













自動解題批改與自適應學習 AI在教育行業的應用實踐
原創【51CTO.com原創稿件】近幾年人工智能風靡,諸多大中小企業紛紛布局,對于創業公司來說,想要有所建樹,深耕垂直細分領域才是關鍵。因為這里有大量的行業背景知識,即使巨頭投入巨資也需要先摸清行業情況,這個過程往往需要一年或更多,這就為創業公司贏得了大量的時間機會。對于這一類的情況,巨頭可能更傾向于收購或注資,而不是自建團隊。
三年來,學霸君在教育行業積累很多行業知識,尤其在校內業務方面,對學校的情況非常熟悉。同時,因校內業務的需求,學霸君一直非常注重人工智能相關技術的研發。通用人工智能技術非常難做,但與垂直行業場景結合起來,降低算法的難度,使得算法找到用武之地。在這個過程中,踩了很多坑,也收貨了豐富的實踐經驗。本文將介紹學霸君在校內業務所的幾大應用:結構化題庫建設、自動解題與知識圖譜、作業自動批改、自適應學習。
【結構化題庫建設】
結構化題目格式
題庫是教育公司的核心之一,市面上絕大部分題庫,題目的數據都是一段簡單的字符串。為了真實還原題目的結構,學霸君選擇使用json來描述題目的結構,一道題由很多零件根據一定的規則組合而成。
如下圖所展示的選擇題,由題干描述部分和選項部分組成,選項分成4個,題干上有填空的位置,有每一個公式的位置標記。用json結構來記錄題目結構,可以把大題拆成小題,可以精準定位每一個填空的位置,等等。這樣的題庫可以給產品設計提供更多更靈活的使用條件。

這種數據結構給題目的應用帶來了好處,但也增加了題庫生產的成本,因為題目的錄入環節需要對題目做結構拆分與關聯。為了降低成本,學霸君采用大量的圖像識別算法。
如下流程圖是一個簡化的題目錄入流程,從圖中可以看到,很多關鍵環節都相應地使用了識別算法來提高效率。
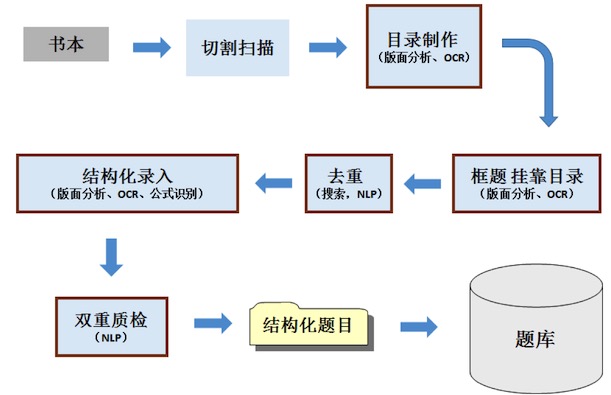
例如,在結構化錄入環節,我們使用了版面分析、OCR、公式識別等算法,所有題目都會經過算法先識別出一個初步的結果,錄入人員人工審核結果,如果正確就直接跳過,有錯誤就局部修改,這樣可以大大提高錄入人員的效率。目前題庫生產系統,對于任意一本教輔書,可以做到一天內完成所有題目的結構化加工生產到入庫,如果沒有系統和算法的支持,這幾乎是不可能的。
LaTex存儲公式
除了題目結構問題之外,理科題目的公式也是一個重要點。因為公式的結構和排版比較復雜,所以很多題庫都采用了截圖的方式存儲公式,這種方法丟失了公式的內容信息,并且存在圖像縮放影響美觀的問題。
學霸君采用LaTex存儲公式的方案,LaTex是一種通用的排版規范,可以適用于各種排版的場景。我們針對K12中出現的所有公式和符號,制定了一套基于LaTex的展示標準,基于這套標準,優化了MathJax開源工具,使得web端JS渲染的質量和效果都達到理想要求。
