我爬取豆瓣影評,告訴你《復仇者聯盟3》在講什么?(內附源碼)
《復仇者聯盟3:***戰爭》于 2018 年 5 月 11 日在中國大陸上映。截止 5 月 16 日,它累計票房達到 15.25 億。這票房紀錄已經超過了漫威系列單部電影的票房紀錄。不得不說,漫威電影已經成為一種文化潮流。
先貼海報欣賞下:

復聯 3 作為漫威 10 年一劍的收官之作。漫威確認下了很多功夫, 給我們奉獻一部精彩絕倫的電影。自己也利用周末時間去電影院觀看。看完之后,個人覺得無論在打斗特效方面還是故事情節,都是給人愉悅的享受。同時,電影還保持以往幽默搞笑的風格,經常能把觀眾逗得捧腹大笑。如果還沒有去觀看的朋友,可以去電影院看看,確實值得一看。
本文通過 Python 制作網絡爬蟲,爬取豆瓣電影評論,并分析然后制作豆瓣影評的云圖。
1 分析
先通過影評網頁確定爬取的內容。我要爬取的是用戶名,是否看過,五星評論值,評論時間,有用數以及評論內容。
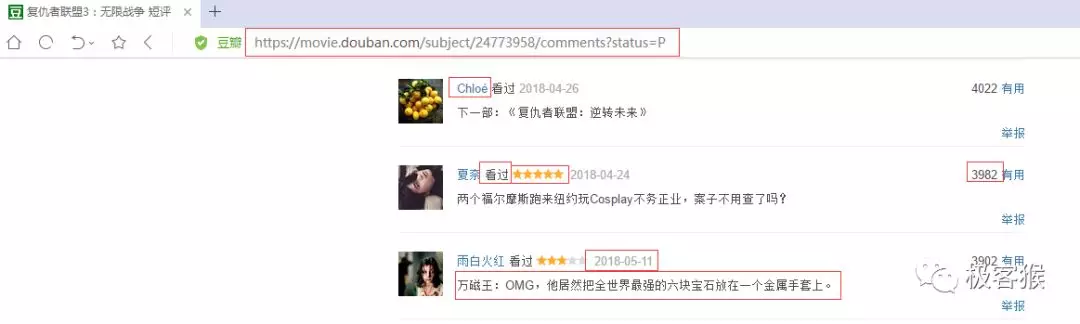
然后確定每頁評論的 url 結構。
第二頁 url 地址:

第三頁 url 地址:

