人工智能單從耳部圖像分辨年齡和性別準確率驚人
深度學習圖像處理簡介:耳生物識別已成為一個熱門的研究課題[1]。最近的一個挑戰,被稱為無約束耳朵識別挑戰[2],顯示了從野外的耳朵圖像進行人物識別的困難。為了補充來自耳部圖像的身份相關信息,利用軟生物特征(如年齡和性別信息)可能是輔助手段。為此,本文中,我們廣泛調查了耳部圖像中年齡和性別分類的任務。
預計生物識別特征不會隨時間變化很大,容易獲得并且對每個個體都是獨特的[3]。由于其幾個特征,耳朵是生物識別研究和法醫科學鑒定的重要模式。例如,與受面部表情,面部毛發或化妝的變化影響的面部外觀相比,耳部外觀相對恒定。耳廓也是面部特征[4]。在耳部中,耳垂是法醫案件中使用最頻繁的部分。它是耳朵唯一持續增長和改變形狀的部分[5]。在安全攝像頭拍攝的圖像中,耳朵在整個或部分覆蓋的臉部仍可以看到,并可用作識別的輔助信息。此外,當在配置文件中查看臉部時,可以從錄像或照片中輕松捕捉耳朵[6]。
盡管在人耳識別中使用人耳圖像已有很多研究[1],[6],但從耳部圖像中提取軟生物特征(如年齡和性別)的研究數量有限。據我們所知,這項研究是從耳朵圖像的年齡分類的***項工作。然而,以前有關耳朵圖像用于性別分類的一些工作。在[7]中,耳孔被用作測量的參考點。計算從掩蓋的耳朵圖像中識別的耳孔與耳朵的七個特征之間的歐幾里德距離。他們使用一個內部數據庫,其中有342個樣本用于實驗。他們采用了貝葉斯分類器,KNN分類器和神經網絡。 KNN實現了***性能,分類精度為90.42%。
在[8]中,配置文件的人臉圖像和人耳圖像分開使用,并通過支持向量機(SVM)與直方圖相交核進行分類。他們基于貝葉斯分析進行分數級融合以提高準確性。 UND生物特征數據集集合F [11]的2D圖像已被用于實驗。融合導致97.65%的準確性,而面對只有性能約為95.43%,耳朵只有精確度為91.78%左右。在文獻[9]中,Gabor濾波器已經被用來提取特征,并且已經利用基于字典學習的提取特征來執行分類。該字典是根據訓練樣本構建的,并用于測試階段,將測試樣本表示為訓練數據的線性組合。 UND生物統計數據集J [11],其中包含大的外觀,姿態和光照變化,已用于實驗。通過使用128個功能,報告中獲得的***準確度為89.49%。在[10]中,性別分類在2D和3D耳朵圖像上執行。 3D耳朵會自動檢測并對齊。實驗是在UND數據集集合F和J2上進行的[11]。索引形狀的直方圖特征通過SVM提取和分類。系統的平均性能為92.94%。
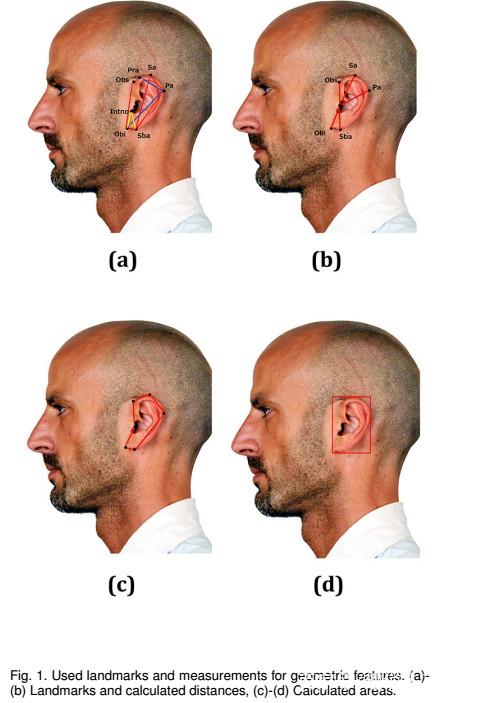
在本文中,我們對耳朵圖像的年齡和性別分類進行了廣泛的分析。我們已經探索了使用幾何特征和基于外觀的特征來表示耳朵。幾何特征基于在耳朵上確定的八個地標。從這些地標中提取特征,我們計算了它們之間的14個不同距離以及執行了兩個面積計算。為了對這些提取的特征進行分類,已經采用了四種不同的分類器 - 回歸分析,隨機森林,支持向量機,神經網絡。
基于外觀的方法基于眾所周知的深度卷積神經網絡(CNN)模型,即AlexNet [12],VGG-16 [13],GoogLeNet [14]和SqueezeNet [15]。他們已經進行了兩次微調,首先是在大規模的耳朵數據集中提供領域適應,然后在小規模的目標耳朵數據集上進行。在實驗中,基于外觀的方法的性能優于基于幾何特征的方法。我們在性別分類方面的準確率達到了94%,超過了之前研究中達到的準確率。對于年齡分類,已經獲得52%的準確性。總之,論文的貢獻可以列舉如下:
•我們已經探索了基于幾何和外觀的耳部圖像年齡和性別分類特征。
•對于幾何特征,我們在耳朵上使用了8個地標點,并從中得出了16個特征。
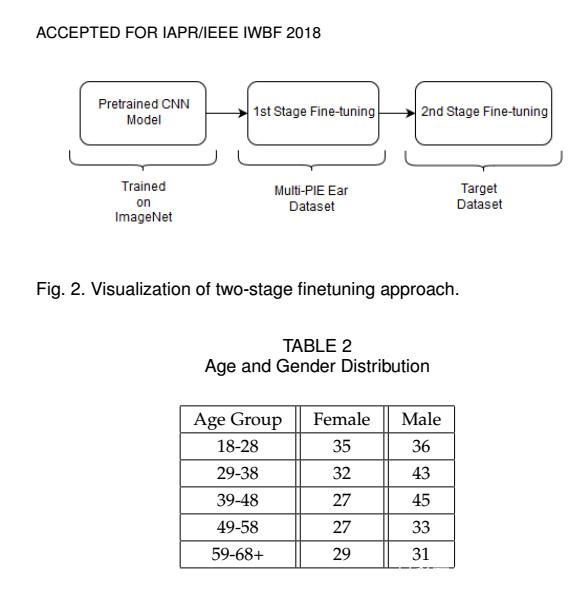