除了JS渲染工具,學霸君還開發了基于C語言內核的LaTex渲染工具,進一步封裝成安卓和iOS版本SDK。它的原理是解析LaTex文本并轉義成SVG矢量圖,然后再交給web頁面來渲染成最終結果。C語言內核的SDK的渲染速度比JS快幾倍,特別適用于學校大規模使用的低端PAD。

采用LaTex來存儲公式,就需要在錄入題目的時候把題目錄成LaTex格式,這個人工成本很大,尤其需要算法的幫助。
以往公式識別的算法,都是先通過一些圖像處理的手段,把公式切割成單個字符,然后分別識別每一個字符,最后再通過二維空間的結構關系,把字符組合成公式。這一類算法有很多局限性,字符有粘連的情況無法很好處理,基于空間結構的組合隨著深度增加,計算復雜度程幾何數量級增長,加上字符有可能有識別錯誤,導致無法從海量候選列表中找到正確的結果。
學霸君使用了端到端的識別方法,避免了以上所有問題,輸入是一個整體的圖像,輸出就是基于LaTex結構的公式的識別結果。算法的神經網絡結構是CNN(卷積網絡)+BLSTM(雙向長短記憶模型)+CTC(時序分類)。
為了訓練模型,學霸君在學校采集了大量的學生手寫公式數據,并標注為LaTex結構。這種網絡模型目前也有局限性,對于十分復雜的公式也是無法識別準確的,對于格式過于復雜的公式,我們通過空間結構關系將其拆分為若干個簡單的公式,然后分別使用端到端的手段來識別,最后組合在一起。
【自動解題與知識圖譜】
除了結構化格式外,學霸君還希望題庫的每一道題都能說清楚用到了什么知識點,甚至希望知道解題過程的每一個步驟都用到哪些知識點。如果每一題每一個步驟都由人來標記知識點,是無法完成的,希望通過算法代替人工來實現,這就用到了自動解題技術。自動解題大體分為三個步驟:理解、推導和表達,整體流程如下圖所示。
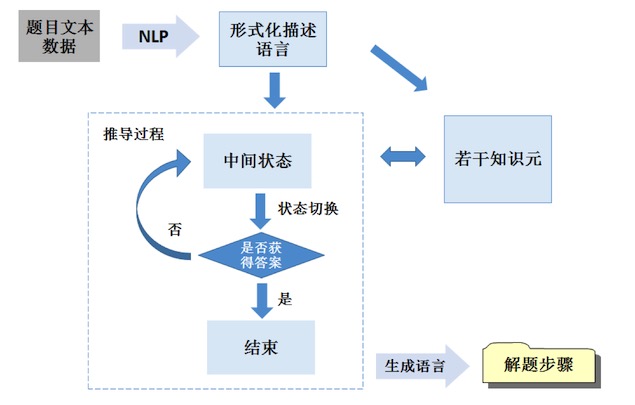
理解題干的語義
首先理解題干的語義,將題干內容從自然語言翻譯成形式化的語言,也就是NLP的過程。開放的語義理解是科研界的難題,至今也距離實用甚遠。但在中學理科體系里,語言的表達往往十分規范,這就大大降低了NLP的難度。
更重要的是,在開放的語義理解場景,是無法定義評判標準的,缺少客觀標準,會給訓練帶來巨大難度。但在中學理科體系里,很容易定義對錯,結合大量的數據,可以訓練出比較理想的模型。
題目中經常會遇到公式,前文提到我們題庫中的題目公式都是統一定義和規范的LaTex格式的,這就保證了機器可以準確地識別公式內容。
解題步驟的推理過程
接下來是解題步驟的推理過程。需要根據當前所有條件,獲取所需要的知識元信息。知識元是我們定義的最小細分的知識點,一個知識元是該知識點的定義和特征的總和,例如一個圓可以作為一個知識元,它有直徑、半徑、周長、面積等屬性,當我們知道它的直徑,可以進而計算出它的半徑、周長和面積。簡單理解,一個知識元就是一個小知識點。
將當前所有條件綜合到一起,當做初始狀態。根據當前所有知識元的特性可以進行步驟推導,獲得新的條件,進而狀態不斷變化。每一次推導都有很多種可能性,哪種推導最優由模型根據題干的問題來決定。