***發現其中的規律:除了首頁,后面的每頁 url 地址中只有 start= 的值逐頁遞增,其他都是不變的。
2 數據爬取
本文爬取數據,采用的主要是 requests 庫和 lxml 庫中 Xpath。豆瓣網站雖然對網絡爬蟲算是很友好,但是還是有反爬蟲機制。如果你沒有設置延遲,一下子發起大量請求,會被封 IP 的。另外,如果沒有登錄豆瓣,只能訪問前 10 頁的影片。因此,發起爬取數據的 HTTP 請求要帶上自己賬號的 cookie。搞到 cookie 也不是難事,可以通過瀏覽器登錄豆瓣,然后在開發者模式中獲取。
我想從影評首頁開始爬取,爬取入口是:https://movie.douban.com/subject/24773958/comments?status=P,然后依次獲取頁面中下一頁的 url 地址以及需要爬取的內容,接著繼續訪問下一個頁面的地址。
- import jieba
- import requests
- import pandas as pd
- import time
- import random
- from lxml import etree
- def start_spider():
- base_url = 'https://movie.douban.com/subject/24773958/comments'
- start_url = base_url + '?start=0'
- number = 1
- html = request_get(start_url)
- while html.status_code == 200:
- # 獲取下一頁的 url
- selector = etree.HTML(html.text)
- nextpage = selector.xpath("//div[@id='paginator']/a[@class='next']/@href")
- nextpage = nextpage[0]
- next_url = base_url + nextpage
- # 獲取評論
- comments = selector.xpath("//div[@class='comment']")
- marvelthree = []
- for each in comments:
- marvelthree.append(get_comments(each))
- data = pd.DataFrame(marvelthree)
- # 寫入csv文件,'a+'是追加模式
- try:
- if number == 1:
- csv_headers = ['用戶', '是否看過', '五星評分', '評論時間', '有用數', '評論內容']
- data.to_csv('./Marvel3_yingpping.csv', header=csv_headers, index=False, mode='a+', encoding='utf-8')
- else:
- data.to_csv('./Marvel3_yingpping.csv', header=False, index=False, mode='a+', encoding='utf-8')
- except UnicodeEncodeError:
- print("編碼錯誤, 該數據無法寫到文件中, 直接忽略該數據")
- data = []
- html = request_get(next_url)
我在請求頭中增加隨機變化的 User-agent, 增加 cookie。***增加請求的隨機等待時間,防止請求過猛被封 IP。
- def request_get(url):
- '''
- 使用 Session 能夠跨請求保持某些參數。
- 它也會在同一個 Session 實例發出的所有請求之間保持 cookie
- '''
- timeout = 3
- UserAgent_List = [
- "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36",
- "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.1 Safari/537.36",
- "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.0 Safari/537.36",
- "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.0 Safari/537.36",
- "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2226.0 Safari/537.36",
- "Mozilla/5.0 (Windows NT 6.4; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2225.0 Safari/537.36",
- "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2225.0 Safari/537.36",
- "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2224.3 Safari/537.36",
- "Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.93 Safari/537.36",
- "Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.93 Safari/537.36",
- "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2049.0 Safari/537.36",
- "Mozilla/5.0 (Windows NT 4.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2049.0 Safari/537.36",
- "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1985.67 Safari/537.36",
- "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1985.67 Safari/537.36",
- "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.3319.102 Safari/537.36",
- "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.2309.372 Safari/537.36",
- "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.2117.157 Safari/537.36",
- "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.47 Safari/537.36",
- "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1866.237 Safari/537.36",
- ]
- header = {
- 'User-agent': random.choice(UserAgent_List),
- 'Host': 'movie.douban.com',
- 'Referer': 'https://movie.douban.com/subject/24773958/?from=showing',
- }
- session = requests.Session()
- cookie = {
- 'cookie': "你的 cookie 值",
- }
- time.sleep(random.randint(5, 15))
- response = requests.get(url, headers=header, cookies=cookie_nologin, timeout = 3)
- if response.status_code != 200:
- print(response.status_code)
- return response
***一步就是數據獲取:
- def get_comments(eachComment):
- commentlist = []
- user = eachComment.xpath("./h3/span[@class='comment-info']/a/text()")[0] # 用戶
- watched = eachComment.xpath("./h3/span[@class='comment-info']/span[1]/text()")[0] # 是否看過
- rating = eachComment.xpath("./h3/span[@class='comment-info']/span[2]/@title") # 五星評分
- if len(rating) > 0:
- rating = rating[0]
- comment_time = eachComment.xpath("./h3/span[@class='comment-info']/span[3]/@title") # 評論時間
- if len(comment_time) > 0:
- comment_time = comment_time[0]
- else:
- # 有些評論是沒有五星評分, 需賦空值
- comment_time = rating
- rating = ''
- votes = eachComment.xpath("./h3/span[@class='comment-vote']/span/text()")[0] # "有用"數
- content = eachComment.xpath("./p/text()")[0] # 評論內容
- commentlist.append(user)
- commentlist.append(watched)
- commentlist.append(rating)
- commentlist.append(comment_time)
- commentlist.append(votes)
- commentlist.append(content.strip())
- # print(list)
- return commentlist
3 制作云圖
因為爬取出來評論數據都是一大串字符串,所以需要對每個句子進行分詞,然后統計每個詞語出現的評論。我采用 jieba 庫來進行分詞,制作云圖,我則是將分詞后的數據丟給網站 worditout 處理。
- def split_word():
- with codecs.open('Marvel3_yingpping.csv', 'r', 'utf-8') as csvfile:
- reader = csv.reader(csvfile)
- content_list = []
- for row in reader:
- try:
- content_list.append(row[5])
- except IndexError:
- pass
- content = ''.join(content_list)
- seg_list = jieba.cut(content, cut_all=False)
- result = '\n'.join(seg_list)
- print(result)
***制作出來的云圖效果是:

"滅霸"詞語出現頻率***,其實這一點不意外。因為復聯 3 整部電影的故事情節大概是,滅霸在宇宙各個星球上收集 6 顆***寶石,然后每個超級英雄為了防止滅霸毀滅整個宇宙,組隊來阻止滅霸。