•對于基于外觀的方法,我們已經使用了一個大規模的ear數據集[16],該數據集是根據Multi-PIE人臉數據集中的輪廓和貼近人臉的人臉圖像構建的[17]。通過這種方式,我們已經有效地從知名的CNN模型中轉移并從中受益,解決了手頭的問題。
•與以前的工作相比,我們在性別分類方面取得了出色的表現。我們從耳朵圖像中提出了***部關于年齡分類的工作。

深度學習前沿算法Gender分類結果:性別分類結果列于表4中。在表中,***列包括分類器的名稱,第二列包含相應的分類準確度。為了提醒讀者使用的功能,功能的類型包含在第二列的括號內。從表中可以看出,基于外觀的方法優于利用幾何特征的分類器。考慮到正確的性別分類的機會水平是50%,使用幾何特征獲得的結果非常差。這種劣勢表現的一個主要原因可能是已經應用于幾何特征的標準化步驟。在規范化過程中 - 制作特征具有零均值和單位差異 - 有關性別的區分信息可能已經丟失。因此,規范化的影響需要進一步分析。基于外觀的方法已經實現了大約90%的準確性。使用GoogLeNet架構獲得***性能[14],分類正確率為94%。這種準確性超過了先前對耳朵圖像中性別分類研究所取得的性別分類準確性[7],[8],[9],[10]。表5給出了這些方法的比較。總的來說,根據以前的研究結果,我們發現耳朵圖像提供了有用的信息來分類主題的性別。
深度學習前沿算法年齡分類結果:年齡分類結果列于表6中。***列包括分類器的名稱,第二列包含相應的分類準確度。為了提醒讀者使用的功能,功能的類型包含在第二列的括號內。基于幾何特征的方法和基于外觀的方法之間的這種性能差距非常接近。但是,基于外觀的方法已經被發現再次優越。使用幾何特征,通過3個隱藏層神經網絡和邏輯回歸實現***性能,準確度達到43%。使用GoogLeNet體系結構的基于外觀的方法[14]獲得了***性能,其分類正確率為52%。與性別分類所取得的成績相比,年齡分類準確性相對較低。這一結果的一個可能原因是每個年齡組的樣本數量有限。由于年齡分類的班級數量較高,因此每班的樣本量較少。我們計劃擴展數據集并進一步分析結果。由于基于幾何特征的方法和基于外觀的方法獲得的精度非常接近,所以結合這兩種方法可能是另一種提高性能的方法。總體而言,外觀提供了更多的信息與地理特征相比,因此,已被發現更有用的年齡和性別分類。
深度學習前沿算法結論:在本文中,我們對耳朵圖像的年齡和性別分類進行了深入的研究。據我們所知,這項研究是***部關于耳朵圖像年齡分類的研究,也是為數不多的利用耳朵圖像進行性別分類的研究之一。在研究中,我們采用幾何特征和基于外觀的特征來表示耳朵。幾何特征是針對耳朵上的八個人體測量地標進行計算的,包括14個距離測量和兩個面積計算。然后用四種不同的方法對這些特征進行分類:邏輯回歸,隨機森林,支持向量機和神經網絡。基于外觀的方法基于深度卷積神經網絡。眾所周知的CNN模型,即AlexNet [12],VGG-16 [13],GoogLeNet [14]和SqueezeNet [15]已被采納用于研究。
為了有效地將它們轉移到手頭的任務上,他們首先在一個大規模的耳朵數據集上進行了微調,這個數據集是根據配置文件和Multi-PIE人臉數據集中可用的貼近人臉的人臉圖像構建的[17] 。之后,更新后的模型再次在小尺度目標耳數據集上進行了微調。作為實驗的結果,基于外觀的方法已經被發現優于基于幾何特征的方法。我們的性別分類準確性達到了94%,而年齡分類準確率達到了52%。這些結果表明耳朵圖像為年齡和性別分類提供了有用的線索。但是,使用幾何特征的性別分類需要進一步的工作已經注意到,對于性別分類,幾何特征對歸一化是敏感的。因此,必須探索更好的標準化方案。對于年齡估計,我們認為造成性能下降的主要原因是缺乏每個年齡組的足夠數量的訓練樣本。我們計劃擴展數據集并訓練年齡分類系統,并提供更多的樣本。我們還旨在通過對常用數據集進行實驗進行比較,如UND-F和UND-J2 [11]。此外,我們還計劃研究幾何和基于外觀的特征之間的互補性。此外,我們計劃將年齡和性別分類的側面人臉圖像和耳朵圖像結合起來。