每次狀態切換后,比對一下是否獲得最終答案,如果獲得答案則推導過程結束。推導過程和知識元是密切相關的,同時中間狀態發生的條件變化,也會引入新的知識元。
表達過程
最后是表達過程,也就是將推導的過程翻譯成標準解題步驟,同時從幾個不同維度輸出關鍵信息。例如,每一個推導的步驟都會標記上所使用的知識點;在所有的步驟中,根據該題所有知識元的情況,找到幾個最重要的步驟作為關鍵步驟;綜合該題的所有知識元,概括出本題考察的教研層面的知識點(教研知識點是從老師角度觀察的知識點,與解題算法中的知識元不是一個維度)。
解題技術封裝成高考機器人
為了實戰驗證自動解題技術的效果,將解題技術封裝成高考機器人,在2017年6月高考當天,我們的高考機器人和廣大學生一起參加了高考,在高中數學取得了134分的成績,這是人工智能技術落地在教育行業的一個重要突破,引起了包括央視在內的各大媒體的關注和報道。
知識圖譜
有了自動解題技術,我們就可以給所有題目標注知識點。教研老師與技術同學一起制定一套覆蓋所有知識點的四級知識體系,知識點之間有層級關系,也有依賴或關聯關系,呈一個網狀結構。
這個知識體系與我們的題庫可以通過自動解題技術關聯起來,形成一個知識圖譜。在這個知識圖譜中,每一題都可以關聯到若干個知識點,每一個知識點也可以關聯到若干個題目。有了知識圖譜,系統就可以自動為每次學生作業和考試生成學習報告,從知識點的各個維度剖析學生的掌握情況。
【作業自動批改】
點陣數碼筆
在學校的調研中,學霸君發現老師批改作業的負擔十分繁重,希望通過系統來幫助老師批改作業,解放老師的時間和精力。如果實現系統批改作業呢?
首先需要收集到學生的手寫作業數據,我們通過點陣數碼筆來實現。點陣數碼筆需要在普通紙張上印刷一層幾乎不可見的點陣圖案,數碼筆前端的高速攝像頭隨時捕捉筆尖的運動軌跡,同時結合壓力傳感器將數據收集到處理器,通過編碼翻譯將點陣圖像翻譯為筆跡的坐標位置,最終將筆跡信息通過藍牙傳輸到PAD上。
如下圖所示,學生使用點陣數碼筆做作業或考試,不改變在紙上寫字的傳統習慣,同時可以實時將筆跡數據電子化。
手寫識別
獲取到學生手寫數據后,先通過版面圖像處理技術將手寫數據拆解成文本行,然后通過聯機手寫識別技術來識別出每一行的文字。
聯機手寫識別同樣用到CNN(卷積網絡)+BLSTM(雙向長短記憶模型)+CTC(時序分類)的模型,但具體的實現與前面的公式識別場景不一樣,特別是CNN的輸入圖像序列部分,學霸君采用了華南理工大學金教授論文里的Path-signature特征作為CNN的輸入特征圖序列。
對于復雜排版公式,同樣先拆分成簡單文本行,識別后再組合起來。采用學生的真實手寫數據來訓練,實踐證明,真實場景數據比我們雇傭人力來寫的效果要明顯好。
自動批改
只識別出學生手寫筆跡,還無法完成自動批改,因為標準答案是有很多種變形的,同一個標準答案,不同的表達方式可能都是正確的,例如圖上的這個例子。一個答案往往是有十幾種變形的,這背后需要有大量的教研基礎知識,系統識別出標準答案后,通過數學符號語言處理等算法,自動生成所有的同義表達式。將學生筆跡的最終答案,與標準答案的所有同義表達式進行匹配比較,找到結果一致的表達式。匹配的過程還需要考慮到,學生筆跡的最終答案有可能有一些冗余文字。
