由此可見對于問題的管理,我們主要是通過跟蹤那些顯著故障、分析根本原因,在根除的基礎上防止同類問題在整個系統中的復發。
準備層面上:手中有糧,方能心中不慌
通過上述的理論基礎,大家應該能夠明白問題管理的利害關系了吧?為了避免在碰到問題時像開篇的那個哥們那樣被動挨打、手足無措,我們就應當未雨綢繆,甚至要有“磨刀不誤砍柴功”的精神來提前準備。
下面咱們來了解一下企業需要具備哪些先決條件。
建立統一的受理入口
一站式服務,無問西東
很多企業對內配備了 Help desk,負責響應與處理自身用戶的各種 IT 問題;而對外則設置了 Call center,能夠應答和受理外部客戶的各類技術疑問。
因此,我們可以將其作為統一的受理入口,收集第一手的問題導入,同時也不放過任何一個問題的最初細節狀態。
配有自動的工具平臺
巧婦難為無米之炊
無論是自行研發也好,還是選型添置也罷,企業都需要擁有一套工具平臺來實現問題的錄入和分揀。
這個平臺的特點是:
- 對于需要錄入的各種問題,應盡可能以“菜單選擇”的方式來豐富問題的相關屬性項,并且要有基本的默認值。
這樣設計的好處在于:既方便了對問題提交者進行“提問式思路”的引導,又利于系統在后臺使用“已知錯誤知識庫(Known Errors Database,KEDB)”進行自動地匹配、分揀和過濾。
- 從系統的投資回報率(ROI)角度來看:越容易操作提交,就越方便被頻繁使用。
根據我的過往使用經驗,對于那些僅需要三、五步點選和輸入操作,就能完成提交的工具,提交者最樂于去使用。他們在體驗到高效和便捷的同時滿意度也很高。
- 自動為每一個問題提交分配一個工單號(ticket),并能夠自動設置計時、倒計時、郵件告知等功能,以方便跟蹤與評估。
擁有豐富的知識庫
我注六經,還是六經注我
許多企業都已經擁有了配置管理數據庫(ConfigurationManagement Database,CMDB)。
但是從問題管理的準備層面上說,我們要能夠對CMDB予以用“活”,也就是說:要讓上述的錄入平臺能夠訪問到它,并且實現對相關記錄信息進行自動且精準地查找、定位和匹配。
當有了與 CMDB 的流暢“聯動”,我們在整個問題處理的生命周期中,就能夠輕松獲取到豐富的背景支持信息,這樣管理起來也更得心應手。
流程層面上:做一次流程并不難,難的是一直都這么遵循
我曾聽過一句非常經典的管理言論:“沒有流程,就沒有執行力。”的確,面對各種出現的問題,縱然前期準備得再充分,如果沒有正確的人、在正確的階段、做正確的處理,就很容易造成整個團隊乃至服務形象的“人設崩塌”。
做過日常運維的小伙伴可能會有這樣的體會:我們不但對于突發的問題要有規范的處置流程;對于各種計劃的服務發布和業務變更,也要提前設計好應對各類“失敗”的應急流程,以防范于未然。
下圖是一個問題管理的通用流程,讓我們來逐一進行分解和梳理:
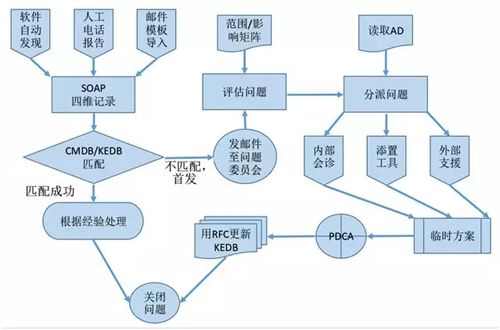
記錄問題(事無巨細,明察秋毫)
輸入:各種事件、事故和問題的產生,一般由自動和人工兩種途徑所產生。
即:由監控軟件自動發現,并主動推送到受理平臺上;Help desk 根據接報在平臺的管理界面輸入生成。
當然也可以由用戶通過既定的郵件模板向指定地址發送電子郵件的形式,自動捕獲關鍵字段來產生。
記錄:Help desk 如實且詳細地記錄問題的“癥狀”。
他們通過從 SOAP(Statement Observation Analysis Process,陳述-觀察-分析-處理)四個維度出發,留下他們的初步診斷和處理日志。
我在這里分享一個經驗:應盡可能在 SOAP 里使用受影響“配置項(Configuration Item,CI)”的規范名稱和錯誤代碼等方面的信息。
這對于我們下面要談到的事后查找與借鑒是十分有用的。因為問題描述可能因人而異,但這些特征字段較為通用也容易定位。
匹配問題(不要重復造輪子)
匹配:根據我們在前期準備階段所“打通”的 CMDB 和 KEDB,運用關鍵字的匹配,來判斷所提交的問題是首次發生,還是可以匹配到曾經發生過的、已知問題的記錄。
如果能夠定位到相似的記錄,則直接根據過往經驗記錄著手處理,并最終關閉該問題。倘若是首發,則對其進行屬性分類,以方便流轉到下一步。