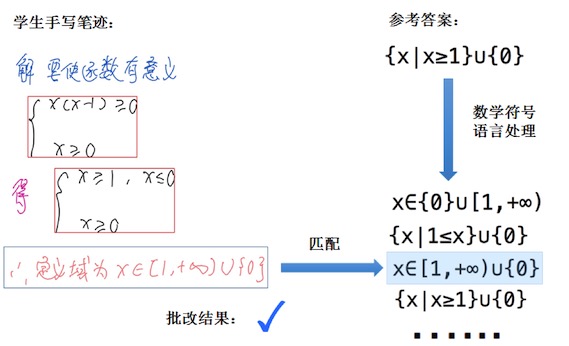
對于解答題,還希望能根據步驟來批改,想做到這一點是非常困難,學霸君采用關鍵步驟匹配的折中方案。通過自動解題技術,可以獲得解題過程的關鍵步驟,為了提高批改準確率,只選擇少量關鍵步驟,將關鍵步驟與學生的解題步驟進行匹配。最終題目的得分由關鍵步驟的分數和答案的分數加和而得。
【自適應學習】
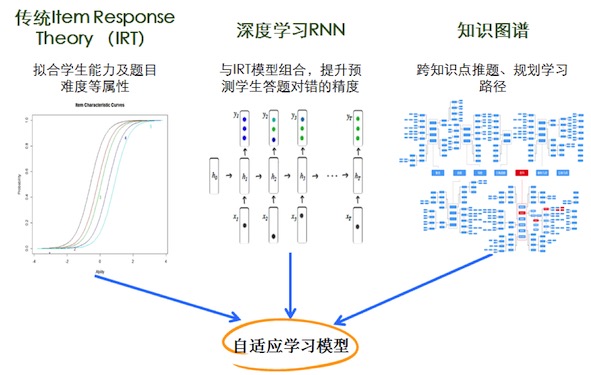
隨著學生持續使用學霸君的題庫做題(作業、考試等),系統可以持續收集到學生的學習行為數據,有了這些數據就可以做到自適應學習,也就是個性化學習。這里用到IRT的傳統模型,IRT理論即項目反應理論(Item Response Theory),又稱題目反應理論,是一系列心理統計學模型的總稱。IRT是用來分析考試成績或者問卷調查數據的數學模型,目前廣泛應用在心理和教育測量領域。
通過IRT模型,結合大量學生做題數據,可以分析出每一道題目的難度以及學生的能力,結合知識圖譜體系,進一步分析出學生在每個知識點的能力情況,也就是學生的知識點能力模型。有了這個模型,對于任何一道新題目,可以預測出學生做對這道題的概率,這樣,就可以給學生推薦難度適中適合他的題目,太簡單或太難的題就沒必要浪費時間了。
對于行為數據豐富的地區和學科知識模塊,可以直接用RNN模型來訓練,輸入的是學生的做題序列特征數據,輸出的是每一題的正確與否的預測。當數據量較大并且比較均勻的時候,RNN模型的效果才會相對理想。隨著用戶行為數據的不斷收集,以及用戶對產品的越來越規范的使用,相信RNN模型是未來的方向。
【結語】
以上是學霸君將人工智能算法與教育行業結合的一些探索,一些算法看起來比較難,但在垂直場景下使用得當,與工程項目深度融合,是可以獲得比較理想的效果的。學霸君始終認為,人工智能在創業公司里的落地,離不開與業務場景的深度融合。我們的算法工程師不僅可以寫代碼,也能做卷子參加考試,只有這樣才能保持特有的競爭力,在行業內有所突破。
【苗廣藝簡介】
苗廣藝,中科院碩士研究生,先后就職于搜狐、YY、奇虎360。現擔任學霸君技術副總裁,負責人工智能相關算法的研發推進,以及基礎技術在業務場景的落地實施。帶領團隊在國內率先研發出適應手機拍照各種復雜場景的文字識別算法,為學霸君題庫與教研體系搭建基礎數據結構和算法服務,并將其應用于各條業務線,同時帶領Ai學智慧教育平臺技術團隊研發了自動批改、自適應學習等多項前沿技術,為Ai學業務奠定了技術基礎。
更多AI內容,請關注公眾號:AI推手

【51CTO原創稿件,合作站點轉載請注明原文作者和出處為51CTO.com】





