輸出:在提交的 24 小時內,自動生成郵件,以通知問題管理委員會成員。
評估問題(找到“任督二脈”)
每一個問題在被錄入到系統中的時候,我們應事先定義并設置好各種影響范圍和緊急程度等選項,而問題管理委員會在收到郵件后,根據該問題日志記錄和經驗做出二次判斷與評估。
同時,他們可以利用類似如下的矩陣,對所影響到的范圍,和對業務與服務的影響程度,進行確認或修正。
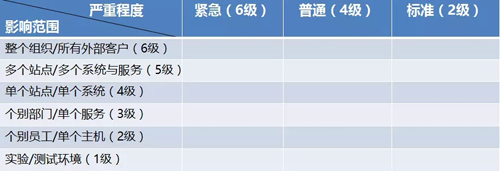
他們通過橫向與縱向的焦點區域來評定問題的優先級,并根據運維部門的實際處理能力進行區別對待。
分派問題(找對“師傅”很重要)
根據上述的問題分類和優先級,問題管理委員會著手識別、并指派問題的處理人員。
這里再給大家分享一些我的點滴經驗:
- 通過讀取系統目錄(AD)里 IT 角色和組的信息,方便處理人員所屬的部門能夠直接被對應到問題的本身分類屬性上。必要時,各部門通過聯動進行“會診”處理。
- 如果被分派到的處理人不在,或是無法勝任,則升級到他對應的技術團隊。
- 如果超出本企業內部現有的處理能力,則添置相應的專業技術與工具,或應及時轉呈外部資源,以尋求援助。
- 在平臺上,預先設置的分類越有條理、越豐富,就越能節約處理人員定位和他們熟悉問題的時間。
解決驗證(用工匠精神去深耕)
處理人員或團隊針對被分派的問題開展調查研究,并且每 24 小時更新一次工作日志。
在著手解決的過程中,我們應注意如下幾點:
- 鑒于“聊勝于無”的佛系思想,如果能預計到分析的耗時較長的話,處理人員應當及時給出臨時解決方案,保證服務的“降速”提供。
- 在找到了最終辦法之后,處理人員需在模擬環境中進行充分的測試,并制定出回滾(Roll back)的方案。大家還記得那個“魔性”的 PDCA(Plan-Do-Check-Act)嗎?此處仍然適用。
- 俗話說:唯一不變的是變更。要解決問題,就難免需要對原來的系統或服務進行修改。
為了避免發生各種未遇見到的次生問題,處理人員應嚴格遵循既定的變更管理流程,準備并提交一份變更請求(Request for Change,RFC)。
具體的內容大家可以參考一下《【廉環話】從OWASP Top 10的安全配置缺失說起》(http://zhuanlan.51cto.com/art/201708/547356.htm)。
- 千萬記得要把驗證有效的問題解決方案更新到我們上面提及的 KEDB 之中。
管理層面上:事后不總結,難道還留著過年嗎?
在問題解決后,大家先別慌張開香檳,此時應該開展的是“過秦論”。
具體說來,應該由問題管理委員會牽頭進行如下事后工作:
- 對問題的處理效果進行評審,重點是偏離 SLA 的部分(如超時等)及其原因,并提出改進方案。
- 提出問題復發與根除的整改措施與方案。
- 通過郵件的形式向受到問題影響的用戶發放調查問卷和滿意度。
- 每月匯總各類問題的詳細報表,舉行例會對問題進行歸類和趨勢分析。
- 每半年或一年對現有問題的處理流程進行回顧,涉及到的內容包括:流程的關鍵衡量指標、執行效率,驗證工具的有效性等。
結語
您一定聽說過那個適用范圍頗廣的“二八理論”吧?在這里,它也可以體現為:80% 的 IT 服務中斷,來自于 20% 的累計問題。
由此可見,為了防止各種問題對系統和服務的“秋后算賬”,我們不能停留在“黑暗球場”上,而是要通過不斷地關心“蛙兒子”們的“成長”,持續修正與改進,才能通過自建生態圈,將各種問題“圈定”在可控且可管理的范圍之內。
陳峻(Julian Chen) ,有著十多年的 IT 項目、企業運維和風險管控的從業經驗,日常工作深入系統安全各個環節。作為 CISSP 證書持有者,他在各專業雜志上發表了《IT運維的“六脈神劍”》、《律師事務所IT服務管理》 和《股票交易網絡系統中的安全設計》等論文。他還持續分享并更新《廉環話》系列博文和各種外文技術翻譯,曾被(ISC)2 評為第九屆亞太區信息安全領袖成就表彰計劃的“信息安全踐行者”和 Future-S 中國 IT 治理和管理的 2015 年度踐行人物。

【51CTO原創稿件,合作站點轉載請注明原文作者和出處為51CTO.com】